Torchvision 0.2.1 transforms. Нормализация не работает, как ожидалось
Я пытаюсь новый код, используя Pytorch. В этом коде для загрузки набора данных (CIFAR10) я использую наборы данных torchvision. Я определяю две функции преобразования ToTensor() и Normalize(). Я предполагаю, что после нормализации данные в наборе данных должны быть в диапазоне от 0 до 1. Но максимальное значение по-прежнему равно 255. Я также вставил оператор print в функцию '__call__' класса Normalize в transforms.py (Lib\site-packages\torchvision\ трансформирует \transforms.py). Этот отпечаток не печатается во время выполнения кода тоже. Не уверен, что происходит. Каждая страница, которую я посетил в Интернете, упоминает об использовании почти так же, как и я. Например, некоторые сайты, которые я посетил https://github.com/adventuresinML/adventures-in-ml-code/blob/master/pytorch_nn.py https://github.com/pytorch/tutorials/blob/master/beginner_source/blitz/cifar10_tutorial.py
Мой код приведен ниже. Это читает набор данных с нормализацией и без нее, а затем печатает некоторую статистику. Напечатанные минимальное и максимальное значения являются показателем того, нормализованы ли данные или нет.
import torchvision as tv
import numpy as np
dataDir = 'D:\\general\\ML_DL\\datasets\\CIFAR'
trainTransform = tv.transforms.Compose([tv.transforms.ToTensor()])
trainSet = tv.datasets.CIFAR10(dataDir, train=True, download=False, transform=trainTransform)
print (trainSet.train_data.mean(axis=(0,1,2))/255)
print (trainSet.train_data.min())
print (trainSet.train_data.max())
print (trainSet.train_data.shape)
trainTransform = tv.transforms.Compose([tv.transforms.ToTensor(), tv.transforms.Normalize((0.4914, 0.4822, 0.4466), (0.247, 0.243, 0.261))])
trainSet = tv.datasets.CIFAR10(dataDir, train=True, download=False, transform=trainTransform)
print (trainSet.train_data.mean(axis=(0,1,2))/255)
print (trainSet.train_data.min())
print (trainSet.train_data.max())
print (trainSet.train_data.shape)
Выход выглядит так:
[ 0.49139968 0.48215841 0.44653091]
0
255
(50000, 32, 32, 3)
[ 0.49139968 0.48215841 0.44653091]
0
255
(50000, 32, 32, 3)
Пожалуйста, помогите мне понять это лучше. Как и большинство функций, которые я пробовал, в итоге получаются похожие результаты - например, Grayscale, CenterCrop.
3 ответа
Итак, в коде вы изложили план того, как вы хотите обрабатывать свои данные. Вы создали конвейер данных, по которому будут передаваться ваши данные, и будет применено несколько преобразований.
Тем не менее, вы забыли позвонить torch.utils.data.DataLoader, Пока это не будет вызвано, преобразования ваших данных не будут применяться. Вы можете прочитать больше об этом здесь.
Теперь, когда мы добавим вышеуказанное в ваш код, как показано ниже:
trainTransform = tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.4914, 0.4822, 0.4466), (0.247, 0.243, 0.261))])
trainSet = tv.datasets.CIFAR10(root=dataDir, train=True,
download=False, transform=trainTransform)
dataloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=False, num_workers=4)
и напечатанные изображения, такие как следующие -
images, labels = iter(dataloader).next()
print images
print images.max()
print images.min()
Мы получаем Tensors имея преобразования мы применили.
Небольшой фрагмент вывода
[[ 1.8649, 1.8198, 1.8348, ..., 0.3924, 0.3774, 0.2572],
[ 1.9701, 1.9550, 1.9851, ..., 0.7230, 0.6929, 0.6629],
[ 2.0001, 1.9550, 2.0001, ..., 0.7831, 0.7530, 0.7079],
...,
[-0.8096, -1.0049, -1.0350, ..., -1.3355, -1.3655, -1.4256],
[-0.7796, -0.8697, -0.9749, ..., -1.2754, -1.4557, -1.5609],
[-0.7645, -0.7946, -0.9298, ..., -1.4106, -1.5308, -1.5909]]]])
tensor(2.1309)
tensor(-1.9895)
Во-вторых, transforms.Normalize(mean,std) относится input[channel] = (input[channel] - mean[channel]) / std[channel] поэтому в соответствии со средним и стандартным отклонением мы не можем получить значения после преобразования в диапазоне (0,1), Если вы хотите значения между (-1,1) Вы можете использовать следующее -
trainTransform = tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
Я надеюсь, что это помогает!:)
Похоже, что при чтении без нормализации и преобразовании в тензоры они автоматически нормализуются в диапазоне от 0 до 1. Когда мы применяем нормализацию, она применяет формулу, которую вы упомянули для этих данных, в диапазоне от 0 до 1. Ниже приведен модифицированный рабочий код с некоторыми операторами печати, показывающими, когда вызывается функция __call__ внутри класса Normalize, а также показывающими, как значения нормализовано. Первое значение составляет 0,2314. Нормализация с 0,5 дает (0,2314-0,5)/0,5 = -0,5372. Первый отпечаток и второй отпечаток тензорного значения показывают это.
Код
import torchvision as tv
import numpy as np
import torch.utils.data as data
dataDir = 'D:\\general\\ML_DL\\datasets\\CIFAR'
trainTransform = tv.transforms.Compose([tv.transforms.ToTensor()])
trainSet = tv.datasets.CIFAR10(dataDir, train=True, download=False, transform=trainTransform)
print ('Approach1 Step1 done')
dataloader = data.DataLoader(trainSet, batch_size=1, shuffle=False, num_workers=0)
print ('Approach1 Step2 done')
images, labels = iter(dataloader).next()
print ('Approach1 Step3 done')
print (images[0,0])
print (images.max())
print (images.min())
print (images.mean())
#trainTransform = tv.transforms.Compose([tv.transforms.ToTensor(), tv.transforms.Normalize((0.4914, 0.4822, 0.4466), (0.247, 0.243, 0.261))])
trainTransform = tv.transforms.Compose([tv.transforms.ToTensor(), tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainSet = tv.datasets.CIFAR10(dataDir, train=True, download=False, transform=trainTransform)
print ('Approach2 Step1 done')
dataloader = data.DataLoader(trainSet, batch_size=1, shuffle=False, num_workers=0)
print ('Approach2 Step2 done')
images, labels = iter(dataloader).next()
print ('Approach2 Step3 done')
print (images[0,0])
print (images.max())
print (images.min())
print (images.mean())
И вывод для приведенного выше кода
Approach1 Step1 done
Approach1 Step2 done
Approach1 Step3 done
tensor([[0.2314, 0.1686, 0.1961, ..., 0.6196, 0.5961, 0.5804],
[0.0627, 0.0000, 0.0706, ..., 0.4824, 0.4667, 0.4784],
[0.0980, 0.0627, 0.1922, ..., 0.4627, 0.4706, 0.4275],
...,
[0.8157, 0.7882, 0.7765, ..., 0.6275, 0.2196, 0.2078],
[0.7059, 0.6784, 0.7294, ..., 0.7216, 0.3804, 0.3255],
[0.6941, 0.6588, 0.7020, ..., 0.8471, 0.5922, 0.4824]])
tensor(1.)
tensor(0.)
tensor(0.4057)
Approach2 Step1 done
Approach2 Step2 done
__call__ inside Normalization is called
Approach2 Step3 done
tensor([[-0.5373, -0.6627, -0.6078, ..., 0.2392, 0.1922, 0.1608],
[-0.8745, -1.0000, -0.8588, ..., -0.0353, -0.0667, -0.0431],
[-0.8039, -0.8745, -0.6157, ..., -0.0745, -0.0588, -0.1451],
...,
[ 0.6314, 0.5765, 0.5529, ..., 0.2549, -0.5608, -0.5843],
[ 0.4118, 0.3569, 0.4588, ..., 0.4431, -0.2392, -0.3490],
[ 0.3882, 0.3176, 0.4039, ..., 0.6941, 0.1843, -0.0353]])
tensor(1.)
tensor(-1.)
tensor(-0.1886)
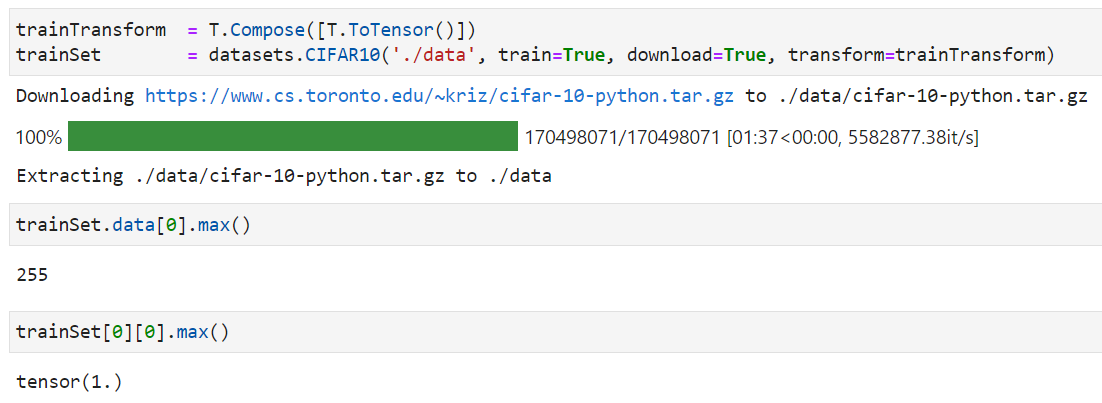
Вы напрямую индексируете базовые непреобразованные данные, используя trainSet.train_data. Попробуйте проиндексировать набор данных, чтобы получить преобразованные тензоры trainSet[index].
Я попытался воспроизвести проблему и вот решение: