Как мне найти то, что использует память в процессе Python в производственной системе?
Моя производственная система иногда обнаруживает утечку памяти, которую я не смог воспроизвести в среде разработки. Я использовал профилировщик памяти Python (в частности, Heapy) с некоторым успехом в среде разработки, но он не может помочь мне с вещами, которые я не могу воспроизвести, и я неохотно оборудую нашу производственную систему с помощью Heapy, потому что это занимает много времени, и его многопоточный удаленный интерфейс не работает на нашем сервере.
Я думаю, что мне нужен способ получить снимок рабочего процесса Python (или, по крайней мере, gc.get_objects), а затем проанализировать его в автономном режиме, чтобы увидеть, где он использует память. Как получить дамп ядра процесса Python, как это? Раз у меня есть один, как я могу сделать что-то полезное с ним?
6 ответов
Использование Python gc интерфейс сборщика мусора и sys.getsizeof() возможно сбросить все объекты Python и их размеры. Вот код, который я использую в работе для устранения утечки памяти:
rss = psutil.Process(os.getpid()).get_memory_info().rss
# Dump variables if using more than 100MB of memory
if rss > 100 * 1024 * 1024:
memory_dump()
os.abort()
def memory_dump():
dump = open("memory.pickle", 'w')
for obj in gc.get_objects():
i = id(obj)
size = sys.getsizeof(obj, 0)
# referrers = [id(o) for o in gc.get_referrers(obj) if hasattr(o, '__class__')]
referents = [id(o) for o in gc.get_referents(obj) if hasattr(o, '__class__')]
if hasattr(obj, '__class__'):
cls = str(obj.__class__)
cPickle.dump({'id': i, 'class': cls, 'size': size, 'referents': referents}, dump)
Обратите внимание, что я сохраняю данные только из объектов, которые имеют __class__ атрибут, потому что это единственные объекты, которые меня волнуют. Должна быть возможность сохранить полный список объектов, но вам нужно будет позаботиться о выборе других атрибутов. Кроме того, я обнаружил, что получение ссылок для каждого объекта было чрезвычайно медленным, поэтому я решил сохранить только ссылки. В любом случае, после сбоя результирующие данные могут быть прочитаны следующим образом:
dump = open("memory.pickle")
while dump:
obj = cPickle.load(dump)
Добавлено 2017-11-15
Версия Python 3.6 находится здесь:
import gc
import sys
import _pickle as cPickle
def memory_dump():
with open("memory.pickle", 'wb') as dump:
for obj in gc.get_objects():
i = id(obj)
size = sys.getsizeof(obj, 0)
# referrers = [id(o) for o in gc.get_referrers(obj) if hasattr(o, '__class__')]
referents = [id(o) for o in gc.get_referents(obj) if hasattr(o, '__class__')]
if hasattr(obj, '__class__'):
cls = str(obj.__class__)
cPickle.dump({'id': i, 'class': cls, 'size': size, 'referents': referents}, dump)
Я расширю ответ Бретта из своего недавнего опыта. Пакет бульдозеров в хорошем состоянии, и, несмотря на такие улучшения, как добавлениеtracemalloc в stdlib в Python 3.4, его gc.get_objectsСчетная таблица - это мой незаменимый инструмент для устранения утечек памяти. Ниже я используюdozer > 0.7 который не был выпущен на момент написания (ну, потому что недавно я внес туда пару исправлений).
пример
Давайте посмотрим на нетривиальную утечку памяти. Я буду использовать здесь Celery 4.4 и в конечном итоге обнаружу функцию, которая вызывает утечку (и поскольку это ошибка / функция, ее можно назвать простой неправильной конфигурацией, вызванной незнанием). Итак, есть Python 3.6 venv, где яpip install celery < 4.5. И есть следующий модуль.
demo.py
import time
import celery
redis_dsn = 'redis://localhost'
app = celery.Celery('demo', broker=redis_dsn, backend=redis_dsn)
@app.task
def subtask():
pass
@app.task
def task():
for i in range(10_000):
subtask.delay()
time.sleep(0.01)
if __name__ == '__main__':
task.delay().get()
В основном задача, которая планирует кучу подзадач. Что может пойти не так?
