Непоследовательный разбор зависимостей?
У меня есть следующие два предложения, которые я анализирую с использованием того же конвейера Stanford CoreNLP (3.8.0).
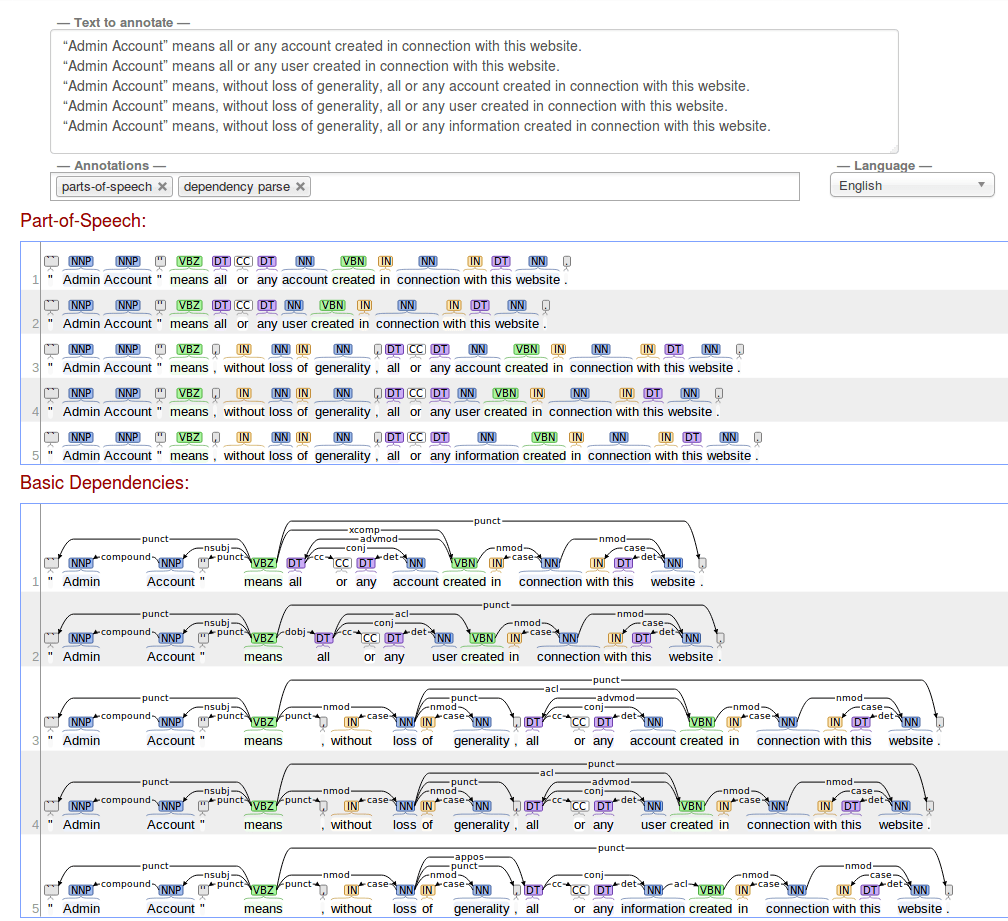
Что я не понимаю, так это то, почему анализатор зависимостей строит разные деревья, хотя предложения грамматически идентичны. Есть ли способ обеспечить последовательность?
Пример 1
S1: “Admin Account” means all or any account created in connection with this website.
S2: “Admin Account” means all or any user created in connection with this website.
S3: “Admin Account” means all or any cat created in connection with this website.
S4: “Admin Account” means all or any dog created in connection with this website.
Они разбираются на следующее:


Пример 2
Вот еще один пример использования варианта того же предложения, которое вводит именную фразу.
Вот как я запускаю сервер corenlp
java -mx20g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9001 -timeout 35000 -parse.model edu/stanford/nlp/models/srparser/englishSR.beam.ser.gz -tokenize.language en -tagger edu/stanford/nlp/models/pos-tagger/english-bidirectional/english-bidirectional-distsim.tagger -depparse.model edu/stanford/nlp/models/parser/nndep/english_SD.gz
1 ответ
Ответ прост, но, вероятно, весьма разочаровывает: Stanford CoreNLP управляется сложной статистической моделью, обученной на аннотированных вручную примерах (как и все современные анализаторы зависимостей), поэтому иногда он выводит разные структуры для разных входных данных, иногда даже если они очень похожи и имеют фактически одинаковую базовую структуру. Насколько я знаю, нет правил, которые бы обеспечивали согласованное поведение, просто ожидается, что огромное количество последовательно аннотированных обучающих данных приводит к согласованности в большинстве реальных случаев (и так бывает, не так ли?).
Внутренне синтаксический анализатор взвешивает доказательства для многих анализируемых кандидатов, и множество факторов могут влиять на это. Вы можете представить это как различные структуры, борющиеся за выбор. Иногда два альтернативных чтения могут иметь очень похожие вероятности, назначенные синтаксическим анализатором. В таких ситуациях даже очень небольшие различия в других частях предложения могут повлиять на окончательное решение о маркировке и прикреплении, которое имеет место в других частях (например, эффект бабочки).
Аккаунт - это неодушевленное существительное, которое, вероятно, чаще всего используется как объект или в пассивных конструкциях. Пользователь обычно одушевлен, поэтому он скорее будет играть роль агена. Трудно догадаться, что именно "думает" синтаксический анализатор, когда видит эти предложения, но контекст, в котором обычно появляются существительные, может играть решающую роль (CoreNLP также имеет дело с встраиванием слов).
Что вы можете сделать для обеспечения согласованности? Теоретически вы можете добавить дополнительные учебные примеры в учебный корпус и самостоятельно обучить анализатор (упомянуто здесь: https://nlp.stanford.edu/software/nndep.shtml). Я думаю, что это может быть не тривиально, я также не уверен, что оригинальный учебный корпус общедоступен. Некоторые парсеры предлагают возможность посттренировки существующей модели. Я столкнулся с проблемами, похожими на ваши, и сумел их преодолеть с помощью пост-тренинга в анализаторе зависимостей Spacy (см. Обсуждение в https://github.com/explosion/spaCy/issues/1015 если вам интересно).
Что могло произойти в этих примерах?
Каждый из них был неправильно маркирован. Я думаю, что главный глагол "средства" должен указывать на его клаузальное дополнение (предложение, начинающееся с "создано") с ccomp зависимость ( http://universaldependencies.org/u/dep/ccomp.html), но этого просто не произошло. Возможно, что еще более важно, "все или любой счет" должен быть предметом этого пункта, который также не отражен ни в одной из этих структур. Парсер догадался, что эта фраза является либо модификатором наречий (что довольно странно), либо прямым объектом (учетная запись означает все). Я предполагаю, что на связывание "средств" с его иждивенцами сильно влияют другие догадки парсера (это сложная вероятностная модель, все решения, принятые в предложении, могут влиять на вероятность решений, принятых в других частях).