Как работает хеш-таблица?
Я ищу объяснение того, как работает хеш-таблица - на простом английском языке для простого человека, как я!
Например, я знаю, что он берет ключ, вычисляет хеш (я ищу объяснение, как), а затем выполняет какой-то модуль по модулю, чтобы определить, где он находится в массиве, где хранится значение, но на этом мои знания останавливаются.,
Кто-нибудь может прояснить этот процесс?
Изменить: я не спрашиваю конкретно о том, как вычисляются хэш-коды, но общий обзор того, как работает хэш-таблица.
17 ответов
Вот объяснение с точки зрения непрофессионала.
Предположим, вы хотите заполнить библиотеку книгами, а не просто запихивать их туда, а хотите иметь возможность легко найти их снова, когда они вам понадобятся.
Итак, вы решаете, что если человек, который хочет прочитать книгу, знает название книги и точное название для загрузки, то это все, что нужно. С таким названием человек с помощью библиотекаря должен легко и быстро найти книгу.
Итак, как вы можете это сделать? Ну, очевидно, вы можете хранить какой-то список того, куда вы положили каждую книгу, но тогда у вас возникнет та же проблема, что и при поиске в библиотеке, вам нужно выполнить поиск в списке. Конечно, список будет меньше и его легче будет искать, но все же вы не хотите выполнять последовательный поиск от одного конца библиотеки (или списка) к другому.
Вы хотите что-то, что, с названием книги, может дать вам правильное место сразу, поэтому все, что вам нужно сделать, это просто прогуляться к правой полке и забрать книгу.
Но как это можно сделать? Ну, с некоторой предусмотрительностью, когда вы заполняете библиотеку, и большой работой, когда вы заполняете библиотеку.
Вместо того, чтобы просто начинать заполнять библиотеку с одного конца до другого, вы разрабатываете маленький умный метод. Вы берете название книги, запускаете ее через небольшую компьютерную программу, которая выплевывает номер полки и номер слота на этой полке. Здесь вы размещаете книгу.
Прелесть этой программы в том, что позже, когда человек возвращается, чтобы прочитать книгу, вы снова вводите название программы и возвращаете тот же номер полки и номер слота, которые были вам изначально предоставлены, и это где находится книга
Программа, как уже упоминали другие, называется хеш-алгоритмом или хеш-вычислением и обычно работает, беря данные, введенные в нее (в данном случае название книги), и вычисляет число из нее.
Для простоты предположим, что он просто преобразует каждую букву и символ в число и суммирует их все. На самом деле, все намного сложнее, но давайте пока остановимся на этом.
Прелесть такого алгоритма в том, что если вы снова и снова вводите один и тот же вход, он будет каждый раз выплевывать одно и то же число.
Итак, вот как работает хеш-таблица.
Технические вещи следует.
Во-первых, есть размер числа. Обычно выходные данные такого алгоритма хеширования находятся в пределах некоторого большого числа, обычно намного большего, чем пространство, которое у вас есть в вашей таблице. Например, предположим, что в библиотеке есть место для ровно миллиона книг. Результат вычисления хеша может быть в диапазоне от 0 до одного миллиарда, что намного выше.
Так что же нам делать? Мы используем то, что называется модульным вычислением, которое в основном говорит о том, что если вы сосчитали до нужного вам числа (т. Е. До одного миллиарда), но хотели остаться в гораздо меньшем диапазоне, каждый раз, когда вы достигаете предела этого меньшего диапазона, с которого вы начинали. 0, но вы должны следить за тем, как далеко в большой последовательности вы прошли.
Скажем, выходной результат алгоритма хеширования находится в диапазоне от 0 до 20, и вы получите значение 17 из определенного заголовка. Если размер библиотеки составляет всего 7 книг, вы считаете 1, 2, 3, 4, 5, 6, а когда вы добираетесь до 7, вы начинаете с нуля. Так как нам нужно сосчитать 17 раз, у нас есть 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, и окончательное число равно 3.
Конечно, вычисление модуля не делается так, оно выполняется с делением и остатком. Остаток от деления 17 на 7 равен 3 (7 переходит 2 раза в 17 в 14, а разница между 17 и 14 равна 3).
Таким образом, вы положили книгу в слот № 3.
Это приводит к следующей проблеме. Столкновения. Поскольку алгоритм не имеет возможности разнести книги так, чтобы они точно заполняли библиотеку (или, если хотите, хэш-таблицу), он неизменно будет вычислять число, которое использовалось ранее. В библиотечном смысле, когда вы доберетесь до полки и с номером слота, в который хотите положить книгу, там уже есть книга.
Существуют различные методы обработки столкновений, в том числе ввод данных в еще одно вычисление для получения другого места в таблице ( двойное хеширование) или просто для поиска пространства, близкого к тому, которое вам было дано (т. Е. Прямо рядом с предыдущей книгой, предполагая наличие слота). был также доступен как линейное зондирование). Это будет означать, что вам придется покопаться, когда вы попытаетесь найти книгу позже, но это все же лучше, чем просто начинать с одного конца библиотеки.
Наконец, в какой-то момент вы можете поместить в библиотеку больше книг, чем позволяет библиотека. Другими словами, вам нужно построить большую библиотеку. Поскольку точное место в библиотеке было рассчитано с использованием точного и текущего размера библиотеки, из этого следует, что если вы измените размер библиотеки, вам может понадобиться найти новые места для всех книг, так как вычисление сделано, чтобы найти их места изменился
Я надеюсь, что это объяснение было немного более приземленным, чем ведра и функции:)
Использование и Линго:
- Хеш-таблицы используются для быстрого хранения и извлечения данных (или записей).
- Записи хранятся в корзинах с использованием хэш-ключей.
- Хеш-ключи рассчитываются путем применения алгоритма хеширования к выбранному значению (значению ключа), содержащемуся в записи. Это выбранное значение должно быть общим для всех записей.
- Каждое ведро может иметь несколько записей, которые организованы в определенном порядке.
Пример из реального мира:
Компания Hash & Co., основанная в 1803 году и не обладающая какими-либо компьютерными технологиями, имела в общей сложности 300 картотек для хранения подробной информации (записей) примерно для 30000 своих клиентов. Каждая папка с файлами была четко обозначена своим номером клиента, уникальным номером от 0 до 29 999.
