Является ли Snappy разделяемым или не разделяемым?
Согласно этому сообщению Cloudera, Snappy IS разделяемый.
Для MapReduce, если вам нужно, чтобы сжатые данные были разделяемыми, форматы BZip2, LZO и Snappy делятся, но GZip - нет. Разделимость не относится к данным HBase.
Но из полного руководства Hadoop, Снейпп НЕ делится. 
Есть также некоторая обнадеживающая информация в сети. Некоторые говорят, что это разделимо, некоторые говорят, что это не так.
3 ответа
Оба верны, но на разных уровнях.
По сообщению блога Cloudera http://blog.cloudera.com/blog/2011/09/snappy-and-hadoop/
Стоит отметить, что Snappy предназначен для использования с
формат контейнера, такой как файлы последовательностей или файлы данных Avro, а не используется непосредственно, например, в виде простого текста, поскольку последний не разделяется и не может обрабатываться параллельно с помощью MapReduce. Это отличается от LZO, где возможно индексировать сжатые файлы LZO для определения точек разделения, чтобы файлы LZO могли эффективно обрабатываться при последующей обработке.
Это означает, что если весь текстовый файл сжат с помощью Snappy, то этот файл НЕ разделяется. Но если каждая запись в файле сжимается с помощью Snappy, то этот файл можно разделить, например, в файлах Sequence со сжатием блоков.
Чтобы быть более понятным, это не то же самое
<START-FILE>
<START-SNAPPY-BLOCK>
FULL CONTENT
<END-SNAPPY-BLOCK>
<END-FILE>
чем
<START-FILE>
<START-SNAPPY-BLOCK1>
RECORD1
<END-SNAPPY-BLOCK1>
<START-SNAPPY-BLOCK2>
RECORD2
<END-SNAPPY-BLOCK2>
<START-SNAPPY-BLOCK3>
RECORD3
<END-SNAPPY-BLOCK3>
<END-FILE>
Блоки Snappy НЕ разделяются, но файлы с блоками Snappy являются разделяемыми.
Я только что протестировал Spark 1.6.2 на HDFS для того же числа рабочих / процессоров, между простым файлом JSON и сжатым с помощью snappy:
- JSON: 4 файла по 12 ГБ каждый, Spark создает 388 задач (1 задача для блока HDFS) (4*12 ГБ /128 МБ => 384)
- Snappy: 4 файла по 3 ГБ каждый, Spark создает 4 задания
Файл Snappy создается так: .saveAsTextFile("/user/qwant/benchmark_file_format/json_snappy", classOf[org.apache.hadoop.io.compress.SnappyCodec])
Так что Снейппи нельзя разделить с Spark для JSON.
Но если вы используете формат файла паркет (или ORC) вместо JSON, это будет делимым (даже с gzip).
Все разделяемые кодеки в hadoop должны реализовывать org.apache.hadoop.io.compress.SplittableCompressionCodec, Глядя на исходный код Hadoop с версии 2.7, мы видим org.apache.hadoop.io.compress.SnappyCodec не реализует этот интерфейс, поэтому мы знаем, что он не разделяемый.
Snappy на самом деле не разделяется, как bzip, но при использовании с такими форматами файлов, как parquet или Avro, вместо сжатия всего файла блоки внутри формата файла сжимаются с помощью snappy.
Чтобы понять, что происходит при сжатии файла паркета с помощью мгновенного сжатия, проверьте структуру файла паркета [ ссылка на источник ]
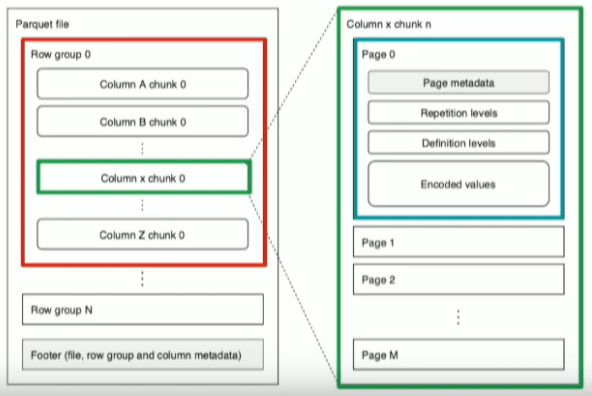
Внутри паркетного файла записи разбиваются на группы строк [в основном это подмножество строк из исходного файла], и каждая группа строк состоит из страниц данных [фрагменты столбцов на изображении], каждый фрагмент столбца состоит из множества страниц где фактические записи хранятся в закодированном формате [столбец] с метаданными. когда вы включаете мгновенное сжатие, сжимаются целые страницы! не весь файл. в основном вы получаете разделенный паркет с мгновенным сжатием.
Преимущество snappy в том, что это очень легкий кодек сжатия.
Примечание. Существует ограничение на размер по умолчанию для групп строк и блоков столбцов, 128 МБ и 1 МБ соответственно [вы можете изменить эти настройки по умолчанию], вы можете использовать другой кодек сжатия с паркетом, например gzip