Как добавить оглавление в блокнот ipython?
В документации по http://ipython.org/ipython-doc/stable/interactive/notebook.html говорится
Вы можете предоставить концептуальную структуру для своего вычислительного документа в целом, используя различные уровни заголовков; доступно 6 уровней, от уровня 1 (верхний уровень) до уровня 6 (абзац). Они могут быть использованы позже для построения оглавлений и т. Д.
Однако я нигде не могу найти инструкций о том, как использовать мои иерархические заголовки для создания такого оглавления. Есть ли способ сделать это?
NB: Я также был бы заинтересован в других видах навигации с использованием заголовков ipython notebook, если таковые существуют. Например, перепрыгивая назад и вперед от заголовка к заголовку, чтобы быстро найти начало каждого раздела, или скрывая (складывая) содержимое целого раздела. Это мой список пожеланий, но любой вид навигации будет интересен. Спасибо!
12 ответов
Существует ipython nbextension, которое создает оглавление для ноутбука. Кажется, обеспечивает только навигацию, а не складывание разделов.
Вы можете добавить оглавление вручную с помощью Markdown и HTML. Вот как я добавил:
Создайте оглавление в верхней части Jupyter Notebook:
## TOC:
* [First Bullet Header](#first-bullet)
* [Second Bullet Header](#second-bullet)
Добавьте html якоря по всему телу:
## First Bullet Header <a class="anchor" id="first-bullet"></a>
code blocks...
## Second Bullet Header <a class="anchor" id="second-bullet"></a>
code blocks...
Возможно, это не лучший подход, но он работает. Надеюсь это поможет.
Инструкции JupyterLab ToC
На этот вопрос уже есть много хороших ответов, но они часто требуют настройки для правильной работы с блокнотами в JupyterLab. Я написал этот ответ, чтобы подробно описать возможные способы включения ToC в записную книжку во время работы и экспорта из JupyterLab.
Как боковая панель
Расширение jupyterlab-toc добавляет ToC в качестве боковой панели, которая может нумеровать заголовки, сворачивать разделы и использоваться для навигации (см. Рисунок ниже для демонстрации). Установите с помощью следующей команды
jupyter labextension install @jupyterlab/toc
https://raw.githubusercontent.com/jupyterlab/jupyterlab-toc/master/toc.gif
В записной книжке как клетка
В настоящее время это можно сделать либо вручную, как в ответе Мэтта Данчо, либо автоматически через расширение toc2 jupyter notebook в классическом интерфейсе ноутбука.
Сначала установите toc2 как часть пакета https://github.com/ipython-contrib/jupyter_contrib_nbextensions:
conda install -c conda-forge jupyter_contrib_nbextensions
Затем запустите JupyterLab, перейдите вHelp --> Launch Classic Notebookи откройте записную книжку, в которую вы хотите добавить ToC. Щелкните символ toc2 на панели инструментов, чтобы открыть плавающее окно ToC(см. Гифку ниже, если вы не можете его найти), щелкните значок шестеренки и установите флажок "Добавить ячейку ToC для записной книжки". Сохраните записную книжку, и ячейка ToC будет там, когда вы откроете ее в JupyterLab. Вставленная ячейка является ячейкой уценки с HTML-кодом, она не будет обновляться автоматически.
Параметры toc2 по умолчанию можно настроить на вкладке "Nbextensions" на классической странице запуска записной книжки. Вы можете, например, пронумеровать заголовки и привязать ToC как боковую панель (что, по моему мнению, выглядит чище).
https://jupyter-contrib-nbextensions.readthedocs.io/en/latest/_images/demo4.gif
В экспортированном HTML-файле
nbconvertможет использоваться для экспорта записных книжек в HTML, следуя правилам форматирования экспортируемого HTML. Вtoc2 упомянутое выше расширение добавляет формат экспорта, называемый html_toc, который можно использовать напрямую с nbconvert из командной строки (после toc2 расширение установлено):
jupyter nbconvert file.ipynb --to html_toc
# Append `--ExtractOutputPreprocessor.enabled=False`
# to get a single html file instead of a separate directory for images
Помните, что команды оболочки могут быть добавлены в ячейки записной книжки, поставив перед ними восклицательный знак. !, поэтому вы можете вставить эту строку в последнюю ячейку записной книжки и всегда иметь HTML-файл с ToC, сгенерированный, когда вы нажимаете "Выполнить все ячейки"
(или любой другой результат, который вы хотите nbconvert). Таким образом, вы можете использоватьjupyterlab-toc чтобы перемещаться по записной книжке во время работы и по-прежнему получать ToCs в экспортированном выводе, не прибегая к использованию классического интерфейса записной книжки (для пуристов среди нас).