Клерки регистрации того времени должны были быстро получить и сохранить записи клиентов для рабочего персонала. Сотрудники решили, что было бы более эффективно использовать методологию хеширования для хранения и извлечения своих записей.
Чтобы подать клиентскую запись, регистраторы должны использовать уникальный номер клиента, указанный в папке. Используя этот номер клиента, они будут модулировать хеш-ключ на 300, чтобы идентифицировать шкаф хранения, в котором он содержится. Когда они откроют шкаф хранения, они обнаружат, что он содержит много папок, упорядоченных по номеру клиента. После определения правильного местоположения они просто вставят его.
Чтобы получить запись о клиенте, клерки должны были получить номер клиента на листе бумаги. Используя этот уникальный клиентский номер (хеш-ключ), они будут модулировать его на 300, чтобы определить, в каком картотеке есть папка клиентов. Открыв картотеку, они обнаружат, что в ней много папок, упорядоченных по номеру клиента. Просматривая записи, они быстро находят папку клиента и извлекают ее.
В нашем примере из реального мира наши ведра - это шкафы для документов, а наши записи - это папки с файлами.
Важно помнить, что компьютеры (и их алгоритмы) работают с числами лучше, чем со строками. Таким образом, доступ к большому массиву с использованием индекса значительно быстрее, чем последовательный доступ.
Как уже упоминал Саймон, я считаю, что очень важным является то, что часть хеширования должна преобразовывать большое пространство (произвольной длины, обычно строки и т. Д.) И отображать его в небольшом пространстве (известного размера, обычно числа) для индексации. Это очень важно запомнить!
Таким образом, в приведенном выше примере 30000 возможных клиентов или около того сопоставляются с меньшим пространством.
Основная идея в этом состоит в том, чтобы разделить весь ваш набор данных на сегменты, чтобы ускорить фактический поиск, который обычно занимает много времени. В нашем примере выше каждый из 300 картотек (статистически) будет содержать около 100 записей. Поиск (независимо от порядка) по 100 записям намного быстрее, чем поиск по 30000.
Возможно, вы заметили, что некоторые на самом деле уже делают это. Но вместо того, чтобы разрабатывать методологию хеширования для генерации хеш-ключа, они в большинстве случаев будут просто использовать первую букву фамилии. Таким образом, если у вас есть 26 шкафов для хранения документов, в каждом из которых есть буквы от А до Я, вы теоретически только что сегментировали свои данные и улучшили процесс регистрации и поиска.
Надеюсь это поможет,
Jeach!
Это оказывается довольно глубокая область теории, но основной план прост.
По сути, хеш-функция - это просто функция, которая берет вещи из одного пространства (скажем, строки произвольной длины) и отображает их в пространство, полезное для индексации (скажем, целые числа без знака).
Если у вас есть только небольшое пространство для хеширования, вам может быть просто интерпретировать эти вещи как целые числа, и все готово (например, 4-байтовые строки)
Обычно, однако, у вас есть гораздо больше места. Если пространство вещей, которое вы разрешаете использовать в качестве ключей, больше, чем пространство вещей, которое вы используете для индексации (ваш uint32 или любой другой), вы не можете иметь уникальное значение для каждого из них. Когда две или более вещи хешируют один и тот же результат, вам придется обрабатывать избыточность соответствующим образом (это обычно называется коллизией, и то, как вы ее обрабатываете или нет, будет немного зависеть от того, кто вы есть). используя хеш для).
Это означает, что вы вряд ли захотите получить такой же результат, и вам, вероятно, также хотелось бы, чтобы хеш-функция была быстрой.
Уравновешивание этих двух свойств (и нескольких других) заставило многих людей быть занятыми!
На практике вы, как правило, должны быть в состоянии найти функцию, которая, как известно, хорошо работает для вашего приложения, и использовать ее.
Теперь, чтобы сделать эту работу хеш-таблицей: представьте, что вы не заботитесь об использовании памяти. Затем вы можете создать массив, если ваш набор индексации (например, все uint32). Когда вы добавляете что-то в таблицу, вы хешируете ее ключ и смотрите на массив по этому индексу. Если там ничего нет, вы ставите там свою ценность. Если там уже что-то есть, вы добавляете эту новую запись в список вещей по этому адресу вместе с достаточным количеством информации (ваш оригинальный ключ или что-то умное), чтобы найти, какая запись на самом деле принадлежит какому ключу.
Таким образом, если вы идете длинным, каждая запись в вашей хеш-таблице (массив) либо пуста, либо содержит одну запись, либо список записей. Получение - это просто индексация в массиве, либо возвращение значения, либо просмотр списка значений и возврат правильного.
Конечно, на практике вы, как правило, не можете этого сделать, это тратит слишком много памяти. Таким образом, вы делаете все на основе разреженного массива (где единственными записями являются те, которые вы фактически используете, все остальное неявно равно нулю).
Есть много схем и приемов, чтобы сделать эту работу лучше, но это основа.
Много ответов, но ни один из них не очень нагляден, и хеш-таблицы могут легко "щелкнуть" при визуализации.
Хеш-таблицы часто реализуются как массивы связанных списков. Если мы представим таблицу с именами людей, то после нескольких вставок она может быть размещена в памяти, как показано ниже, где ()-замкнутые числа являются хеш-значениями текста / имени.
bucket# bucket content / linked list
[0] --> "sue"(780) --> null
[1] null
[2] --> "fred"(42) --> "bill"(9282) --> "jane"(42) --> null
[3] --> "mary"(73) --> null
[4] null
[5] --> "masayuki"(75) --> "sarwar"(105) --> null
[6] --> "margaret"(2626) --> null
[7] null
[8] --> "bob"(308) --> null
[9] null
Несколько моментов:
- каждая из записей массива (индексы
[0],[1]...) называется контейнером и запускает - возможно пустой - связанный список значений (иначе говоря, элементы, в этом примере - имена людей) - каждое значение (например,
"fred"с хешем42) связан с ведром[hash % number_of_buckets]например42 % 10 == [2];%является оператором модуля - остаток при делении на количество сегментов - несколько значений данных могут сталкиваться и связываться из одного сегмента, чаще всего потому, что их значения хеш-функции конфликтуют после операции модуля (например,
42 % 10 == [2], а также9282 % 10 == [2]), но иногда потому, что значения хеша одинаковы (например,"fred"а также"jane"оба показаны с хешем42выше)- большинство хеш-таблиц обрабатывают коллизии - с немного сниженной производительностью, но без функциональной путаницы - сравнивая полное значение (здесь текст) ключа, который ищется или вставляется с каждым ключом, уже имеющимся в связанном списке в корзине хэширования.
При увеличении размера таблицы хеш-таблицы, реализованные, как указано выше, имеют тенденцию к изменению размера самих себя (т.е. создают больший массив сегментов, создают новые / обновленные связанные списки оттуда, удаляют старый массив), чтобы сохранить соотношение элементов к сегментам (или загрузку). фактор) где-то в диапазоне от 0,5 до 1,0. С коэффициентом нагрузки 1 и хэш-функцией криптографической стойкости 36,8% корзин будут иметь тенденцию быть пустыми, еще 36,8% имеют один элемент, 18,4% два элемента, 6,1% три элемента, 1,5% четыре элемента, 0,3% пять и т. Д. - длина списка составляет в среднем 2,0 элемента независимо от того, сколько элементов в таблице (т. е. есть ли 100 элементов и 100 сегментов, или 100 миллионов элементов и 100 миллионов блоков), поэтому мы говорим, что lookup/insert/erase - O(1) операции с постоянным временем.
(Примечания: не во всех хеш-таблицах используются связанные списки, но большинство из них общего назначения используют, поскольку закрытое хеширование (иначе говоря, открытая адресация) - особенно с поддерживаемыми операциями стирания - имеет менее стабильные свойства производительности с подверженными коллизиям клавишами / хэш-функциями)
Несколько слов о хэш-функциях
Основная задача работы хеш-функции, минимизирующей коллизии в худшем случае, заключается в эффективном произвольном распределении ключей вокруг блоков хеш-таблиц при одновременном создании одинакового значения хеш-функции для одного и того же ключа. Даже один бит, изменяющийся в любом месте ключа, в идеале - случайным образом - переворачивает примерно половину битов в результирующем хэш-значении.
Это обычно организовано с математикой, слишком сложной для меня, чтобы впасть. Я упомяну один простой для понимания способ - не самый масштабируемый или дружественный к кэшу, но по своей природе элегантный (например, шифрование с помощью одноразовой клавиатуры!) - так как я думаю, что он помогает вернуть желаемые качества, упомянутые выше. Скажем, вы хешировали 64-битную версию doubles - вы можете создать 8 таблиц, каждая из 256 случайных чисел (т.е. size_t random[8][256]), затем используйте каждый 8-битный /1-байтовый фрагмент doubleПредставление памяти для индексации в другую таблицу, XOR случайных чисел, которые вы ищете. При таком подходе легко увидеть, что где-то немного меняется double приводит к поиску другого случайного числа в одной из таблиц и совершенно некоррелированному конечному значению.
Тем не менее, хеш-функции многих библиотек пропускают целые числа через неизмененные, что в худшем случае крайне склонно к коллизиям, но есть надежда, что в довольно распространенном случае целочисленных ключей, которые имеют тенденцию к увеличению, они преобразуются в последовательные сегменты, оставляя меньше пустее, чем 36,8% случайного хэширования, и, следовательно, меньше коллизий и меньше длинных связанных списков встречных элементов, чем достигается случайными отображениями. Также здорово сэкономить время, необходимое для создания сильного хэша. Когда ключи не увеличиваются, есть надежда, что они будут достаточно случайными, им не понадобится сильная хеш-функция для полной рандомизации их размещения в сегментах.
Ну, это было менее весело и тяжелее, чем объяснение хеш-таблицы, но надеюсь, что это кому-нибудь поможет...
Вы, ребята, очень близки к тому, чтобы объяснить это полностью, но упускаете пару вещей. Хеш-таблица - это просто массив. Сам массив будет содержать что-то в каждом слоте. Как минимум, вы сохраните хэш-значение или само значение в этом слоте. В дополнение к этому вы также можете хранить связанный / связанный список значений, которые столкнулись в этом слоте, или вы можете использовать метод открытой адресации. Вы также можете сохранить указатель или указатели на другие данные, которые вы хотите извлечь из этого слота.
Важно отметить, что само хеш-значение обычно не указывает слот, в который нужно поместить значение. Например, хеш-значение может быть отрицательным целочисленным значением. Очевидно, что отрицательное число не может указывать на местоположение массива. Кроме того, значения хеш-функции будут во много раз больше, чем доступные слоты. Таким образом, другой хэш-таблица должна выполнить другое вычисление, чтобы выяснить, в какой слот должно входить значение. Это сделано с математической операцией модуля как:
uint slotIndex = hashValue % hashTableSize;
Это значение является ячейкой, в которую будет входить значение. При открытой адресации, если слот уже заполнен другим хеш-значением и / или другими данными, операция модуля будет запущена еще раз, чтобы найти следующий слот:
slotIndex = (remainder + 1) % hashTableSize;
Я полагаю, что могут быть и другие более продвинутые методы определения индекса слотов, но это наиболее распространенный метод, который я видел... заинтересовал бы другие, которые работают лучше.
При использовании метода модуля, если у вас есть таблица, скажем, размером 1000, любое хеш-значение от 1 до 1000 попадет в соответствующий слот. Любые отрицательные значения и любые значения, превышающие 1000, будут потенциально конфликтующими значениями слотов. Вероятность этого зависит как от метода хеширования, так и от количества элементов, добавляемых в хеш-таблицу. Как правило, рекомендуется делать размер хеш-таблицы таким, чтобы общее количество добавляемых к нему значений было равно примерно 70% его размера. Если ваша хеш-функция хорошо справляется с равномерным распределением, вы, как правило, будете сталкиваться с очень небольшим количеством коллизий между слотами и слотами или вообще без них, и она будет очень быстро выполнять операции поиска и записи. Если общее количество добавляемых значений заранее неизвестно, сделайте правильное предположение, используя любые средства, а затем измените размер вашей хеш-таблицы, как только количество добавленных к ней элементов достигнет 70% емкости.
Я надеюсь, что это помогло.
