Можно ли переупорядочить неатомарную нагрузку после атомарной нагрузки?
Как известно, начиная с C++11 существует 6 порядков памяти, а в документации написано о std::memory_order_acquire:
memory_order_acquire
Операция загрузки с этим порядком памяти выполняет операцию получения в уязвимом месте памяти: доступ к памяти в текущем потоке не может быть переупорядочен до этой загрузки. Это гарантирует, что все записи в других потоках, которые выпускают одну и ту же атомарную переменную, видны в текущем потоке.
1. Неатомная нагрузка может быть переупорядочена после атомной нагрузки:
Т.е. это не гарантирует, что не-атомная нагрузка не может быть переупорядочена после получения-атомной нагрузки.
static std::atomic<int> X;
static int L;
...
void thread_func()
{
int local1 = L; // load(L)-load(X) - can be reordered with X ?
int x_local = X.load(std::memory_order_acquire); // load(X)
int local2 = L; // load(X)-load(L) - can't be reordered with X
}
Может загрузить int local1 = L; быть переупорядочен после X.load(std::memory_order_acquire);?
2. Мы можем думать, что не-атомная нагрузка не может быть переупорядочена после атомарной загрузки:
В некоторых статьях содержалась картинка, показывающая суть семантики приобретения-выпуска. Это легко понять, но может вызвать путаницу.
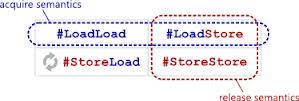

Например, мы можем думать, что std::memory_order_acquire не может переупорядочить любую серию операций Load-Load, даже не-atomic-load не может быть переупорядочено после atomic-acqu-load.
3. Неатомная нагрузка может быть переупорядочена после атомной нагрузки:
Хорошая вещь, которая разъясняется: семантика получения предотвращает переупорядочение памяти чтения-записи с любой операцией чтения или записи, которая следует за ней в программном порядке. http://preshing.com/20120913/acquire-and-release-semantics/
Но также известно, что: В строго упорядоченных системах (x86, SPARC TSO, мэйнфрейм IBM) упорядочение по типу выпуска-приобретения является автоматическим для большинства операций.
А Херб Саттер на странице 34 показывает: https://onedrive.live.com/view.aspx?resid=4E86B0CF20EF15AD!24884&app=WordPdf&authkey=!AMtj_EflYn2507c
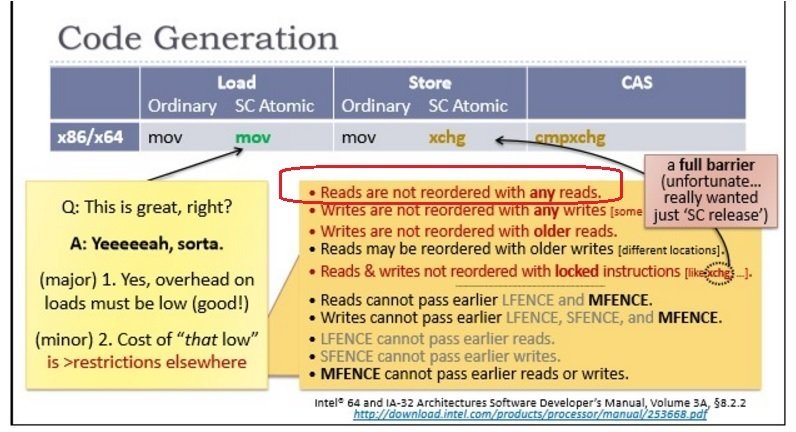
4. То есть, опять же, мы можем думать, что неатомная нагрузка не может быть переупорядочена после атомарной загрузки:
Т.е. для х86:
- Порядок выпуска- приобретения является автоматическим для большинства операций
- Чтения не переупорядочиваются с любыми чтениями. (любой - независимо от того, старше или нет)
Так можно ли переупорядочить non-atomic-load после atomic-acqu-load в C++11?
2 ответа
Ссылка, на которую вы ссылались, довольно ясна: вы не можете переместить чтения до этой загрузки. В вашем примере:
static std::atomic<int> X;
static int L;
void thread_func()
{
int local1 = L; // (1)
int x_local = X.load(std::memory_order_acquire); // (2)
int local2 = L; // (3)
}
memory_order_acquire означает, что (3) не может произойти до (2) (нагрузка в (2) секвенируется до нагрузки в (3)). Это ничего не говорит о связи между (1) и (2).
Я считаю, что это правильный способ рассуждать о вашем примере в стандарте C++:
X.load(std::memory_order_acquire)(давайте назовем это "операция(A)") может синхронизироваться с определенной операцией разблокировкиX(операция(R)) - примерно, операция, которая присвоила значениеXтот(A)читает.
