Извлечение результатов Google Scholar с использованием Python (или R)
Я хотел бы использовать Python, чтобы очистить результаты поиска Google ученый. Я нашел два разных скрипта для этого, один gscholar.py, а другой scholar.py (Может ли он быть использован в качестве библиотеки Python?).
Теперь я должен сказать, что я совершенно новичок в python, так что извините, если я пропускаю очевидное!
Проблема в том, когда я использую gscholar.py как объясняется в файле README, я получаю в результате
query() takes at least 2 arguments (1 given),
Даже когда я указываю другой аргумент (например, gscholar.query("my query", allresults=True), Я получил
query() takes at least 2 arguments (2 given),
Это озадачивает меня. Я также попытался указать третий возможный аргумент (outformat=4; который является форматом BibTex), но это дает мне список ошибок функций. Коллега посоветовал мне импортировать BeautifulSoup и это перед выполнением запроса, но это также не меняет проблему. Любые предложения, как решить проблему?
Я нашел код для R (см. Ссылку) в качестве решения, но был быстро заблокирован Google. Может быть, кто-то может предложить, как улучшить этот код, чтобы избежать блокировки? Любая помощь будет оценена! Спасибо!
8 ответов
Я предлагаю вам не использовать определенные библиотеки для сканирования определенных веб-сайтов, а использовать библиотеки HTML общего назначения, которые хорошо протестированы и имеют хорошо оформленную документацию, такую как BeautifulSoup.
Для доступа к веб-сайтам с информацией о браузере вы можете использовать класс открывания URL с пользовательским агентом:
from urllib import FancyURLopener
class MyOpener(FancyURLopener):
version = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.152 Safari/537.36'
openurl = MyOpener().open
А затем загрузите нужный URL-адрес следующим образом:
openurl(url).read()
Для получения результатов ученого просто используйте http://scholar.google.se/scholar?hl=en&q=${query} URL-адрес.
Чтобы извлечь фрагменты информации из полученного HTML-файла, вы можете использовать этот фрагмент кода:
from bs4 import SoupStrainer, BeautifulSoup
page = BeautifulSoup(openurl(url).read(), parse_only=SoupStrainer('div', id='gs_ab_md'))
Этот фрагмент кода извлекает конкретный div элемент, содержащий количество результатов, отображаемых на странице результатов поиска Google Scholar.
Google заблокирует вас... так как будет очевидно, что вы не браузер. А именно, они будут обнаруживать одну и ту же сигнатуру запроса, возникающую слишком часто для человеческой деятельности....
Ты можешь сделать:
- Как сделать urllib2-запросы через Tor в Python?
- Запустите код на своих университетских компьютерах (может не помочь)
- Использование Google scholar API может стоить вам денег и не предоставит вам полных функций, которые вы можете видеть как обычный человек.
Похоже, что работа с Python сводится к тому, что R сталкивается с проблемой, когда Google Scholar рассматривает ваш запрос как запрос робота из-за отсутствия в запросе пользовательского агента. В StackExchange существует аналогичный вопрос о загрузке всех файлов PDF, связанных с веб-страницей, и ответ приводит пользователя к wget в Unix и к пакету BeautifulSoup в Python.
Керл также кажется более перспективным направлением.
COPython выглядит правильно, но вот небольшое объяснение на примере...
Рассмотрим f:
def f(a,b,c=1):
pass
f ожидает значения для a и b, несмотря ни на что. Вы можете оставить c пустым.
f(1,2) #executes fine
f(a=1,b=2) #executes fine
f(1,c=1) #TypeError: f() takes at least 2 arguments (2 given)
Тот факт, что вы заблокированы Google, возможно, связан с настройками вашего пользовательского агента в заголовке... Я не знаком с R, но могу дать вам общий алгоритм исправления этого:
- используйте обычный браузер (firefox или любой другой) для доступа к URL при мониторинге трафика HTTP (мне нравится wireshark)
- принять к сведению все заголовки, отправленные в соответствующем запросе http
- попробуйте запустить ваш скрипт, а также обратите внимание на заголовки
- Найди отличие
- установите свой R-скрипт, чтобы использовать заголовки, которые вы видели при проверке трафика браузера
Идеальный сценарий — это когда у вас хорошие прокси, в идеале резидентные, которые позволят выбрать конкретную локацию (страну, город или мобильного оператора) и сервис по разгадыванию CAPTCHA.
В качестве альтернативного решения вы можете использовать Google Scholar API от SerpApi.
Это платный API с бесплатным планом, который обходит блокировки от Google с помощью прокси-серверов и решений для решения CAPTCHA, может масштабироваться до уровня предприятия, плюс конечному пользователю не нужно создавать парсер с нуля и поддерживать его с течением времени, если что-то в HTML изменен.
Кроме того, он поддерживает результаты cite , profile , author .
Пример кода для интеграции для анализа органических результатов:
import json
from serpapi import GoogleScholarSearch
params = {
"api_key": "Your SerpAPi API KEY",
"engine": "google_scholar",
"q": "biology",
"hl": "en"
}
search = GoogleScholarSearch(params)
results = search.get_dict()
for result in results["organic_results"]:
print(json.dumps(result, indent=2))
# first organic results output:
'''
{
"position": 0,
"title": "The biology of mycorrhiza.",
"result_id": "6zRLFbcxtREJ",
"link": "https://www.cabdirect.org/cabdirect/abstract/19690600367",
"snippet": "In the second, revised and extended, edition of this work [cf. FA 20 No. 4264], two new chapters have been added (on carbohydrate physiology physiology Subject Category \u2026",
"publication_info": {
"summary": "JL Harley - The biology of mycorrhiza., 1969 - cabdirect.org"
},
"inline_links": {
"serpapi_cite_link": "https://serpapi.com/search.json?engine=google_scholar_cite&q=6zRLFbcxtREJ",
"cited_by": {
"total": 704,
"link": "https://scholar.google.com/scholar?cites=1275980731835430123&as_sdt=5,50&sciodt=0,50&hl=en",
"cites_id": "1275980731835430123",
"serpapi_scholar_link": "https://serpapi.com/search.json?as_sdt=5%2C50&cites=1275980731835430123&engine=google_scholar&hl=en"
},
"related_pages_link": "https://scholar.google.com/scholar?q=related:6zRLFbcxtREJ:scholar.google.com/&scioq=biology&hl=en&as_sdt=0,50",
"versions": {
"total": 4,
"link": "https://scholar.google.com/scholar?cluster=1275980731835430123&hl=en&as_sdt=0,50",
"cluster_id": "1275980731835430123",
"serpapi_scholar_link": "https://serpapi.com/search.json?as_sdt=0%2C50&cluster=1275980731835430123&engine=google_scholar&hl=en"
},
"cached_page_link": "https://scholar.googleusercontent.com/scholar?q=cache:6zRLFbcxtREJ:scholar.google.com/+biology&hl=en&as_sdt=0,50"
}
}
... other results
'''
Также есть специальные исторические результаты Scrape Google Scholar с использованием Python в моем блоге SerpApi.
Отказ от ответственности, я работаю в SerpApi.
Вот подпись вызова запроса ()...
def query(searchstr, outformat, allresults=False)
таким образом, вам нужно указать searchstr И как минимум outformat, а allresults - необязательный флаг / аргумент.
Вы можете использовать Greasemonkey для этой задачи. Преимущество состоит в том, что Google не сможет обнаружить вас как бота, если вы дополнительно снизите частоту запросов. Вы также можете посмотреть скрипт, работающий в окне вашего браузера.
Вы можете научиться кодировать его самостоятельно или использовать скрипт из одного из этих источников.
Раскрытие информации: я работаю в SerpApi.
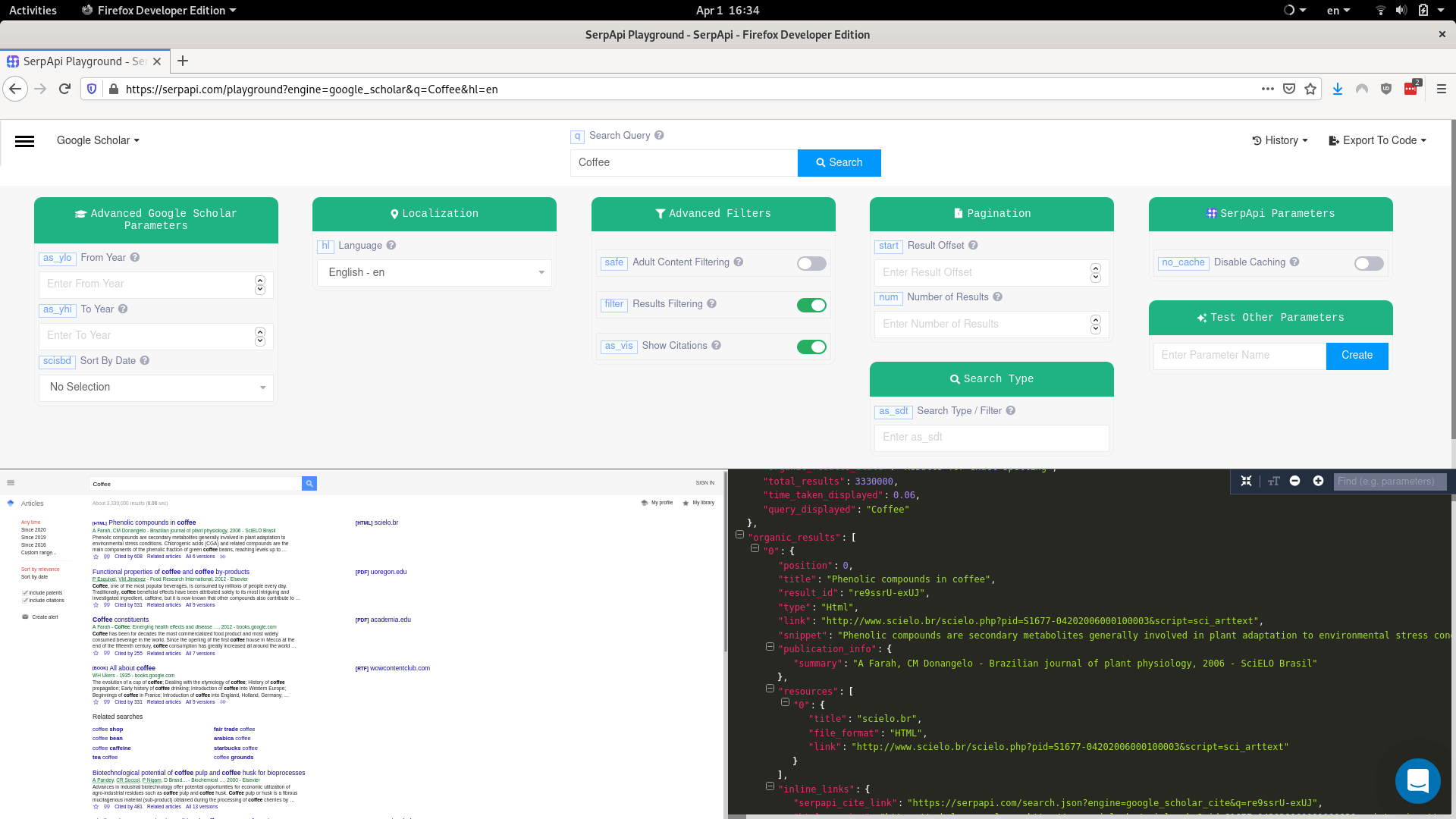
Вы можете использовать google-search-results пакет для извлечения данных из Google Scholar. Проверить демо на Repl.it.
from serpapi.google_search_results import GoogleSearchResults
params = {
"engine": "google_scholar",
"q": "coffee",
}
client = GoogleSearchResults(params)
data = client.get_dict()
print("Organic results\n")
for result in data['organic_results']:
print(f"""Title: {result['title']}
Result ID: {result['result_id']}
Link: {result['link']}
""")
отклик
{
"organic_results": [
{
"position": 0,
"title": "Phenolic compounds in coffee",
"result_id": "re9ssrU-exUJ",
"type": "Html",
"link": "http://www.scielo.br/scielo.php?pid=S1677-04202006000100003&script=sci_arttext",
"snippet": "Phenolic compounds are secondary metabolites generally involved in plant adaptation to environmental stress conditions. Chlorogenic acids (CGA) and related compounds are the main components of the phenolic fraction of green coffee beans, reaching levels up to …",
"publication_info": {
"summary": "A Farah, CM Donangelo - Brazilian journal of plant physiology, 2006 - SciELO Brasil"
},
"resources": [
{
"title": "scielo.br",
"file_format": "HTML",
"link": "http://www.scielo.br/scielo.php?pid=S1677-04202006000100003&script=sci_arttext"
}
],
"inline_links": {
"serpapi_cite_link": "https://serpapi.com/search.json?engine=google_scholar_cite&q=re9ssrU-exUJ",
"html_version": "https://scholar.google.comhttp://www.scielo.br/scielo.php?pid=S1677-04202006000100003&script=sci_arttext",
"cited_by": {
"total": 608,
"link": "https://scholar.google.com/scholar?cites=1547899847035383725&as_sdt=5,44&sciodt=0,44&hl=en",
"serpapi_scholar_link": "https://serpapi.com/search.json?cites=1547899847035383725&engine=google_scholar&hl=en&q=Coffee"
},
"related_pages_link": "https://scholar.google.com/scholar?q=related:re9ssrU-exUJ:scholar.google.com/&scioq=Coffee&hl=en&as_sdt=0,44",
"versions": {
"total": 6,
"link": "https://scholar.google.com/scholar?cluster=1547899847035383725&hl=en&as_sdt=0,44",
"serpapi_scholar_link": "https://serpapi.com/search.json?cluster=1547899847035383725&engine=google_scholar&hl=en&q=Coffee"
},
"cached_page_link": "https://scholar.google.comhttp://scholar.googleusercontent.com/scholar?q=cache:re9ssrU-exUJ:scholar.google.com/+Coffee&hl=en&as_sdt=0,44"
}
},
{
"position": 1,
"title": "Functional properties of coffee and coffee by-products",
"result_id": "9WouRiFbIK4J",
"link": "https://www.sciencedirect.com/science/article/pii/S0963996911003449",
"snippet": "Coffee, one of the most popular beverages, is consumed by millions of people every day. Traditionally, coffee beneficial effects have been attributed solely to its most intriguing and investigated ingredient, caffeine, but it is now known that other compounds also contribute to …",
"publication_info": {
"summary": "P Esquivel, VM Jiménez - Food Research International, 2012 - Elsevier",
"authors": [
{
"name": "P Esquivel",
"link": "https://scholar.google.com/citations?user=EpwJXskAAAAJ&hl=en&oi=sra"
},
{
"name": "VM Jiménez",
"link": "https://scholar.google.com/citations?user=_P0h0B8AAAAJ&hl=en&oi=sra"
}
]
},
"resources": [
{
"title": "uoregon.edu",
"file_format": "PDF",
"link": "https://pages.uoregon.edu/chendon/coffee_literature/2012%20Food%20Res.%20Int.,%20Uses%20for%20coffee%20waste.pdf"
}
],
"inline_links": {
"serpapi_cite_link": "https://serpapi.com/search.json?engine=google_scholar_cite&q=9WouRiFbIK4J",
"cited_by": {
"total": 531,
"link": "https://scholar.google.com/scholar?cites=12547128760323697397&as_sdt=5,44&sciodt=0,44&hl=en",
"serpapi_scholar_link": "https://serpapi.com/search.json?cites=12547128760323697397&engine=google_scholar&hl=en&q=Coffee"
},
"related_pages_link": "https://scholar.google.com/scholar?q=related:9WouRiFbIK4J:scholar.google.com/&scioq=Coffee&hl=en&as_sdt=0,44",
"versions": {
"total": 9,
"link": "https://scholar.google.com/scholar?cluster=12547128760323697397&hl=en&as_sdt=0,44",
"serpapi_scholar_link": "https://serpapi.com/search.json?cluster=12547128760323697397&engine=google_scholar&hl=en&q=Coffee"
}
}
},
{
"position": 2,
"title": "Coffee constituents",
"result_id": "xY3q9qnkN54J",
"link": "https://books.google.com/books?hl=en&lr=&id=y0qA89vCr3MC&oi=fnd&pg=PT47&dq=Coffee&ots=pyKSUohpI7&sig=8qULQFDS2RydGAkXlRyVJoph4AU",
"snippet": "Coffee has been for decades the most commercialized food product and most widely consumed beverage in the world. Since the opening of the first coffee house in Mecca at the end of the fifteenth century, coffee consumption has greatly increased all around the world …",
"publication_info": {
"summary": "A Farah - Coffee: Emerging health effects and disease …, 2012 - books.google.com"
},
"resources": [
{
"title": "academia.edu",
"file_format": "PDF",
"link": "http://www.academia.edu/download/52419982/IFTPressBook_Coffee_PreviewChapter.pdf"
}
],
"inline_links": {
"serpapi_cite_link": "https://serpapi.com/search.json?engine=google_scholar_cite&q=xY3q9qnkN54J",
"cited_by": {
"total": 255,
"link": "https://scholar.google.com/scholar?cites=11400832400354872773&as_sdt=5,44&sciodt=0,44&hl=en",
"serpapi_scholar_link": "https://serpapi.com/search.json?cites=11400832400354872773&engine=google_scholar&hl=en&q=Coffee"
},
"related_pages_link": "https://scholar.google.com/scholar?q=related:xY3q9qnkN54J:scholar.google.com/&scioq=Coffee&hl=en&as_sdt=0,44",
"versions": {
"total": 7,
"link": "https://scholar.google.com/scholar?cluster=11400832400354872773&hl=en&as_sdt=0,44",
"serpapi_scholar_link": "https://serpapi.com/search.json?cluster=11400832400354872773&engine=google_scholar&hl=en&q=Coffee"
}
}
}
]
}
Выход
Organic results
Title: Phenolic compounds in coffee
Result ID: re9ssrU-exUJ
Link: http://www.scielo.br/scielo.php?pid=S1677-04202006000100003&script=sci_arttext
Title: Functional properties of coffee and coffee by-products
Result ID: 9WouRiFbIK4J
Link: https://www.sciencedirect.com/science/article/pii/S0963996911003449
Title: Coffee constituents
Result ID: xY3q9qnkN54J
Link: https://books.google.com/books?hl=en&lr=&id=y0qA89vCr3MC&oi=fnd&pg=PT47&dq=coffee&ots=pyKSUokkMc&sig=sjDv_w50O-5_svJDJKPJ7hHJtRg
Title: All about coffee
Result ID: fGeQlvu-2_IJ
Link: https://books.google.com/books?hl=en&lr=&id=oJxpQX4ko7cC&oi=fnd&pg=PT1&dq=coffee&ots=Oih_E-45Y-&sig=KYyBOoSXwRdwOv5upyWwl0FzIq8
Title: Biotechnological potential of coffee pulp and coffee husk for bioprocesses
Result ID: Zu7aKNjvAUwJ
Link: https://www.sciencedirect.com/science/article/pii/S1369703X0000084X
Title: Biodiversity conservation in traditional coffee systems of Mexico
Result ID: pIjQPO7__AYJ
Link: https://conbio.onlinelibrary.wiley.com/doi/abs/10.1046/j.1523-1739.1999.97153.x
Title: Coffee flavor chemistry
Result ID: UwtLySK5iawJ
Link: https://books.google.com/books?hl=en&lr=&id=NQi1LYJxFvUC&oi=fnd&pg=PP13&dq=coffee&ots=dRSace3WYu&sig=5jyqtvqkL_jGDkWTLsLqksKiQUw
Title: Coffee and health: a review of recent human research
Result ID: fSVlrXX7dIUJ
Link: https://www.tandfonline.com/doi/abs/10.1080/10408390500400009
Title: M-Coffee: combining multiple sequence alignment methods with T-Coffee
Result ID: _3o-xhuGyg0J
Link: https://academic.oup.com/nar/article-abstract/34/6/1692/2401531
Title: Producing decaffeinated coffee plants
Result ID: VJySkcFsQ1EJ
Link: https://www.nature.com/articles/423823a
Если вам нужна дополнительная информация, посмотрите документацию SerpApi или живую площадку.