PS - в C# GetHashCode() Метод довольно медленный и приводит к коллизиям фактических значений при многих условиях, которые я тестировал. Для реального удовольствия создайте собственную хэш-функцию и старайтесь, чтобы она НИКОГДА не сталкивалась с конкретными данными, которые вы хэшируете, работает быстрее, чем GetHashCode, и имеет довольно равномерное распределение. Я сделал это, используя long вместо значений хеш-кода размера int, и он работал довольно хорошо на хеш-таблицах до 32 миллионов хеш-таблиц с 0 коллизиями. К сожалению, я не могу поделиться кодом, так как он принадлежит моему работодателю... но я могу показать, что это возможно для определенных областей данных. Когда вы можете достичь этого, хеш-таблица ОЧЕНЬ быстра.:)
Вот как это работает в моем понимании:
Вот пример: представьте всю таблицу в виде серии блоков. Предположим, у вас есть реализация с алфавитно-цифровыми хеш-кодами, и у вас есть одна корзина для каждой буквы алфавита. Эта реализация помещает каждый элемент, чей хеш-код начинается с определенной буквы в соответствующем сегменте.
Допустим, у вас есть 200 объектов, но только 15 из них имеют хэш-коды, начинающиеся с буквы "В". Хеш-таблицу нужно будет только искать и искать по 15 объектам в корзине "B", а не по всем 200 объектам.
Что касается вычисления хеш-кода, в этом нет ничего волшебного. Цель состоит в том, чтобы разные объекты возвращали разные коды и чтобы равные объекты возвращали одинаковые коды. Вы могли бы написать класс, который всегда возвращает одно и то же целое число, что и хеш-код для всех экземпляров, но вы по существу уничтожили бы полезность хеш-таблицы, поскольку она просто превратилась бы в одно гигантское ведро.
Коротко и сладко:
Хеш-таблица оборачивает массив, давайте его назовем internalArray, Элементы вставляются в массив следующим образом:
let insert key value =
internalArray[hash(key) % internalArray.Length] <- (key, value)
//oversimplified for educational purposes
Иногда два ключа хешируют один и тот же индекс в массиве, и вы хотите сохранить оба значения. Мне нравится хранить оба значения в одном индексе, который легко кодировать, сделав internalArray массив связанных списков:
let insert key value =
internalArray[hash(key) % internalArray.Length].AddLast(key, value)
Итак, если бы я хотел извлечь элемент из моей хеш-таблицы, я мог бы написать:
let get key =
let linkedList = internalArray[hash(key) % internalArray.Length]
for (testKey, value) in linkedList
if (testKey = key) then return value
return null
Операции удаления так же просто написать. Как вы можете сказать, вставки, поиск и удаление из нашего массива связанных списков - это почти O(1).
Когда наш internalArray переполняется, возможно, на 85%, мы можем изменить размер внутреннего массива и переместить все элементы из старого массива в новый массив.
Это даже проще, чем это.
Хеш-таблица - это не что иное, как массив (обычно редкий) векторов, которые содержат пары ключ / значение. Максимальный размер этого массива обычно меньше, чем количество элементов в наборе возможных значений для типа данных, хранящихся в хеш-таблице.
Алгоритм хеширования используется для генерации индекса в этом массиве на основе значений элемента, которые будут сохранены в массиве.
Это место, где хранятся векторы пар ключ / значение в массиве. Поскольку набор значений, которые могут быть индексами в массиве, обычно меньше, чем число всех возможных значений, которые может иметь тип, возможно, ваш хэш Алгоритм будет генерировать одно и то же значение для двух отдельных ключей. Хороший алгоритм хеширования предотвратит это в максимально возможной степени (именно поэтому он обычно относится к типу, потому что у него есть конкретная информация, которую алгоритм хэширования не может знать), но это невозможно предотвратить.
Из-за этого вы можете иметь несколько ключей, которые будут генерировать один и тот же хэш-код. Когда это происходит, элементы в векторе перебираются, и выполняется прямое сравнение между ключом в векторе и ключом, который ищется. Если он найден, отлично и возвращается значение, связанное с ключом, в противном случае ничего не возвращается.
Вы берете кучу вещей и массив.
Для каждой вещи вы создаете для нее индекс, называемый хешем. Важным в хеше является то, что он много "разбрасывает"; Вы не хотите, чтобы две одинаковые вещи имели одинаковые хэши.
Вы помещаете свои вещи в массив в позиции, указанной хешем. При заданном хэше может оказаться более одной вещи, поэтому вы храните вещи в массивах или в чем-то другом, что мы обычно называем корзиной.
Когда вы просматриваете вещи в хэше, вы проделываете те же самые шаги, выясняете значение хеша, затем смотрите, что находится в корзине в этом месте, и проверяете, ищите ли вы.
Когда ваше хеширование работает хорошо, а ваш массив достаточно большой, в любом конкретном индексе в массиве будет не более нескольких вещей, поэтому вам не придется смотреть на это слишком много.
Для получения бонусных баллов сделайте так, чтобы при доступе к вашей хэш-таблице она перемещала найденную вещь (если таковая имеется) в начало корзины, поэтому в следующий раз она будет проверена первой.
Основная мысль
Почему люди используют комоды для хранения одежды? Помимо того, что они выглядят модно и стильно, у них есть то преимущество, что у каждого предмета одежды есть место, где он должен быть. Если вы ищете пару носков, просто загляните в ящик для носков. Если вы ищете рубашку, проверьте ящик, в котором лежат ваши рубашки. Когда вы ищете носки, не имеет значения, сколько у вас рубашек или пар брюк, потому что вам не нужно на них смотреть. Вы просто смотрите в ящик для носков и ожидаете найти там носки.
На высоком уровне хеш-таблица - это способ хранения вещей, который (вроде как) похож на комод для одежды. Основная идея заключается в следующем:
- Вы получаете некоторое количество мест (ящиков), где можно хранить предметы.
- Вы придумываете какое-то правило, которое говорит вам, к какому месту (ящику) принадлежит каждый предмет.
- Когда вам нужно что-то найти, вы используете это правило, чтобы определить, в какой ящик искать.
Преимущество такой системы в том, что, если ваше правило не слишком сложное и у вас есть соответствующее количество ящиков, вы можете довольно быстро найти то, что ищете, просто заглянув в нужное место.
Когда вы складываете одежду, вы можете использовать "правило" вроде "носки кладут в верхний левый ящик, а рубашки - в большой средний ящик и т. Д." Однако, когда вы храните более абстрактные данные, мы используем так называемую хеш-функцию, чтобы сделать это за нас.
