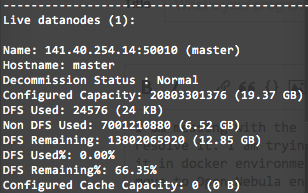
Кластер Hadoop, показывающий только 1 живую датододу
Я пытаюсь настроить 3-х узловый кластер Apache Hadoop. Я уже делал это в среде докеров, и там все работало нормально. Сейчас я пытаюсь перейти в среду открытой туманности. У меня есть 3 виртуальные машины с Ubuntu и Hadoop. Когда я запускаю hadoop с помощью./sbin/start-dfs.sh, Hadoop открывает датоды на всех подчиненных устройствах, и до этого момента все выглядит хорошо. Но если я использую "./bin/hdfs dfsadmin -report", он покажет мне только 1 живой узел данных. Проверьте следующее
Вот результат команды JPS на моем мастере:
Команда JPS на подчиненном устройстве:

Я также могу SSH все машины. Я предполагаю, что что-то не так с моим файлом хоста, потому что мои ведомые не смогли связаться с мастером. Вот мой мастер / etc / hosts.
<my_ip_1> master
<my_ip_2> slave-1
<my_ip_3> slave-2
127.0.0.1 localhost
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
Я не изменил свой файл / etc / hostname, но он выглядит следующим образом. где "my_ip_1" представляет текущий IP-адрес виртуальной машины.
<my_ip_1>.cloud.<domain>.de
Далее, если я запускаю пример hadoop PI с помощью команды
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar pi 100 10000000
Я получаю следующую ошибку в файле журнала slave-1 и slave-2. Но главный узел решает проблему PI самостоятельно.
2015-08-25 15:27:03,249 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/<my_ip_1>:54310. Already tried 10 time(s); maxRetries=45
2015-08-25 15:27:23,270 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/<my_ip_1>:54310. Already tried 11 time(s); maxRetries=45
2015-08-25 15:27:43,290 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/<my_ip_1>:54310. Already tried 12 time(s); maxRetries=45
Я уже попробовал: http://www.quora.com/The-master-node-shows-only-one-live-data-node-when-I-am-running-multi-node-cluster-in-Hadoop-What-should-I-do
1 ответ
Хорошо, я сумел выяснить проблему и нашел решение.
Проблема:
Мои подчиненные узлы не связывались с мастером. Итак, я проверил настройки брандмауэра на моих машинах (Ubuntu) с помощью следующей команды
sudo ufw status verbose
Вывод команды
Status: active
Logging: on (low)
Default: deny (incoming), allow (outgoing), disabled (routed)
New profiles: skip
Решение:
Итак, мои машины отклоняли любые входящие запросы. Итак, я отключил свой брандмауэр, чтобы проверить предположение.
sudo ufw disable
Перед отключением брандмауэра, telnet <my_ip_1> 54310 давал мне тайм-аут соединения. Но после отключения брандмауэра все заработало нормально. Затем я отключил брандмауэр на всех машинах и снова запустил пример PI из цикла oop. Это сработало.
Затем я включил брандмауэр на всех машинах
sudo ufw enable
И я добавил некоторые правила брандмауэра для входящих запросов с моих собственных IP-адресов, таких как
sudo ufw allow from XXX.XXX.XXX.XXX
Или, если вы хотите разрешить диапазон IP-адресов от 0 до 255, то
sudo ufw allow from XXX.XXX.XXX.0/24
Так как у меня было 3 машины. Итак, для каждой машины я добавил IP-адрес двух других машин. Все прошло нормально.