Как извлечь повторное вложенное поле из строки json и объединить с существующим повторенным вложенным полем в bigquery
У меня есть таблица с одним вложенным повторяющимся полем под названием article_id и строковое поле, которое содержит строку json.
Вот схема моей таблицы:
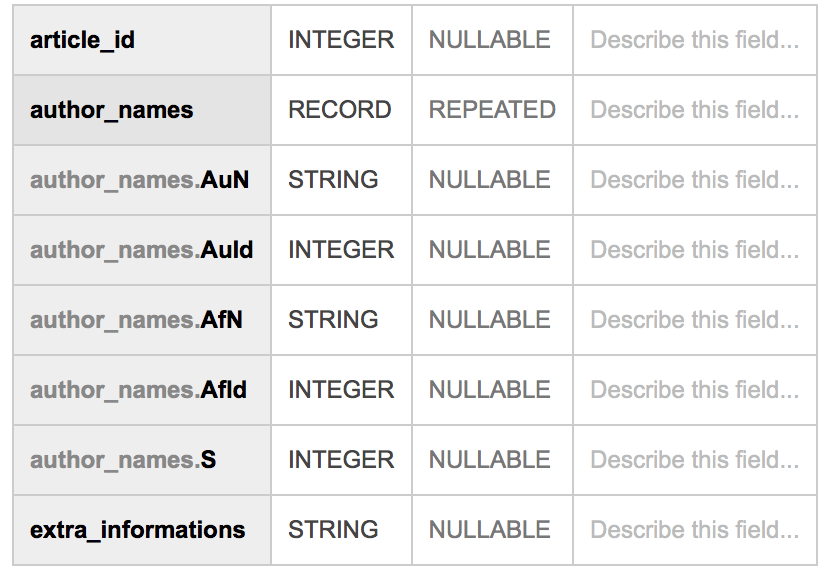
Вот пример строки таблицы:
[
{
"article_id": "2732930586",
"author_names": [
{
"AuN": "h kanahashi",
"AuId": "2591665239",
"AfN": null,
"AfId": null,
"S": "1"
},
{
"AuN": "t mukai",
"AuId": "2607493793",
"AfN": null,
"AfId": null,
"S": "2"
},
{
"AuN": "y yamada",
"AuId": "2606624579",
"AfN": null,
"AfId": null,
"S": "3"
},
{
"AuN": "k shimojima",
"AuId": "2606600298",
"AfN": null,
"AfId": null,
"S": "4"
},
{
"AuN": "m mabuchi",
"AuId": "2606138976",
"AfN": null,
"AfId": null,
"S": "5"
},
{
"AuN": "t aizawa",
"AuId": "2723380540",
"AfN": null,
"AfId": null,
"S": "6"
},
{
"AuN": "k higashi",
"AuId": "2725066679",
"AfN": null,
"AfId": null,
"S": "7"
}
],
"extra_informations": "{
\"DN\": \"Experimental study for improvement of crashworthiness in AZ91 magnesium foam controlling its microstructure.\",
\"S\":[{\"Ty\":1,\"U\":\"https://shibaura.pure.elsevier.com/en/publications/experimental-study-for-improvement-of-crashworthiness-in-az91-mag\"}],
\"VFN\":\"Materials Science and Engineering\",
\"FP\":283,
\"LP\":287,
\"RP\":[{\"Id\":2024275625,\"CoC\":5},{\"Id\":2035451257,\"CoC\":5}, {\"Id\":2141952446,\"CoC\":5},{\"Id\":2126566553,\"CoC\":6}, {\"Id\":2089573897,\"CoC\":5},{\"Id\":2069241702,\"CoC\":7}, {\"Id\":2000323790,\"CoC\":6},{\"Id\":1988924750,\"CoC\":16}],
\"ANF\":[
{\"FN\":\"H.\",\"LN\":\"Kanahashi\",\"S\":1},
{\"FN\":\"T.\",\"LN\":\"Mukai\",\"S\":2},
{\"FN\":\"Y.\",\"LN\":\"Yamada\",\"S\":3},
{\"FN\":\"K.\",\"LN\":\"Shimojima\",\"S\":4},
{\"FN\":\"M.\",\"LN\":\"Mabuchi\",\"S\":5},
{\"FN\":\"T.\",\"LN\":\"Aizawa\",\"S\":6},
{\"FN\":\"K.\",\"LN\":\"Higashi\",\"S\":7}
],
\"BV\":\"Materials Science and Engineering\",\"BT\":\"a\"}"
}
]
в extra_information.ANF У меня есть вложенный массив, который содержит дополнительную информацию об имени автора.