Я буду использовать procpath для анализа потребления памяти узлами Celery. pip install procpath. У меня 4 терминала:
procpath record -d celery.sqlite -i1 "$..children[?('celery' in @.cmdline)]"для записи статистики дерева процессов узла Celerydocker run --rm -it -p 6379:6379 redisдля запуска Redis, который будет выступать в роли брокера Celery и приводить к бэкэндуcelery -A demo worker --concurrency 2запустить узел с 2 рабочимиpython demo.pyчтобы наконец запустить пример
(4) закончится менее чем за 2 минуты.
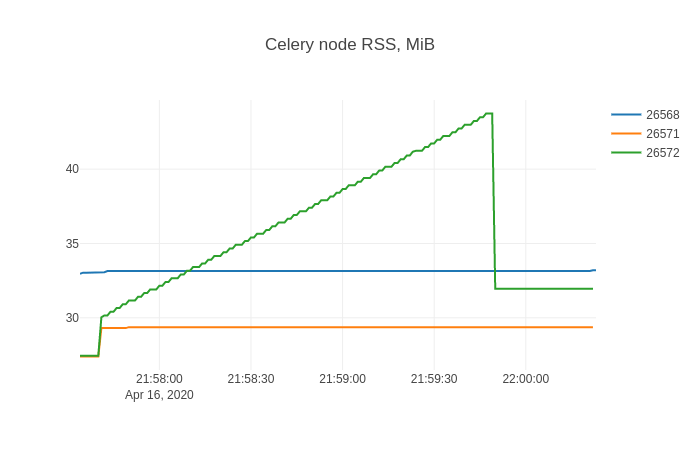
Затем я использую Falcon SQL Client, чтобы визуализировать, чтоprocpathесть рекордер. Я использую этот запрос:
SELECT datetime(ts, 'unixepoch', 'localtime') ts, stat_pid, stat_rss / 256.0 rss
FROM record
А в Falcon я создаю трассировку линейной диаграммы с помощью X=ts, Y=rssи добавьте разделенное преобразование By=stat_pid. График результатов:
Эта форма, вероятно, хорошо знакома всем, кто боролся с утечками памяти.
Поиск протекающих предметов
Теперь пришло время для dozer. Я покажу неинструментированный случай (и вы можете аналогичным образом инструментировать свой код, если сможете). Чтобы внедрить сервер Dozer в целевой процесс, я буду использовать Pyrasite. Об этом нужно знать две вещи:
- Чтобы запустить его, ptrace должен быть настроен как "классические разрешения ptrace":
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope, что может быть угрозой безопасности - Есть ненулевые шансы, что ваш целевой процесс Python выйдет из строя
С этой оговоркой я:
pip install https://github.com/mgedmin/dozer/archive/3ca74bd8.zip(это должно быть 0.8, о которой я говорил выше)pip install pillow(которыйdozerиспользует для построения графиков)pip install pyrasite
После этого я могу получить оболочку Python в целевом процессе:
pyrasite-shell 26572
И введите следующее, которое запустит приложение Dozer WSGI с использованием stdlib wsgirefсервер.
import threading
import wsgiref.simple_server
import dozer
def run_dozer():
app = dozer.Dozer(app=None, path='/')
with wsgiref.simple_server.make_server('', 8000, app) as httpd:
print('Serving Dozer on port 8000...')
httpd.serve_forever()
threading.Thread(target=run_dozer, daemon=True).start()
Открытие http://localhost:8000 в браузере должно появиться что-то вроде:
После этого я бегу python demo.pyиз (4) еще раз и дождитесь его завершения. Затем в Dozer я установил "Floor" на 5000, и вот что я вижу:
Два типа, связанных с сельдереем, растут по расписанию подзадачи:
celery.result.AsyncResultvine.promises.promise
weakref.WeakMethod имеет ту же форму и числа и должно быть вызвано одним и тем же.
Поиск первопричины
На этом этапе по типам утечек и тенденциям уже может быть ясно, что происходит в вашем случае. Если это не так, Dozer имеет ссылку "TRACE" для каждого типа, которая позволяет отслеживать (например, видеть атрибуты объекта) источники перехода выбранного объекта (gc.get_referrers) и референты (gc.get_referents) и продолжаем процесс снова, обходя граф.
Но картинка говорит тысячу слов, верно? Итак, я покажу, как использовать objgraph для рендеринга графа зависимостей выбранного объекта.
pip install objgraphapt-get install graphviz
Затем:
- я бегу
python demo.pyснова из (4) - в Dozer я установил
floor=0,filter=AsyncResult - и нажмите "TRACE", что должно дать
Затем в оболочке Pyrasite запустите:
objgraph.show_backrefs([objgraph.at(140254427663376)], filename='backref.png')
Файл PNG должен содержать:
В основном есть некоторые Context объект, содержащий list называется _children это, в свою очередь, содержит множество экземпляров celery.result.AsyncResult, которые протекают. ИзменениеFilter=celery.*context в Dozer вот что я вижу:
Итак, виноват celery.app.task.Context. Поиск по этому типу обязательно приведет вас к странице задачи Celery. Быстрый поиск там "детей", вот что написано:
trail = TrueЕсли этот параметр включен, запрос будет отслеживать подзадачи, запущенные этой задачей, и эта информация будет отправлена с результатом (
result.children).
Отключение следа путем установки trail=False подобно:
@app.task(trail=False)
def task():
for i in range(10_000):
subtask.delay()
time.sleep(0.01)
Затем перезапустите узел Celery из (3) и python demo.py из (4) еще раз показывает это потребление памяти.
Задача решена!
Не могли бы вы записать трафик (через журнал) на своем производственном сайте, а затем повторно воспроизвести его на своем сервере разработки, оснащенном отладчиком памяти python? (Я рекомендую dozer: http://pypi.python.org/pypi/Dozer)
Создайте дамп ядра вашей программы, затем клонируйте экземпляр программы на достаточно похожую коробку с помощью gdb. Существуют специальные макросы, которые помогают отлаживать программы на Python в GDB, но если вы можете заставить свою программу одновременно обслуживать удаленную оболочку, вы можете просто продолжить выполнение программы и запросить ее с помощью Python.
Мне никогда не приходилось это делать, поэтому я не уверен на 100%, что это сработает, но, возможно, указатели будут полезны.
gc В модуле есть некоторые функции, которые могут быть полезны, например, перечисление всех объектов, которые сборщик мусора считает недоступными, но не может освободить, или список всех отслеживаемых объектов.
Если у вас есть подозрения, какие объекты могут протекать, модуль слабой ссылки может быть полезен, чтобы узнать, если / когда объекты собраны.
Meliae выглядит многообещающе:
Этот проект похож на heapy (в проекте 'guppy'), пытаясь понять, как распределяется память.
В настоящее время его основное отличие заключается в том, что он разделяет задачу вычисления сводной статистики и т. Д. Потребления памяти от фактического сканирования потребления памяти. Это происходит потому, что я часто хочу выяснить, что происходит в моем процессе, в то время как мой процесс потребляет огромные объемы памяти (1 ГБ и т. Д.). Это также позволяет значительно упростить сканер, поскольку я не выделяю объекты python, пытаясь проанализировать потребление памяти объектами python.
Я не знаю, как сбросить все состояние интерпретатора Python и восстановить его. Было бы полезно, я буду следить за этим ответом на случай, если у кого-то еще есть идеи.
Если у вас есть представление о том, как просачивается память, вы можете добавить чеки для пересчета ваших объектов. Например:
x = SomeObject()
... later ...
oldRefCount = sys.getrefcount( x )
suspiciousFunction( x )
if (oldRefCount != sys.getrefcount(x)):
print "Possible memory leak..."
Вы также можете проверить количество ссылок выше, чем какое-либо число, которое подходит для вашего приложения. Чтобы продвинуться дальше, вы можете изменить интерпретатор python для выполнения таких проверок, заменив Py_INCREF а также Py_DECREF Макросы со своими собственными. Это может быть немного опасно в производственном приложении, все же.
Вот эссе с дополнительной информацией об отладке такого рода вещей. