Переименовать столбец в сгруппированном столбце по значению строки (dplyr)
Как я могу переименовать столбец в сгруппированном столбце dplyr, в зависимости от определенного значения строки? На следующем рисунке показано, как выглядит мой столик до и как он должен выглядеть после манипуляции.
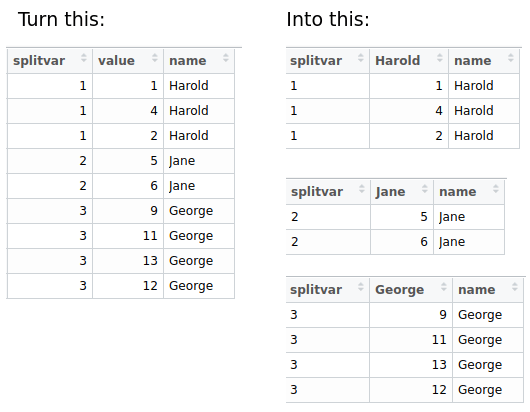
Я пробовал следующий код, но мне не удалось написать функцию переименования столбца, которая может гибко указывать имя нового столбца из столбца "имя".
library(dplyr)
df <- data.frame(
"splitvar"=c(1,1,1,2,2,3,3,3,3),
"value"=c(1,4,2,5,6,9,11,13,12),
"name"=c("Harold","Harold","Harold","Jane","Jane","George","George","George","George"),
stringsAsFactors=F
)
grouped_tbl <- df %>%
group_by( splitvar ) %>%
eval(parse(
paste0("rename(",unique(name)," = value)")
))
Связанный: замена для "переименования" в dplyr
2 ответа
Как это:
library(tidyverse)
df %>%
split(.$splitvar) %>%
map(~rename(., !!unique(.$name) := "value"))
Мне потребовалось некоторое время, чтобы разобраться в этом вопросе, но попробуйте взглянуть на программирование с помощью dplyr
Вывод кода:
$`1`
splitvar Harold name
1 1 1 Harold
2 1 4 Harold
3 1 2 Harold
$`2`
splitvar Jane name
4 2 5 Jane
5 2 6 Jane
$`3`
splitvar George name
6 3 9 George
7 3 11 George
8 3 13 George
9 3 12 George
Вы можете разбить на части, сделать новые столбцы и связать вместе.
Вот вариант через nest/unnest (тидир) и map (мурлыкать)
library(tidyr)
library(purrr)
я использую rename_at как альтернатива тидыевал.
df %>%
group_by(splitvar) %>%
nest() %>%
mutate(data = map(data, function(x) rename_at(x, "value", funs( unique(x$name) ) ) ) ) %>%
unnest()
# A tibble: 9 x 5
splitvar Harold name Jane George
<dbl> <dbl> <chr> <dbl> <dbl>
1 1 1 Harold NA NA
2 1 4 Harold NA NA
3 1 2 Harold NA NA
4 2 NA Jane 5 NA
5 2 NA Jane 6 NA
6 3 NA George NA 9
7 3 NA George NA 11
8 3 NA George NA 13
9 3 NA George NA 12
Это может быть проблема "перестройки", которую я делаю через Tidyr. Это не держит name колонка, хотя.
df %>%
group_by(splitvar) %>%
mutate(row = row_number() ) %>%
spread(name, value)
# A tibble: 9 x 5
# Groups: splitvar [3]
splitvar row George Harold Jane
* <dbl> <int> <dbl> <dbl> <dbl>
1 1 1 NA 1 NA
2 1 2 NA 4 NA
3 1 3 NA 2 NA
4 2 1 NA NA 5
5 2 2 NA NA 6
6 3 1 9 NA NA
7 3 2 11 NA NA
8 3 3 13 NA NA
9 3 4 12 NA NA