Обратите внимание, что настройка параметров toc2 по умолчанию, как описано выше, не изменит форматnbconver --to html_toc. Вам нужно открыть записную книжку в классическом интерфейсе записной книжки, чтобы метаданные были записаны в файл.ipynb (nbconvert считывает метаданные при экспорте). Кроме того, вы можете добавить метаданные вручную через вкладку "Инструменты записной книжки" на боковой панели JupyterLab, например что-то нравиться:
"toc": {
"number_sections": false,
"sideBar": true
}
Если вы предпочитаете подход, основанный на графическом интерфейсе пользователя, вы сможете открыть классический блокнот и щелкнуть File --> Save as HTML (with ToC)(хотя учтите, что этот пункт меню был мне недоступен).
На приведенные выше гифки есть ссылки из соответствующей документации расширений.
Вот еще один вариант без особых проблем с JS: https://github.com/kmahelona/ipython_notebook_goodies
Как насчет использования плагина браузера, который дает вам обзор любой HTML-страницы. Я пробовал следующее:
- HTML 5 Outliner для Chrome
- Карта заголовков для Firefox
Они оба работают очень хорошо для ноутбуков IPython. Я неохотно использовал предыдущие решения, так как они кажутся немного нестабильными и в итоге использовали эти расширения.
Недавно я создал небольшое расширение для Jupyter с именем jupyter-navbar. Он ищет заголовки, записанные в ячейках уценки, и иерархически отображает ссылки на них на боковой панели. Боковая панель может быть изменяемого размера и складной. Смотрите скриншот ниже.
Он прост в установке и использует преимущества "пользовательских" кодов JS и CSS, которые выполняются при открытии ноутбука, поэтому вам не нужно запускать его вручную.

Вступление
Как отметили @Ian и @Sergey, nbextensions - простое решение. Чтобы уточнить свой ответ, вот еще несколько сведений.
Что такое nbextensions?
Nbextensions содержит набор расширений, которые добавляют функциональность вашей записной книжке Jupyter.
Например, просто чтобы процитировать несколько расширений:
Оглавление

Складные заголовки

Установить nbextensions
Установка может производиться через Conda или PIP.
# If conda:
conda install -c conda-forge jupyter_contrib_nbextensions
# or with pip:
pip install jupyter_contrib_nbextensions
Скопируйте файлы js и css
Чтобы скопировать файлы javascript и css nbextensions в каталог поиска сервера jupyter, выполните следующие действия:
jupyter contrib nbextension install --user
Переключить расширения
Обратите внимание: если вы не знакомы с терминалом, лучше установить конфигуратор nbextensions (см. Следующий раздел)
Вы можете включить / отключить расширения по вашему выбору. Как упоминается в документации, общая команда:
jupyter nbextension enable <nbextension require path>
Конкретно, чтобы включить расширение ToC (Table of Contents), выполните:
jupyter nbextension enable toc2/main
Установите интерфейс конфигурации (необязательно, но полезно)
Как сказано в документации, nbextensions_configurator предоставляет интерфейсы конфигурации для nbextensions.
Выглядит это примерно так:
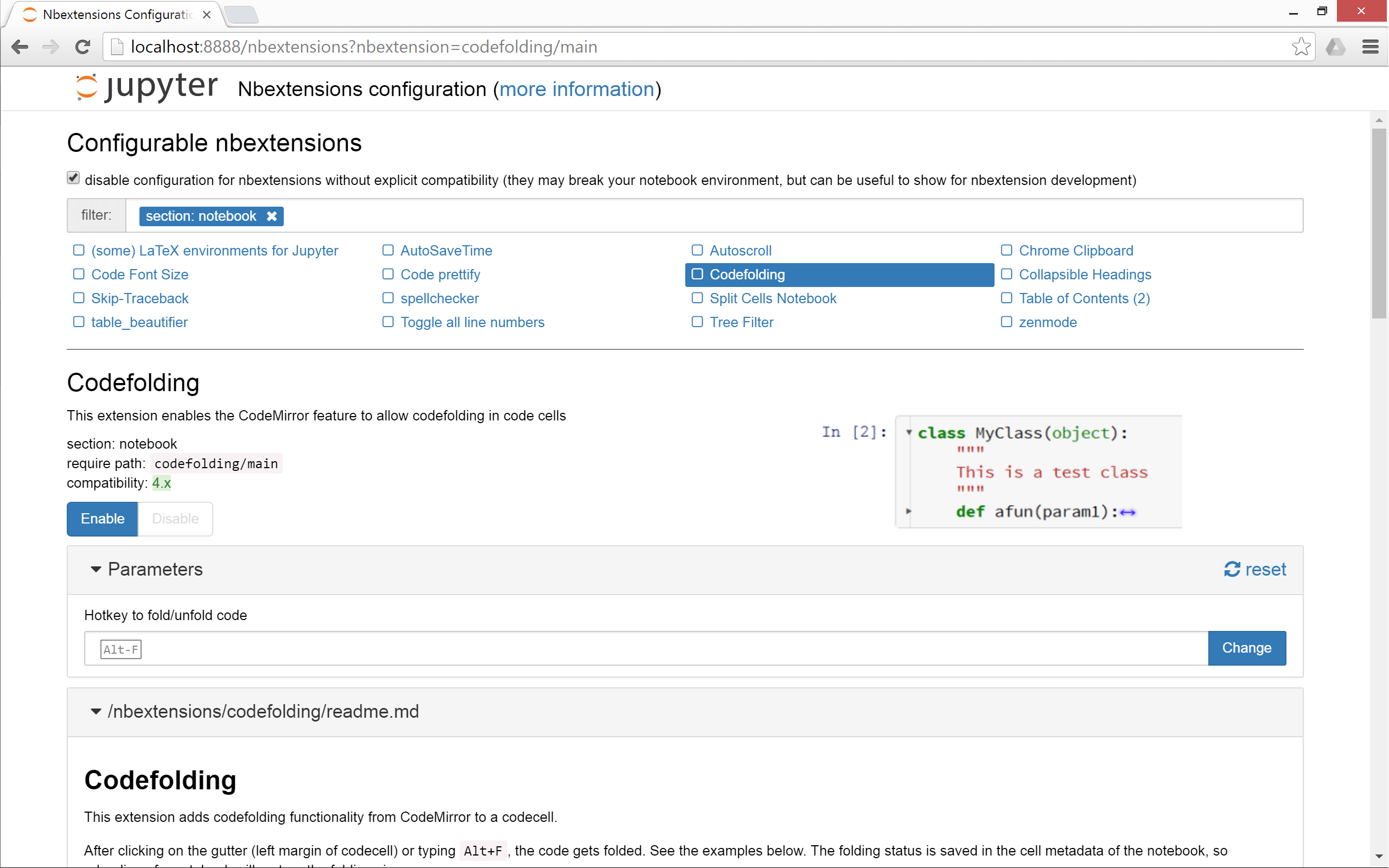
Чтобы установить его, если вы используете conda:
conda install -c conda-forge jupyter_nbextensions_configurator
Если у вас нет Conda или вы не хотите устанавливать через Conda, выполните следующие 2 шага:
pip install jupyter_nbextensions_configurator
jupyter nbextensions_configurator enable --user
Теперь есть два пакета, которые можно использовать для обработки расширений Jupyter:
https://github.com/ipython-contrib/jupyter_contrib_nbextensions, который устанавливает расширения, включая оглавление;
https://github.com/Jupyter-contrib/jupyter_nbextensions_configurator, который предоставляет графические пользовательские интерфейсы для настройки включенных nbextensions (автоматически загружать для каждого ноутбука) и предоставляет элементы управления для настройки параметров nbextensions.
Простое решение для уценки
Вы можете использовать гиперссылки уценки для перехода к заголовкам уценки без определения тегов HTML. Независимо от того, сколько хешей
#у вас есть в заголовке, используйте один для гиперссылки. Любые пробелы в названии заменяются дефисами.
-.
Создать таблицу содержимого
# Contents
- [Section 1](#Section-1)
- [Section 2](#Section-2)
- [Section 3](#Section-3)
Создать заголовки
# Section 1
## Section 2
Вы также можете добавить гиперссылку обратно к содержимому.