Разумный способ думать о хэш-функции - это черный ящик. Вы помещаете данные в одну сторону, а число, называемое хеш-кодом, выходит из другой. Схематично это выглядит примерно так:
+---------+
|\| hash |/| --> hash code
data --> |/| function|\|
+---------+
Все хеш-функции детерминированы: если вы поместите одни и те же данные в функцию несколько раз, вы всегда получите одно и то же значение, выходящее с другой стороны. И хорошая хеш-функция должна выглядеть более или менее случайной: небольшие изменения во входных данных должны давать совершенно разные хеш-коды. Например, хэш-коды для строки "pudu" и для строки "kudu", вероятно, будут сильно отличаться друг от друга. (Опять же, возможно, что они такие же. В конце концов, если выходные данные хэш-функции должны выглядеть более или менее случайными, есть шанс, что мы получим один и тот же хеш-код дважды.)
Как именно построить хэш-функцию? А пока давайте посмотрим, что "порядочным людям не стоит слишком много думать об этом". Математики разрабатывали все лучшие и худшие способы разработки хэш-функций, но для наших целей нам действительно не нужно слишком беспокоиться о внутреннем устройстве. Достаточно хорошо думать о хэш-функции как о функции, которая
- детерминированный (равные входы дают равные выходы), но
- выглядит случайным (трудно предсказать один хэш-код по другому).
Когда у нас есть хеш-функция, мы можем построить очень простую хеш-таблицу. Мы сделаем ряд "ведер", которые можно рассматривать как аналог ящиков в нашем комоде. Чтобы сохранить элемент в хеш-таблице, мы вычислим хэш-код объекта и будем использовать его в качестве индекса в таблице, что аналогично "выбору ящика, в который помещается этот элемент". Затем мы помещаем этот элемент данных в корзину по этому индексу. Если это ведро было пустым, отлично! Мы можем положить туда предмет. Если это ведро заполнено, у нас есть несколько вариантов того, что мы можем сделать. Простой подход (называемый цепным хешированием) состоит в том, чтобы рассматривать каждое ведро как список элементов, так же, как ваш ящик для носков может хранить несколько носков, а затем просто добавить элемент в список по этому индексу.
Чтобы найти что-то в хеш-таблице, мы используем в основном ту же процедуру. Мы начинаем с вычисления хэш-кода для элемента, который нужно найти, который сообщает нам, в каком сегменте (ящике) искать. Если элемент находится в таблице, он должен быть в этом сегменте. Затем мы просто смотрим на все предметы в корзине и проверяем, есть ли там наш предмет.
В чем преимущество такого подхода? Что ж, предполагая, что у нас есть большое количество корзин, мы ожидаем, что в большинстве корзин не будет слишком много вещей. В конце концов, наша хеш-функция вроде как выглядит так, будто имеет случайные выходные данные, поэтому элементы распределяются вроде как равномерно по всем сегментам. Фактически, если мы формализуем понятие "наша хеш-функция выглядит как бы случайной", мы можем доказать, что ожидаемое количество элементов в каждом сегменте - это отношение общего количества элементов к общему количеству сегментов. Таким образом, мы можем найти то, что ищем, без особых усилий.
Детали
Объяснить, как работает "хеш-таблица", немного сложно, потому что существует множество разновидностей хеш-таблиц. В следующем разделе рассказывается о некоторых общих деталях реализации, общих для всех хэш-таблиц, а также о некоторых особенностях работы различных стилей хэш-таблиц.
Первый возникает вопрос: как превратить хэш-код в индекс слота таблицы. В приведенном выше обсуждении я просто сказал "используйте хэш-код в качестве индекса", но на самом деле это не очень хорошая идея. В большинстве языков программирования хэш-коды работают с 32-битными или 64-битными целыми числами, и вы не сможете использовать их напрямую в качестве индексов корзины. Вместо этого общая стратегия состоит в том, чтобы создать массив сегментов некоторого размера m, вычислить (полные 32- или 64-битные) хэш-коды для ваших элементов, а затем изменить их по размеру таблицы, чтобы получить индекс от 0 до м-1 включительно. Использование модуля здесь хорошо работает, потому что оно достаточно быстрое и выполняет достойную работу, распределяя полный диапазон хэш-кодов на меньший диапазон.
(Иногда здесь используются побитовые операторы. Если размер вашей таблицы равен степени двойки, скажем, 2k, то вычисление побитового AND хэш-кода, а затем umber 2k - 1 эквивалентно вычислению модуля, и это значительно быстрее.)
Следующий вопрос - как правильно выбрать количество ведер. Если вы выберете слишком много ведер, то большинство ведер будет пустым или будет содержать мало элементов (хорошо для скорости - вам нужно всего лишь проверить несколько элементов на ведро), но вы будете использовать кучу места, просто сохраняя ведра (не так отлично, хотя, может быть, вы можете себе это позволить). Верна и обратная сторона этого утверждения: если у вас слишком мало сегментов, то в среднем у вас будет больше элементов на каждый сегмент, поэтому поиск займет больше времени, но вы будете использовать меньше памяти.
Хорошим компромиссом является динамическое изменение количества сегментов в течение времени существования хеш-таблицы. Коэффициент загрузки хеш-таблицы, обычно обозначаемый α, представляет собой отношение количества элементов к количеству сегментов. Большинство хеш-таблиц выбирают некоторый максимальный коэффициент загрузки. Как только коэффициент загрузки превышает этот предел, хеш-таблица увеличивает количество слотов (скажем, удваивая), а затем перераспределяет элементы из старой таблицы в новую. Это называется перефразированием. Предполагая, что максимальный коэффициент загрузки в таблице является постоянным, это гарантирует, что при условии, что у вас есть хорошая хеш-функция, ожидаемые затраты на выполнение поиска останутся равными O(1). Вставки теперь имеют амортизированную ожидаемая стоимость O(1) из-за затрат на периодическое восстановление таблицы, как в случае с удалениями. (Удаление может аналогичным образом сжать таблицу, если коэффициент нагрузки станет слишком мал.)
Стратегии хеширования
До этого момента мы говорили о цепном хешировании, которое является одной из многих различных стратегий построения хеш-таблицы. Напоминаем, что цепное хеширование вроде как выглядит как шкафчик для одежды - каждое ведро (ящик) может содержать несколько предметов, и когда вы выполняете поиск, вы проверяете все эти элементы.