[atomics.order] / 2 Атомная операция
Aкоторый выполняет операцию освобождения атомарного объектаMсинхронизируется с атомарной операциейBкоторый выполняет операцию получения наMи берет свое значение от любого побочного эффекта в последовательности выпуска, возглавляемойA,
Это отношение "синхронизируется с" может помочь установить отношение "произойдет до" между некоторыми изменениями
Lи назначениеlocal2 = L, Если это изменениеLслучается, перед тем(R)то из-за того, что(R)синхронизирует-с(A)а также(A)последовательность перед чтениемLта модификацияLслучается, прежде чем это читатьL,Но
(A)не имеет никакого влияния на заданиеlocal1 = L, Это не вызывает скачки данных, связанные с этим назначением, и не помогает предотвратить их. Если программа свободна от гонки, то она обязательно должна использовать какой-то другой механизм, чтобы гарантировать, что измененияLсинхронизируются с этим чтением (и если оно не является свободным от гонки, то оно демонстрирует неопределенное поведение, и стандарт больше ничего не может сказать об этом).
Бессмысленно говорить о "переупорядочении инструкций" в четырех углах стандарта C++. Можно говорить о машинных инструкциях, генерируемых конкретным компилятором, или о том, как эти инструкции выполняются конкретным процессором. Но с точки зрения стандарта, это всего лишь нерелевантные детали реализации, поскольку этот компилятор и этот ЦП производят наблюдаемое поведение, согласующееся с одним возможным путем выполнения абстрактной машины, описанным в стандарте ( правило "как если").
Операция загрузки с этим порядком памяти выполняет операцию получения в затронутой области памяти: никакие обращения к памяти в текущем потоке не могут быть переупорядочены до этой загрузки.
Это похоже на практическое правило генерации кода компилятора.
Но это абсолютно не аксиома C++.
Есть много случаев, некоторые из которых легко обнаружить, некоторые требуют дополнительной работы, когда операция с памятью Op на V может быть доказуемо переупорядочена с помощью атомарной операции X на A.
Два наиболее очевидных случая:
- когда V - строго локальная переменная: переменная, к которой не может получить доступ никакой другой поток (или обработчик сигналов), потому что ее адрес недоступен вне функции;
- когда A - такая строго локальная переменная.
(Обратите внимание, что эти два переупорядочивания компилятором действительны для любого из возможных порядков памяти, указанных для X.)
В любом случае трансформация не видна, она не меняет возможности выполнения допустимых программ.
Есть менее очевидные случаи, когда такие типы преобразований кода допустимы. Некоторые надуманы, некоторые реалистичны.
Я легко могу привести этот надуманный пример:
using namespace std;
static atomic<int> A;
int do_acq() {
return A.load(memory_order_acquire);
}
void do_rel() {
A.store(0, memory_order_release);
} // that's all folks for that TU
Заметка:
использование статической переменной, чтобы иметь возможность видеть все операции над объектом, над отдельно скомпилированным кодом; функции, которые обращаются к объекту атомарной синхронизации, не статичны и могут быть вызваны из всей программы.
В качестве примитива синхронизации операции с A устанавливают отношения синхронизации: между ними есть одно:
- поток X, который вызывает
do_rel()в точке pX - и поток Y, который вызывает
do_acq()в точке pY
Существует четко определенный порядок модификации M оператора A, соответствующий вызовам do_rel()в разных потоках. Каждый звонокdo_acq() либо:
- наблюдает за результатом звонка
do_rel()в pX_i и синхронизируется с потоком X, извлекая историю X в pX_i - наблюдает начальное значение A
С другой стороны, значение всегда равно 0, поэтому вызывающий код получает 0 только из do_acq()и не может определить, что произошло, по возвращаемому значению. Он может знать априори, что модификация A уже произошла, но не может знать только апостериори. Априорное знание может быть получено из другой операции синхронизации. Априорные знания являются частью истории потока Y. В любом случае операция получения не имеет знаний и не добавляет прошлую историю: известная часть операции получения пуста, она не может надежно получить что-либо, что было в прошлое потока Y в pY_i. Таким образом, получение на A бессмысленно и может быть оптимизировано.
Другими словами: программа, действующая для всех возможных значений M, должна быть действительной, когда do_acq() видит самые последние do_rel()в истории Y, тот, который был до всех модификаций A, которые можно увидеть. Так что do_rel () вообще ничего не добавляет:do_rel() может добавить неизбыточную синхронизацию с некоторыми исполнениями, но минимум того, что он добавляет Y, - это ничто, поэтому правильная программа, не имеющая состояния гонки (выражается как: ее поведение зависит от M, например, ее правильность - это функция получения некоторого подмножества допустимых значений для M) необходимо быть готовым не получать ничего из do_rel(); поэтому компилятор может сделатьdo_rel() NOP.
[Примечание: аргумент не может быть легко обобщен на все операции RMW, которые читают 0 и сохраняют 0. Это, вероятно, не может работать для RMW acq-rel. Другими словами, acq+rel RMW более мощные, чем отдельные нагрузки и хранилища, из-за их "побочного эффекта".
Резюме: в этом конкретном примере не только операции с памятью могут перемещаться вверх и вниз относительно операции атомарного получения, атомарные операции могут быть полностью удалены.
Просто чтобы ответить на ваш главный вопрос: да, любые загрузки (атомные или неатомные) можно переупорядочить после атомной загрузки. Точно так же любые магазины могут быть переупорядочены перед атомными магазинами.
Однако атомарное хранилище не обязательно может быть переупорядочено после атомарной загрузки или наоборот (атомная загрузка переупорядочена до атомарного хранилища).
См Герб Саттер разговора вокруг 44:00.