Ошибка синтаксического анализа файла XML с помощью InputStreamReader. Неожиданный тип: (позиция END_DOCUMENT пустая)
Все, я новичок в Android, и я пытаюсь разобрать файл XML и получить информацию в списке. Мой XML-файл - это то, что я хочу получить объекты.
Что я делаю, чтобы разобрать это что-то похожее на пример на сайте Android Developres:
import android.content.Context;
import android.util.Xml;
import android.widget.Toast;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
/**
* Created by Álvaro on 31/08/2015.
*/
public class EntrelazadasXMLParser {
// We don't use namespaces
private static final String ns = null;
public List parse(InputStream in, Context context) throws /*XmlPullParserException,*/ IOException {
try {
XmlPullParser parser = Xml.newPullParser();
parser.setFeature(XmlPullParser.FEATURE_PROCESS_NAMESPACES, false);
parser.setInput(in, null);
parser.nextTag();
return readFeed(parser,context);
}catch (XmlPullParserException e){
Toast.makeText(context, "Error en el parser: " + e.toString(),
Toast.LENGTH_LONG).show();
return null;
}
finally {
in.close();
}
}
....
Эта функция предназначена для создания экземпляра синтаксического анализатора и запуска процесса синтаксического анализа. Синтаксический анализатор инициализируется без пространств имен и использует предоставленный InputStream в качестве входных данных. Он запускает процесс синтаксического анализа с помощью вызова nextTag() и вызывает метод readFeed(), который извлекает и обрабатывает данные, в которых заинтересовано приложение. где происходит исключение и ошибка следующая.
Error en el parser: org.xmlpull.v1.XmlPullParserException: unexpected type (position:END_DOCUMENT null@1:1 in java.io.InputStreamReader@41e3d220).
Остальная часть этого класса это:
vate List readFeed(XmlPullParser parser, Context context) throws /*XmlPullParserException,*/ IOException {
List entries = new ArrayList();
try {
parser.require(XmlPullParser.START_TAG, ns, "database");
while (parser.next() != XmlPullParser.END_TAG) {
if (parser.getEventType() != XmlPullParser.START_TAG) {
continue;
}
String name = parser.getName();
// Starts by looking for the table tag
if (name.equals("table")) {
entries.add(readEntry(parser));
} else {
skip(parser);
}
}
return entries;
}
catch (XmlPullParserException e){
Toast.makeText(context, "Error en el read feed: " + e.toString(),
Toast.LENGTH_LONG).show();
return null;
}
}
private void skip(XmlPullParser parser) throws XmlPullParserException, IOException {
if (parser.getEventType() != XmlPullParser.START_TAG) {
throw new IllegalStateException();
}
int depth = 1;
while (depth != 0) {
switch (parser.next()) {
case XmlPullParser.END_TAG:
depth--;
break;
case XmlPullParser.START_TAG:
depth++;
break;
}
}
}
private Producto readEntry(XmlPullParser parser) throws XmlPullParserException, IOException {
parser.require(XmlPullParser.START_TAG, ns, "table");
Producto Objeto =null;
String summary = null;
String link = null;
while (parser.next() != XmlPullParser.END_TAG) {
if (parser.getEventType() != XmlPullParser.START_TAG) {
continue;
}
String name = parser.getName();
if (name.equals("column")) {
Objeto = readColumn(parser);
} else {
skip(parser);
}
}
return Objeto;
}
private Producto readColumn(XmlPullParser parser) throws IOException, XmlPullParserException {
Producto Objeto ;
String Id = null;;
String Referencia = null;;
String Nombre = null;;
String Categoria = null;;
String SubFamilia = null;;
String Familia = null;;
String Descripcion = null;;
String Precio = null;;
String Image1 = null;
String Image2 = null;
String Image3 = null;
String Image4 = null;
String Image5 = null;
parser.require(XmlPullParser.START_TAG, ns, "column");
String tag = parser.getName();
String relType = parser.getAttributeValue(null, "name");
if (relType.equals("Id")){
Id = readId(parser);
} else if(relType.equals("Precio")){
Precio = readPrecio(parser);
}else if(relType.equals("Referencia")){
Referencia = readReferencia(parser);
}else if(relType.equals("Categoria")){
Categoria = readCategoria(parser);
}else if(relType.equals("Nombre")){
Nombre = readNombre(parser);
}else if(relType.equals("Subfamilia")){
SubFamilia = readSubfamilia(parser);
}else if(relType.equals("Familia")){
Familia = readFamilia(parser);
}else if(relType.equals("Descripcion")){
Descripcion = readDescripcion(parser);
}else{
Image1 = readImage(parser);
}
Objeto =new Producto(Id,Referencia,Nombre,Categoria,SubFamilia,Familia,Descripcion,Precio,Image1,Image2,Image3,Image4,Image5);
parser.require(XmlPullParser.END_TAG, ns, "column");
return Objeto;
}
// Processes Id tags in the feed.