### Section 3
[top](#Contents)
Это похоже на ответ Мэтта Данчо, но я всегда считаю привязки html неудобными.
Вот мой подход, неуклюжий как есть и доступный в github:
Вставьте самую первую ячейку записной книжки, ячейку импорта:
from IPythonTOC import IPythonTOC
toc = IPythonTOC()
Где-то после ячейки импорта вставьте ячейку genTOCEntry, но пока не запускайте ее:
''' if you called toc.genTOCMarkdownCell before running this cell,
the title has been set in the class '''
print toc.genTOCEntry()
Под ячейкой genTOCEntry сделайте ячейку TOC в качестве ячейки уценки:
<a id='TOC'></a>
#TOC
По мере разработки ноутбука, поместите этот genTOCMarkdownCell перед началом нового раздела:
with open('TOCMarkdownCell.txt', 'w') as outfile:
outfile.write(toc.genTOCMarkdownCell('Introduction'))
!cat TOCMarkdownCell.txt
!rm TOCMarkdownCell.txt
Переместите genTOCMarkdownCell вниз в ту точку в вашей записной книжке, где вы хотите начать новый раздел, и введите аргумент для genTOCMarkdownCell заголовок строки для нового раздела, затем запустите его. Добавьте ячейку уценки сразу после нее и скопируйте вывод из genTOCMarkdownCell в ячейку уценки, которая начинает новый раздел. Затем перейдите в ячейку genTOCEntry в верхней части вашего ноутбука и запустите ее. Например, если вы сделаете аргумент genTOCMarkdownCell, как показано выше, и запустите его, вы получите этот вывод для вставки в первую ячейку уценки вашего недавно проиндексированного раздела:
<a id='Introduction'></a>
###Introduction
Затем, когда вы идете в верхнюю часть вашего ноутбука и запускаете genTocEntry, вы получаете вывод:
[Introduction](#Introduction)
Скопируйте эту строку ссылки и вставьте ее в ячейку уценки TOC следующим образом:
<a id='TOC'></a>
#TOC
[Introduction](#Introduction)
После того, как вы отредактируете ячейку TOC, вставив строку ссылки, а затем нажмете Shift-Enter, ссылка на ваш новый раздел появится в вашей записной книжке в виде веб-ссылки, и при щелчке по ней браузер перейдет в ваш новый раздел.
Я часто забываю о том, что нажатие на строку в оглавлении заставляет браузер переходить к этой ячейке, но не выбирает ее. Независимо от того, какая ячейка была активной, когда мы щелкнули ссылку TOC, она все еще активна, поэтому стрелка вниз или вверх или Shift-Enter относятся к все еще активной ячейке, а не к ячейке, которую мы получили, щелкнув ссылку TOC.
Как уже указывал Ян, у minrk есть расширение оглавления для записной книжки IPython. У меня были некоторые проблемы, чтобы заставить его работать, и сделал этот Блокнот IPython, который полуавтоматически генерирует файлы для расширения содержания minrk в Windows. Он не использует 'curl' -команды или ссылки, но записывает файлы *.js и *.css непосредственно в ваш каталог-профиль IPython Notebook.
В записной книжке есть раздел "Что вам нужно сделать" - следуйте ему и получите хорошее плавающее оглавление:)
Вот HTML-версия, которая уже показывает это: http://htmlpreview.github.io/?https://github.com/ahambi/140824-TOC/blob/master/A%20floating%20table%20of%20contents.htm
На вопрос уже был дан ответ, но вот функция для других, таких как я, которым нужно легкое решение, которое они могут вставить в ячейку кода, запустить и получить оглавление для копирования и вставки в ячейку уценки:
import urllib, json
def generate_toc(notebook_path, indent_char=" "):
is_markdown = lambda it: "markdown" == it["cell_type"]
is_title = lambda it: it.strip().startswith("#") and it.strip().lstrip("#").lstrip()
with open(notebook_path, 'r') as in_f:
nb_json = json.load(in_f)
for cell in filter(is_markdown, nb_json["cells"]):
for line in filter(is_title, cell["source"]):
line = line.strip()
indent = indent_char * (line.index(" ") - 1)
title = line.lstrip("#").lstrip()
url = urllib.parse.quote(title.replace(" ", "-"))
out_line = f"{indent}[{title}](#{url})<br>\n"
print(out_line, end="")