Вложенный повторный author_name поле имеет подполе author_name.S которые могут быть сопоставлены в extra_informations.ANF.S для объединения. Используя это отображение, я пытаюсь получить следующую таблицу:
| article_id | author_names.AuN | S | extra_information.ANF.FN | extra_information.ANF.LN|
| 2732930586 | h kanahashi | 1 | H. | Kanahashi |
| 2732930586 | t mukai | 2 | T. | Mukai |
| 2732930586 | y yamada | 3 | Y. | Yamada. |
| 2732930586 | k shimojima | 4 | K. | Shimojima |
| 2732930586 | m mabuchi | 5 | M. | Mabuchi |
| 2732930586 | t aizawa | 6 | T. | Aizawa |
| 2732930586 | k higashi | 7 | K. | Higashi |
Основная проблема, с которой я столкнулся, заключается в том, что когда я конвертирую json_string, используя JSON_EXTRACT(extra_information,"$.ANF"), он не дает мне массив, вместо этого он дает мне строковый формат вложенного повторного массива, который я не смог преобразовать в массив.
Можно ли создать такую таблицу с использованием стандартов SQL в BigQuery?
1 ответ
Опция 1
Это основано на функции REGEXP_REPLACE и нескольких дополнительных функциях (REPLACE, SPLIT и т. Д.) Для работы с результатом. Обратите внимание - нам нужны дополнительные манипуляции, потому что подстановочные знаки и фильтры не поддерживаются в выражениях JsonPath в BigQuery?
#standard SQL
SELECT
article_id, author.AuN, author.S,
REPLACE(SPLIT(extra, '","')[OFFSET(0)], '"FN":"', '') FirstName,
REPLACE(SPLIT(extra, '","')[OFFSET(1)], 'LN":"', '') LastName
FROM `table` , UNNEST(author_names) author
LEFT JOIN UNNEST(SPLIT(REGEXP_REPLACE(JSON_EXTRACT(extra_informations, '$.ANF'), r'\[{|}\]', ''), '},{')) extra
ON author.S = CAST(REPLACE(SPLIT(extra, '","')[OFFSET(2)], 'S":', '') AS INT64)
Вариант 2
Чтобы преодолеть "ограничение" BigQuery для JsonPath, вы можете использовать пользовательскую функцию, как показано в примере ниже:
Примечание: он использует файл jsonpath-0.8.0.js, который можно загрузить с https://code.google.com/archive/p/jsonpath/downloads и предположительно загрузить в облачное хранилище Google - gs://your_bucket/jsonpath-0.8.0.js
#standard SQL
CREATE TEMPORARY FUNCTION CUSTOM_JSON_EXTRACT(json STRING, json_path STRING)
RETURNS STRING
LANGUAGE js AS """
try { var parsed = JSON.parse(json);
return jsonPath(parsed, json_path);
} catch (e) { return null }
"""
OPTIONS (
library="gs://your_bucket/jsonpath-0.8.0.js"
);
SELECT
article_id, author.AuN, author.S,
CUSTOM_JSON_EXTRACT(extra_informations, CONCAT('$.ANF[?(@.S==', CAST(author.S AS STRING), ')].FN')) FirstName,
CUSTOM_JSON_EXTRACT(extra_informations, CONCAT('$.ANF[?(@.S==', CAST(author.S AS STRING), ')].LN')) LastName
FROM `table`, UNNEST(author_names) author
Как вы можете видеть - теперь вы можете делать всю магию в одном простом JsonPath