private String readId (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readPrecio (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readReferencia (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readCategoria (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readNombre (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readSubfamilia (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readFamilia (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readDescripcion (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readImage (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
// For the tags title and summary, extracts their text values.
private String readText(XmlPullParser parser) throws IOException, XmlPullParserException {
String result = "";
if (parser.next() == XmlPullParser.TEXT) {
result = parser.getText();
parser.nextTag();
}
return result;
}
}
И вызов парсера и объявление inputStream:
EntrelazadasXMLParser XmlParser = new EntrelazadasXMLParser();
List<Producto> entries = null;
String root = Environment.getExternalStorageDirectory().toString();
File SDCardRoot = new File(root + "/Entrelazadas");
try {
InputStream raw = new FileInputStream(new File(SDCardRoot, "catalogo.xml"));
//FileInputStream fileInputStream = new FileInputStream(file);
entries = XmlParser.parse(raw,context);
}
catch (FileNotFoundException e){
Toast.makeText(context, "Fichero no encontrado: " +e.toString(),
Toast.LENGTH_LONG).show();
}
catch (IOException e){
Toast.makeText(context, "Error de IO: " +e.toString(),
Toast.LENGTH_LONG).show();
}
Я надеюсь, что любой из вас сможет мне помочь. Большое спасибо.
Вот как файл появляется в самых первых строках:
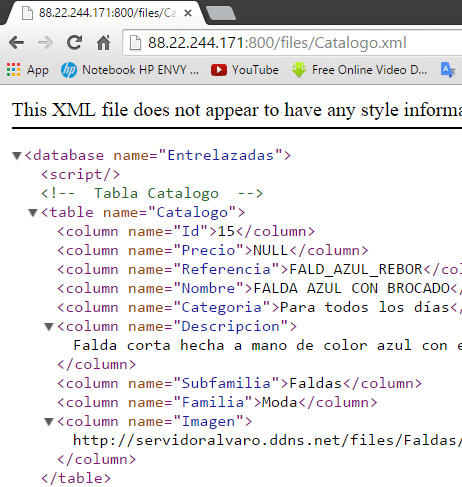
2 ответа
Наконец, проблема была в файле, который был пустым из-за того, что в другой части кода была строка, которая стирала этот файл.
Повторяйте цикл while до конца документа, как это
private void eBooksXmlParser(String xmlData, контекстный контекст) { XmlPullParserFactory pullParserFactory; ArrayList eBooks = null; try { pullParserFactory = XmlPullParserFactory.newInstance(); XmlPullParser parser = pullParserFactory.newPullParser();
parser.setFeature(XmlPullParser.FEATURE_PROCESS_NAMESPACES, false);
parser.setInput(new StringReader(xmlData));
int eventType = parser.getEventType();
EBook currentEBook = null;
while (eventType != XmlPullParser.END_DOCUMENT) {
String tagName;
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
break;
case XmlPullParser.START_TAG:
tagName = parser.getName();
if (tagName.equals("wr"))
eBooks = new ArrayList<>();
else if (eBooks != null) {
if (tagName.equals("book")) {
currentEBook = new EBook();
currentEBook.setBookName(parser.getAttributeValue(0));
currentEBook.setCategory(parser.getAttributeValue(1));
currentEBook.setDescription(parser.getAttributeValue(2));
currentEBook.setFileName(parser.getAttributeValue(3));
currentEBook.setFormat(parser.getAttributeValue(4));
currentEBook.setFromDate(parser.getAttributeValue(5));
currentEBook.setSubCategory(parser.getAttributeValue(6));
currentEBook.setThumbnail(parser.getAttributeValue(7));
currentEBook.setTier(parser.getAttributeValue(8));
currentEBook.setToDate(parser.getAttributeValue(9));
currentEBook.setType(parser.getAttributeValue(10));
currentEBook.setDownloadStatus(false);
}
}
break;
case XmlPullParser.END_TAG:
tagName = parser.getName();
if (tagName.equalsIgnoreCase("book")
&& currentEBook != null) {
eBooks.add(currentEBook);
currentEBook = null;
}
}
eventType = parser.next();
}
} catch (XmlPullParserException | IOException e) {
e.printStackTrace();
}
if (eBooks != null)
UserDbProvider.getInstance(context).addEBooksList(
eBooks);
}