Однако это не единственный способ построить хеш-таблицу. Есть еще одно семейство хэш-таблиц, в которых используется стратегия, называемая открытой адресацией. Основная идея открытой адресации - хранить массив ячеек, где каждый слот может быть пустым или содержать ровно один элемент.
При открытой адресации, когда вы выполняете вставку, как и раньше, вы переходите к некоторому слоту, индекс которого зависит от вычисленного хэш-кода. Если этот слот бесплатный, отлично! Вы кладете туда предмет, и все готово. Но что, если слот уже заполнен? В этом случае вы используете некоторую вторичную стратегию, чтобы найти другой свободный слот для хранения предмета. Наиболее распространенная стратегия для этого использует подход, называемый линейным зондированием. При линейном зондировании, если желаемый слот уже заполнен, вы просто переходите к следующему слоту в таблице. Если этот слот пуст - отлично! Вы можете положить предмет туда. Но если этот слот заполнен, вы затем переходите к следующему слоту в таблице и т. Д. (Если вы попали в конец таблицы, просто вернитесь к началу).
Линейное зондирование - удивительно быстрый способ построить хеш-таблицу. Кеши ЦП оптимизированы для определения местоположения ссылок, поэтому поиск в памяти в соседних ячейках памяти обычно выполняется намного быстрее, чем поиск в памяти в разрозненных местах. Поскольку вставка или удаление с помощью линейного зондирования работает путем попадания в какой-либо слот массива, а затем линейного движения вперед, это приводит к небольшому количеству промахов кеша и в конечном итоге оказывается намного быстрее, чем обычно предсказывает теория. (И бывает так, что теория предсказывает, что это будет очень быстро!)
Еще одна стратегия, которая стала популярной в последнее время, - хеширование с кукушкой. Мне нравится думать о хешировании с кукушкой как о "замороженном" хеш-таблицах. Вместо одной хеш-таблицы и одной хеш-функции у нас есть две хеш-таблицы и две хеш-функции. Каждый элемент может находиться ровно в одном из двух мест - либо в месте в первой таблице, заданном первой хеш-функцией, либо в месте во второй таблице, заданном второй хеш-функцией. Это означает, что поиск эффективен в худшем случае, так как вам нужно проверить только два места, чтобы увидеть, есть ли что-то в таблице.
Вставки при хешировании с кукушкой используют другую стратегию, чем раньше. Мы начинаем с того, что проверяем, свободны ли какие-либо из двух слотов, в которых может находиться предмет. Если так, отлично! Мы просто кладем туда предмет. Но если это не сработает, мы выбираем один из слотов, помещаем туда предмет и выкидываем предмет, который там был раньше. Этот предмет должен куда-то пойти, поэтому мы пытаемся поместить его в другую таблицу в соответствующий слот. Если это сработает, отлично! Если нет, мы выкидываем элемент из этой таблицы и пытаемся вставить его в другую таблицу. Этот процесс продолжается до тех пор, пока все не остановится или мы не окажемся в ловушке цикла. (Последний случай встречается редко, и если это произойдет, у нас есть несколько вариантов, например "поместить его во вторичную хеш-таблицу" или "выбрать новые хеш-функции и перестроить таблицы".)
Есть много улучшений, возможных для хеширования с кукушкой, таких как использование нескольких таблиц, позволяющая каждому слоту содержать несколько элементов и создание "тайника", в котором хранятся элементы, которые не могут поместиться в другом месте, и это активная область исследований!
Тогда есть гибридные подходы. Хеширование в классическом стиле - это сочетание открытой адресации и цепного хеширования, которое можно рассматривать как взятие цепочки хеш-таблицы и хранение каждого элемента в каждом сегменте в слоте рядом с тем, куда элемент хочет попасть. Эта стратегия хорошо работает с многопоточностью. В таблице Swiss используется тот факт, что некоторые процессоры могут выполнять несколько операций параллельно с одной инструкцией, чтобы ускорить таблицу линейного измерения. Расширяемое хеширование предназначено для баз данных и файловых систем и использует сочетание дерева и связанной хеш-таблицы для динамического увеличения размеров сегментов по мере загрузки отдельных сегментов. Робин Гуд хеширование представляет собой вариант линейного исследования, при котором элементы можно перемещать после вставки, чтобы уменьшить разницу в том, насколько далеко от дома может находиться каждый элемент.
Дальнейшее чтение
Для получения дополнительной информации об основах хеш-таблиц ознакомьтесь с этими слайдами лекций по цепному хешированию и с этими последующими слайдами по линейному зондированию и хешированию Робин Гуда. Вы можете узнать больше о хешировании с кукушкой здесь и о теоретических свойствах хеш-функций здесь.
Все ответы до сих пор хороши и объясняют, как работает хеш-таблица. Вот простой пример, который может быть полезен. Допустим, мы хотим хранить некоторые элементы со строчными буквенными символами в качестве ключей.
Как объяснил Саймон, хеш-функция используется для отображения из большого пространства в небольшое пространство. Простая наивная реализация хеш-функции для нашего примера может взять первую букву строки и отобразить ее в целое число, поэтому у "аллигатора" есть хэш-код 0, у "пчелы" хэш-код 1 ". зебра "будет 25 и т. д.
Затем у нас есть массив из 26 сегментов (может быть ArrayLists в Java), и мы помещаем в него элемент, соответствующий хэш-коду нашего ключа. Если у нас более одного элемента с ключом, начинающимся с одной и той же буквы, они будут иметь одинаковый хеш-код, поэтому все будут идти в сегменте для этого хэш-кода, поэтому в корзине должен быть выполнен линейный поиск для найти конкретный предмет.
В нашем примере, если бы у нас было всего несколько десятков элементов с ключами, охватывающими алфавит, это работало бы очень хорошо. Однако, если бы у нас было миллион элементов или все ключи начинались с "a" или "b", то наша хеш-таблица не была бы идеальной. Чтобы получить лучшую производительность, нам нужна другая хеш-функция и / или несколько сегментов.
