Таблица SQL Azure SQL не использует все распределения на вычислительных узлах для хранения данных
Одна из таблиц фактов в нашем SQL Azure SQL DW (хранит данные телеметрии поезда) создается как распределенная таблица HASH (ключ HASH - это VehicleDimId - целочисленное поле, ссылающееся на таблицу размеров автомобиля). Общее количество записей в таблице составляет ок. 1.3 миллиарда.
Есть 60 уникальных VehicleDimId (т.е. у нас есть данные для 60 уникальных транспортных средств) значения в таблице, что означает, что они также имеют 60 уникальных ключей хеша. Исходя из моего понимания, я ожидаю, что записи, соответствующие этим 60 уникальным хэш-ключам VehicleDimId должно быть распределено по 60 доступным дистрибутивам (1 хеш-ключ для 1 дистрибутива)
Однако в настоящее время все данные распределены только по 36 дистрибутивам, а остальные 24 дистрибутива отсутствуют. По сути, это всего лишь 60% использования доступных вычислительных узлов. Изменение масштаба хранилища данных не оказывает никакого влияния, так как число распределений остается неизменным до 60. В настоящее время мы используем SQL DW на уровне DW400. Ниже приведено количество записей таблицы на уровне вычислительных узлов.
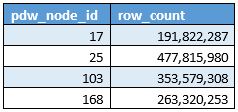
Вы можете видеть, что данные распределяются неравномерно по вычислительным узлам (что связано с тем, что данные не распределяются равномерно по базовым распределениям).
Я пытаюсь понять, что мне нужно сделать, чтобы SQL DW использовал все дистрибутивы, а не только 60% из них.
2 ответа
Хеш-распределение принимает хеш двоичного представления вашего ключа распределения, а затем детерминистически отправляет строку в назначенный дистрибутив. Обычно значение int 999 попадает в один и тот же дистрибутив на каждом SQL Azure SQL DW. Он не смотрит на ваши конкретные 60 уникальных идентификаторов транспортных средств и равномерно их разделяет.
Лучше всего выбирать поле (лучше всего, если оно используется в объединениях или групповых или разных счетах), которое имеет не менее 600 (в 10 раз больше распределений) достаточно равномерно используемых значений. Есть ли другие области, которые соответствуют этим критериям?
Цитирую из этой статьи, добавив немного акцента
Имеет много уникальных ценностей. Столбец может иметь несколько повторяющихся значений. Однако все строки с одним и тем же значением присваиваются одному и тому же распределению. Поскольку существует 60 распределений, столбец должен иметь не менее 60 уникальных значений. Обычно количество уникальных значений намного больше.
Если у вас только 60 различных значений, вероятность того, что вы получите равномерное распределение, очень мала. Чем в 10 раз больше значений, тем выше вероятность достижения равномерного распределения.
Резервным вариантом является использование циклического распределения. Делайте это только в том случае, если нет других хороших ключей распространения, которые производят равномерное распределение и которые используются в запросах. Циклическая сортировка должна обеспечивать оптимальную производительность загрузки, но производительность запросов будет снижаться, потому что первым шагом каждого запроса будет случайное перемешивание.
По моему мнению, объединение двух столбцов вместе (как предполагает ответ Эллиса) для использования в качестве ключа распределения, как правило, является худшим вариантом, чем круговое распределение, если только вы на самом деле не используете объединенный столбец в групповых байтах или объединениях или различных количествах.
Возможно, что текущее распределение идентификаторов транспортных средств - лучший выбор для эффективности запросов, поскольку это устранит шаг в случайном порядке во многих запросах, которые объединяются или группируются по идентификатору транспортного средства. Однако производительность нагрузки может быть намного хуже из-за сильного перекоса (неравномерное распределение).
Другой вариант - создать объединенный ключ соединения, который может быть объединением двух разных ключей, что создаст большую мощность, чем та, что у вас есть сейчас с 60 x новой строкой, как правило, в тысячах или больше. Предостережение заключается в том, что на ключ необходимо ссылаться в каждом соединении, чтобы работа выполнялась по одному на каждый узел. Затем, когда вы хешируете этот ключ, вы получите более равномерный спред.
Единственным недостатком является то, что вы должны распространить этот сцепленный ключ также на таблицу измерений и убедиться, что ваши условия соединения включают этот сцепленный ключ до последнего запроса. Например, вы сохраняете суррогатный ключ в подзапросах и удаляете его только в запросе верхнего уровня, чтобы принудительно объединить объединенные соединения.