Расширение Chrome Web Scraper с условиями dd и dt
Я хочу извлечь некоторые данные из Интернета, и я использую инструмент разработчика веб-скребка, предоставленный Chrome. Мои веб-страницы содержат разделы, в которых перечислены сведения о каждом продукте (сведения о графической карте, процессоре, дисплее и т. Д.). Но каждый раздел содержит много строк, и эти позиции не являются фиксированными. Если это было описано с использованием тегов TR и TD, то я могу применить такие условия (например: tr: Содержит ('Prozessortyp') td.value) Это условие подтверждает, что, если значение строки " Prozessortyp " только тогда, возьмите соответствующее значение тд.
Но сайт, который я извлекаю, описан с использованием тэгов dd и dt. Я приложу скриншоты деталей одного конкретного раздела. 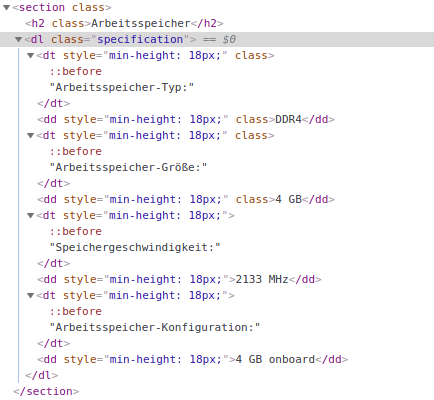

Когда я хочу выбрать первую строку в этом разделе, селектор, который он дает в веб-скребке, section:nth-of-type(2) dd:nth-of-type(1), Но как я могу поставить условие, когда в строке есть ключ "Arbeitsspeicher-Typ", а затем выбрать значение в соответствующей строке.
Спасибо:)
0 ответов
Селекторы CSS на самом деле могут выбирать братьев и сестер элемента. Для этого варианта использования вам понадобится Селектор соседнего брата (+):
dt:contains("Arbeitsspeicher-Typ") + dd
dt:contains("Speichergeschwindigkeit") + dd
...
Это должно сделать свое дело, предполагая, что селектор однозначен в графе селектора. Я бы порекомендовал использовать dl.specification как родительский селектор.
Если какой-либо из dt elements представляет логическое свойство, которое нелегко захватить в текстовом выводе, например, когда dd содержит галочку svg без текста:
dt:contains("Validated")
Просто проверяя наличие dt (опуская dd селектор родного брата) может выдавать нужную информацию, когда наличие самой строки является условным.