Таблица прямых адресов
Чтобы понять хеш-таблицу, таблица прямых адресов — это первое понятие, которое мы должны понять.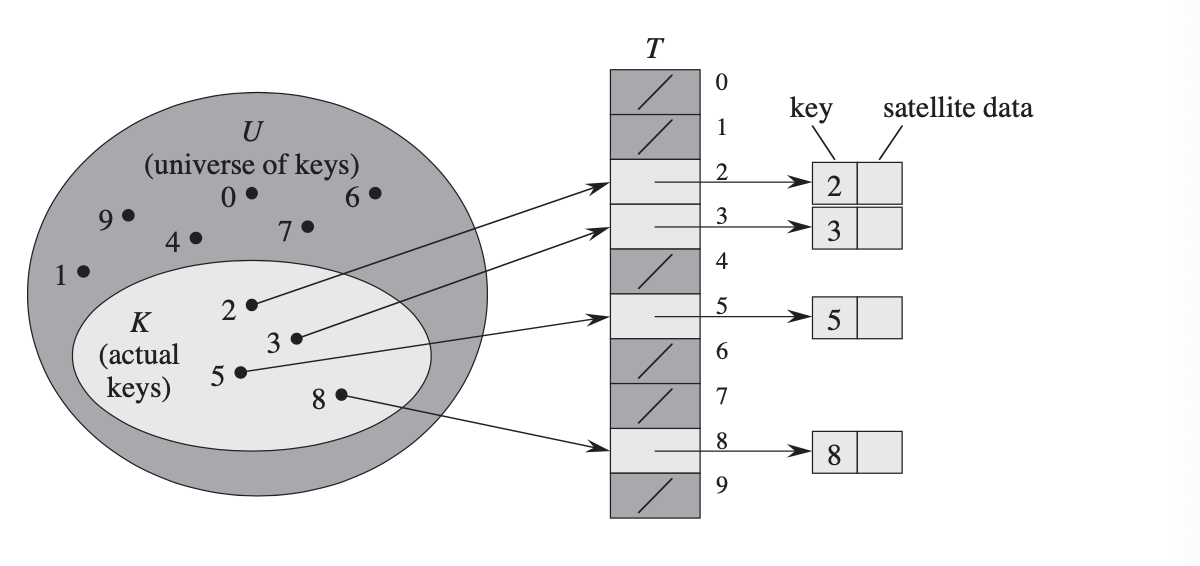
Таблица прямых адресов использует ключ непосредственно как индекс слота в массиве. Размер ключей юниверса равен размеру массива. Очень быстро получить доступ к этому ключу за время O(1), потому что массив поддерживает операции произвольного доступа.
Однако перед внедрением таблицы прямых адресов следует учесть четыре соображения:
- Чтобы быть допустимым индексом массива, ключи должны быть целыми числами.
- Вселенная ключей довольно мала, иначе нам понадобится гигантский массив.
- Два разных ключа не сопоставлены с одним и тем же слотом в массиве.
- Длина ключей юниверса равна длине массива
На самом деле, не так много ситуаций в реальной жизни соответствуют вышеперечисленным требованиям, поэтому на помощь приходит хеш-таблица .
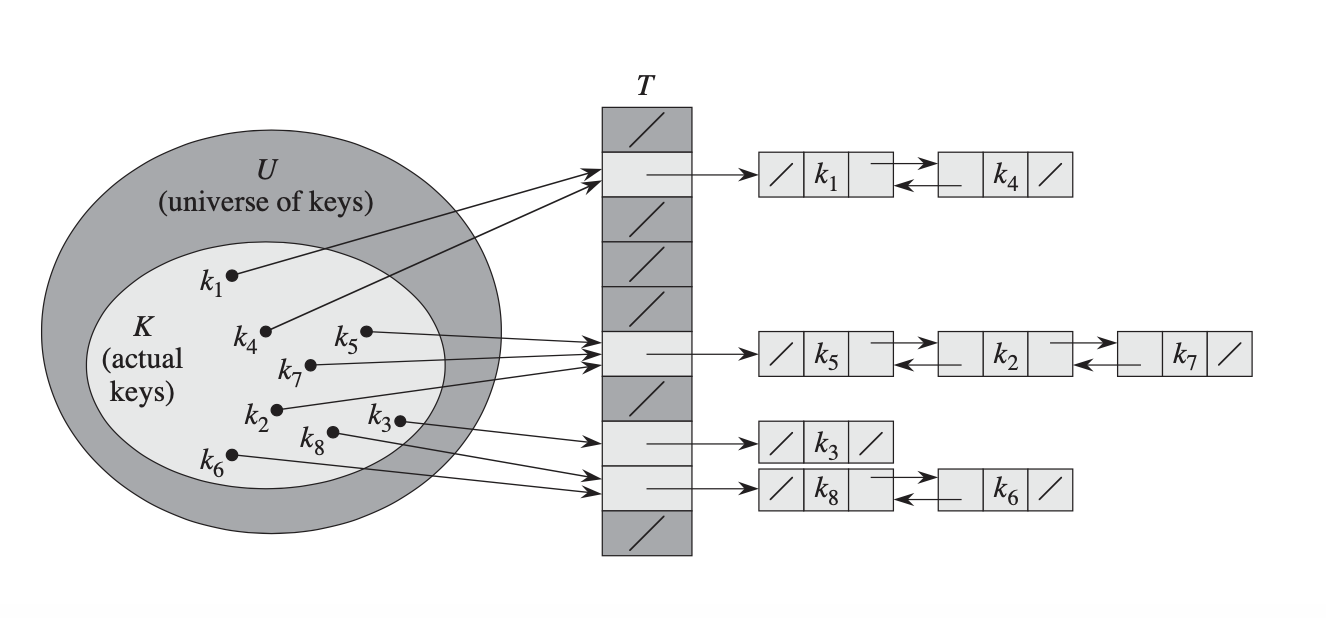
Хеш-таблица
Вместо прямого использования ключа хеш-таблица сначала применяет математическую хеш-функцию для последовательного преобразования любых произвольных данных ключа в число, а затем использует этот результат хеширования в качестве ключа.
Длина ключей юниверса может быть больше, чем длина массива, что означает, что два разных ключа могут быть хешированы с одним и тем же индексом (это называется коллизией хэшей)?
На самом деле, есть несколько разных стратегий, чтобы справиться с этим. Вот распространенное решение: вместо того, чтобы хранить фактические значения в массиве, мы сохраняем указатель на связанный список, содержащий значения для всех ключей, которые хешируются для этого индекса.
