Что такое рабочие, исполнители, ядра в кластере Spark Standalone?
Я прочитал обзор режима кластера и до сих пор не могу понять различные процессы в автономном кластере Spark и параллелизм.
Является ли рабочий процессом JVM или нет? Я управлял bin\start-slave.sh и обнаружил, что он породил рабочего, который на самом деле является JVM.
Согласно приведенной выше ссылке, исполнитель - это процесс, запускаемый для приложения на рабочем узле, на котором выполняются задачи. Исполнитель также является JVM.
Это мои вопросы:
Исполнители по заявке. Тогда какова роль работника? Координирует ли это с исполнителем и передает результат обратно водителю? или водитель напрямую общается с исполнителем? Если так, то какова цель работника тогда?
Как контролировать количество исполнителей для заявки? 3.Могут ли задачи выполняться параллельно внутри исполнителя? Если да, то как настроить количество потоков для исполнителя?
Какова связь между работником, исполнителями и ядрами исполнителя ( --total-executor-core)?
что значит иметь больше работников на узел?
обновленный
Давайте возьмем примеры, чтобы лучше понять.
Пример 1: Автономный кластер с 5 рабочими узлами (каждый узел имеет 8 ядер) Когда я запускаю приложение с настройками по умолчанию.
Пример 2 Та же конфигурация кластера, что и в примере 1, но я запускаю приложение со следующими настройками --executor-cores 10 --total-executor-cores 10.
Пример 3 Та же конфигурация кластера, что и в примере 1, но я запускаю приложение со следующими настройками --executor-cores 10 --total-executor-cores 50.
Пример 4 Та же конфигурация кластера, что и в примере 1, но я запускаю приложение со следующими настройками --executor-cores 50 --total-executor-cores 50.
Пример 5 Та же конфигурация кластера, что и в примере 1, но я запускаю приложение со следующими настройками --executor-cores 50 --total-executor-cores 10.
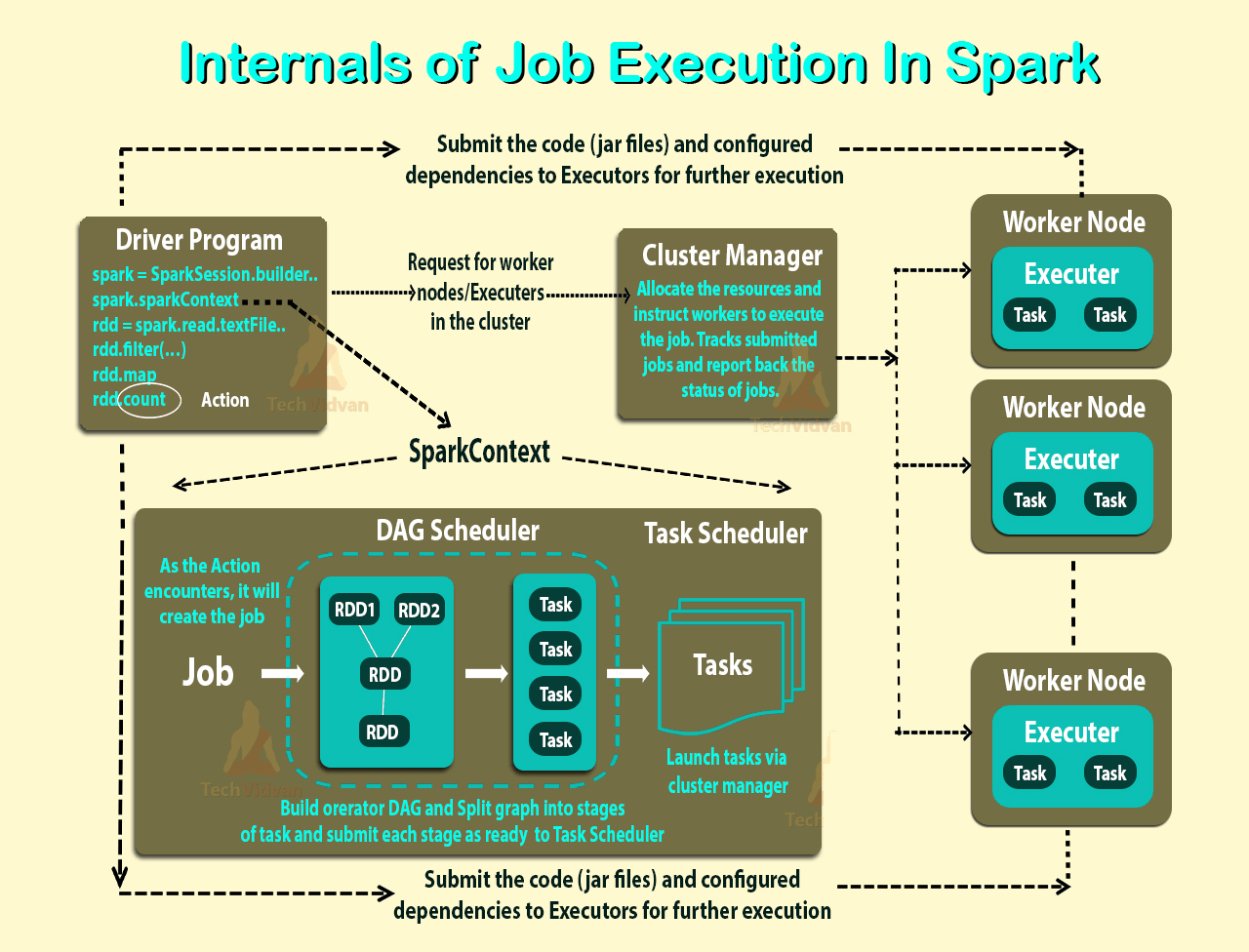
В каждом из этих примеров Сколько исполнителей? Сколько потоков на одного исполнителя? Сколько ядер? Как определяется количество исполнителей на одну заявку. Всегда ли это число рабочих?
1 ответ
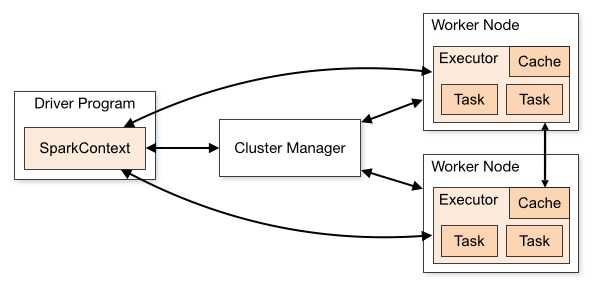
Spark использует архитектуру master/slave. Как видно на рисунке, у него есть один центральный координатор (Драйвер), который общается со многими распределенными работниками (исполнителями). Драйвер и каждый из исполнителей работают в своих собственных процессах Java.
ВОДИТЕЛЬ
Драйвер - это процесс, в котором выполняется основной метод. Сначала он преобразует пользовательскую программу в задачи, а затем планирует задачи для исполнителей.
ИСПОЛНИТЕЛИ
Исполнители - это процессы рабочих узлов, отвечающие за выполнение отдельных задач в задании Spark. Они запускаются в начале приложения Spark и обычно работают в течение всего срока службы приложения. После выполнения задания они отправляют результаты драйверу. Они также обеспечивают хранение в памяти RDD, которые кэшируются пользовательскими программами через Block Manager.
ПРИМЕНЕНИЕ ИСПОЛНИТЕЛЬНЫЙ ПОТОК
Имея это в виду, когда вы отправляете приложение в кластер с помощью spark-submit, это происходит внутри:
- Автономное приложение запускается и создает экземпляр
SparkContextэкземпляр (и только тогда можно назвать приложение драйвером). - Программа драйвера запрашивает ресурсы у менеджера кластера для запуска исполнителей.
- Менеджер кластера запускает исполнителей.
- Процесс драйвера запускается через пользовательское приложение. В зависимости от действий и преобразований над СДР задача отправляется исполнителям.
- Исполнители запускают задания и сохраняют результаты.
- В случае сбоя какого-либо работника его задачи будут отправлены разным исполнителям для последующей обработки. В книге "Изучение Spark: молниеносный анализ больших данных" они говорят о Spark и отказоустойчивости:
Spark автоматически обрабатывает сбойные или медленные машины путем повторного выполнения сбойных или медленных задач. Например, если происходит сбой узла, на котором выполняется раздел операции map(), Spark перезапустит его на другом узле; и даже если узел не дает сбоя, а просто намного медленнее, чем другие узлы, Spark может превентивно запустить "умозрительную" копию задачи на другом узле и получить ее результат, если он завершится.
- При использовании SparkContext.stop() из драйвера или при выходе или сбое основного метода все исполнители будут прерваны, а ресурсы кластера будут освобождены менеджером кластера.
ВАШИ ВОПРОСЫ
Когда исполнители запускаются, они регистрируются у водителя и с этого момента общаются напрямую. Рабочие отвечают за информирование менеджера кластера о доступности своих ресурсов.
В кластере YARN вы можете сделать это с --num-executors. В автономном кластере вы получите одного исполнителя на каждого работника, если вы не играете с spark.executor.cores, а у работника достаточно ядер, чтобы вместить более одного исполнителя. (Как отметил @JacekLaskowski, --num-executors больше не используется в YARN https://github.com/apache/spark/commit/16b6d18613e150c7038c613992d80a7828413e66)
Вы можете назначить количество ядер для исполнителя с помощью --executor-cores.
--total-executor-cores - максимальное количество ядер исполнителя на приложение
Как сказал Шон Оуэн в этой теме: "Нет веских причин использовать более одного рабочего на одну машину". Например, в одной машине будет много JVM.
ОБНОВИТЬ
Я не смог протестировать этот сценарий, но согласно документации:
ПРИМЕР 1: Spark жадно приобретет столько ядер и исполнителей, сколько предложено планировщиком. В итоге вы получите 5 исполнителей с 8 ядрами в каждом.
ПРИМЕР 2 - 5: Spark не сможет выделить столько ядер, сколько требуется для одного работника, поэтому исполнители запускаться не будут.