Python Web API - время ожидания без очереди с Celery & RabbitMQ
Я построил веб-API на основе Python, используя nginx и uWSGI, который обрабатывает приблизительно 100-200 RPS (запросов в секунду) со временем ответа 100-300 мс. При получении запроса API приложение запускает один или несколько внутренних вызовов API к другим источникам данных через geventHTTPclient, а затем объединяет данные для ответа на первоначальный запрос.
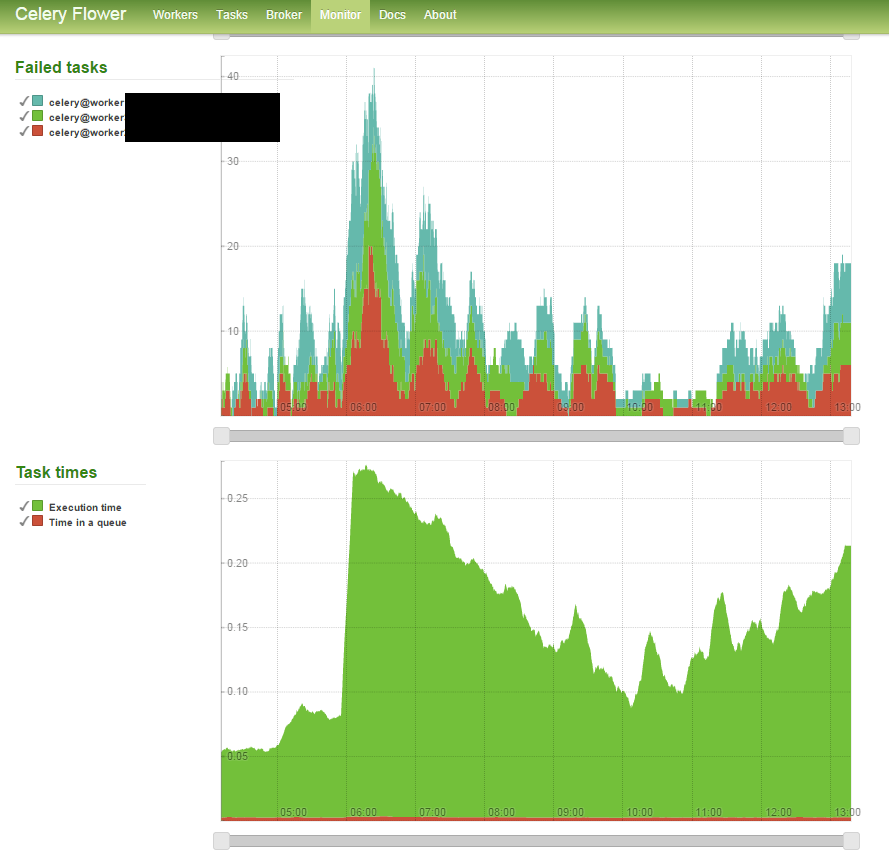
В недавнем обновлении кода я перегрузил эти вызовы API бэкэнда в Celery (используя libRabbitMQ в качестве моего брокера). Когда я выпускаю этот код в производство, результаты изначально приемлемы - среднее время отклика слегка увеличивается из-за внешней задержки из источников данных 2+, но время загрузки приложения примерно такое же. Однако со временем я заметил серьезное снижение задержки моего API до 10-кратной начальной задержки, что в основном связано с увеличением времени ожидания в очереди (см. График ниже). Я экспериментировал с конфигами сельдерея и использую следующее:
CELERY_MAX_CACHED_RESULTS = -1
CELERY_TASK_RESULT_EXPIRES=30
CELERYD_MAX_TASKS_PER_CHILD=5000
BROKER_URL = 'librabbitmq://guest@localhost//'
CELERY_RESULT_BACKEND = 'amqp://'
CELERYD_TASK_SOFT_TIME_LIMIT=1
CELERYD_TASK_TIME_LIMIT=2
CELERYD_WORKER_LOST_WAIT=2
CELERYD_PREFETCH_MULTIPLIER=16
Я также управляю 4 uWSGI одновременно / предварительно разветвленными, с 10 одновременно работающими сельдереями. Я замечаю, что это также происходит, когда я увеличиваю количество работников сельдерея до 16, но системные ресурсы (ЦП) начинают максимально увеличиваться.
Существуют ли другие параметры Celery/RabbitMQ, которые я могу настроить, чтобы попытаться улучшить это? Неудачные задачи, по-видимому, коррелируют с увеличением времени ожидания в очереди, что может иметь смысл, если учесть, что работники заняты неудачными задачами и не могут очистить очередь. Почти как каскадный эффект. Мне просто нужно больше работников на лучшую коробку?

Обновление 1: я выполнил второй тест со следующими настройками и небольшой модификацией кода моего приложения, чтобы уменьшить нагрузку на очередь. Похоже, что все шло гладко, пока какое-то "событие" не произошло примерно через два часа после начала теста. Есть ли что-нибудь еще, что я могу использовать для мониторинга других аспектов очереди?
CELERY_MAX_CACHED_RESULTS = -1
CELERY_TASK_RESULT_EXPIRES=10
CELERYD_MAX_TASKS_PER_CHILD=5000
BROKER_URL = 'librabbitmq://guest@localhost//'
BROKER_POOL_LIMIT = 2000
CELERY_RESULT_BACKEND = 'amqp://'
CELERYD_TASK_SOFT_TIME_LIMIT=1
CELERYD_TASK_TIME_LIMIT=1.2
CELERYD_WORKER_LOST_WAIT=2
CELERYD_TIMER_PRECISION=0.1
CELERYD_PREFETCH_MULTIPLIER=2

Обновление 2: я увеличил количество рабочих процессов (3 рабочих с 10 одновременными потоками nohup celery -A tasks worker --loglevel=error --concurrency=10 -n worker1.%h &) и увидел гораздо большую стабильность, однако примерно через 2 часа произошел всплеск ошибок в запросах API, что привело к значительному увеличению задержки в моем приложении.
Что странно, так это то, что я жестко запрограммировал 3 уровня времени ожидания:
- В моем
geventhttpclientHTTPClient (network_latency = .8s) на уровне задач - SoftTimeOut сельдерея = 1,0 с
- Время сельдерея (хард)TimeOut = 1,2
В случае сбоев эти ограничения должны обеспечивать надежное смягчение, но, очевидно, нет. Я также пытался перезапустить своих работников из сельдерея на лету, но это тоже не сработало.

Обновление 3 - Не повезло при обмене geventhttpclient как мой модуль HTTP-запроса и используя просто httplib, Также увеличено до --concurrenty=18 для этого испытания. Смотрите картинку ниже:
Я застрял на этом этапе...