Если вам все еще интересно узнать, как реализовать хэш-карту с нуля, прочитайте следующий пост .
Вот еще один способ взглянуть на это.
Я предполагаю, что вы понимаете концепцию массива A. Это то, что поддерживает операцию индексации, где вы можете получить I-й элемент, A[I], за один шаг, независимо от того, насколько велика A.
Так, например, если вы хотите хранить информацию о группе людей, которые, как оказалось, имеют разный возраст, простым способом было бы иметь достаточно большой массив и использовать возраст каждого человека в качестве индекса в массиве. Кстати, вы можете получить доступ к информации любого человека за один шаг.
Но, конечно, может быть более одного человека одного возраста, поэтому в каждой записи вы указываете список всех людей этого возраста. Таким образом, вы можете получить информацию о конкретном человеке за один шаг плюс немного поиска в этом списке (так называемое "ведро"). Это только замедляется, если есть так много людей, что ведра становятся большими. Затем вам потребуется больший массив и какой-то другой способ получить больше идентифицирующей информации о человеке, например первые несколько букв его фамилии, вместо использования возраста.
Это основная идея. Вместо использования возраста можно использовать любую функцию человека, которая дает хороший разброс ценностей. Это хеш-функция. Как будто вы можете взять каждый третий бит ASCII-представления имени человека, закодированный в некотором порядке. Все, что имеет значение, это то, что вы не хотите, чтобы слишком много людей хэшировали одно и то же ведро, потому что скорость зависит от того, что ведра остаются маленькими.
Хеш-таблица полностью работает на том факте, что практические вычисления следуют модели машины с произвольным доступом, т.е. к значению по любому адресу в памяти можно получить доступ за O(1) времени или постоянное время.
Итак, если у меня есть универсальный набор ключей (набор всех возможных ключей, которые я могу использовать в приложении, например, номер броска для студента, если это 4 цифры, то этот юниверс представляет собой набор чисел от 1 до 9999), и Чтобы сопоставить их с конечным набором чисел, я могу выделить память в моей системе, теоретически моя хеш-таблица готова.
Как правило, в приложениях размер юниверса ключей очень велик, чем количество элементов, которые я хочу добавить в хеш-таблицу (я не хочу тратить 1 ГБ памяти на хеш, скажем, 10000 или 100000 целочисленных значений, потому что они 32 немного долго в бинарном представлении). Итак, мы используем это хеширование. Это своего рода смешанная "математическая" операция, которая отображает мою большую вселенную на небольшой набор значений, которые я могу разместить в памяти. В практических случаях часто пространство хеш-таблицы имеет тот же "порядок"(big-O), что и (количество элементов * размер каждого элемента), поэтому мы не тратим много памяти.
Теперь, большой набор сопоставлен с небольшим набором, отображение должно быть много-к-одному. Таким образом, разные ключи будут выделены в одном и том же месте (не справедливо). Есть несколько способов справиться с этим, я просто знаю два популярных:
- Используйте пространство, которое должно было быть выделено для значения, как ссылку на связанный список. В этом связанном списке будут храниться одно или несколько значений, которые находятся в одном и том же слоте во многих сопоставлениях. Связанный список также содержит ключи, которые помогут кому-то, кто приходит на поиски. Это как многие люди в одной квартире, когда приходит разносчик, он идет в комнату и специально спрашивает парня.
- Используйте двойную хэш-функцию в массиве, которая каждый раз дает одну и ту же последовательность значений, а не одно значение. Когда я иду, чтобы сохранить значение, я вижу, свободна ли требуемая область памяти или занята. Если это бесплатно, я могу хранить там свое значение, если оно занято, я беру следующее значение из последовательности и так далее, пока не найду свободное место и не сохраню там свое значение. При поиске или получении значения я возвращаюсь по тому же пути, который задан последовательностью, и в каждом месте спрашиваю vaue, есть ли оно, пока не найду его или не найду все возможные местоположения в массиве.
Введение в алгоритмы от CLRS дает очень хорошее представление о теме.
То, как вычисляется хеш, обычно зависит не от хеш-таблицы, а от элементов, добавленных в нее. В библиотеках каркасов / базовых классов, таких как.net и Java, каждый объект имеет метод GetHashCode() (или аналогичный), возвращающий хеш-код для этого объекта. Алгоритм идеального хэш-кода и его точная реализация зависят от данных, представленных в объекте.
Для всех, кто ищет язык программирования, вот как это работает. Внутренняя реализация расширенных хеш-таблиц имеет много сложностей и оптимизаций для распределения / освобождения хранилища и поиска, но идея верхнего уровня будет во многом такой же.
(void) addValue : (object) value
{
int bucket = calculate_bucket_from_val(value);
if (bucket)
{
//do nothing, just overwrite
}
else //create bucket
{
create_extra_space_for_bucket();
}
put_value_into_bucket(bucket,value);
}
(bool) exists : (object) value
{
int bucket = calculate_bucket_from_val(value);
return bucket;
}
где calculate_bucket_from_val() это функция хеширования, где должна происходить вся магия уникальности.
Эмпирическое правило: для вставки заданного значения ведро должно быть УНИКАЛЬНЫМ и ДОСТУПНЫМ ИЗ ЗНАЧЕНИЯ, которое предполагается хранить.
Bucket - это любое пространство, в котором хранятся значения - здесь я сохранил int как индекс массива, но это может быть и место в памяти.
Hashtable внутри содержит банки, в которых хранятся наборы ключей. Hashtable использует хэш-код, чтобы решить, какую пару ключей следует планировать. Способность получить область контейнера из хэш-кода Key называется хэш-работой. В принципе, хэш-работа — это способность, которая при наличии ключа создает адрес в таблице. Хэш-работа постоянно возвращает число для элемента. Два эквивалентных элемента будут постоянно иметь одинаковый номер, в то время как два несовместимых объекта обычно не могут иметь разные номера. Когда мы помещаем объекты в хеш-таблицу, вполне возможно, что разные объекты могут иметь одинаковый/одинаковый хэш-код. Это известно как столкновение. Чтобы определить коллизию, hashtable использует различные списки. Наборы, сопоставленные с одним индексом массива, сохраняются в списке, а затем ссылка на список сохраняется в индексе.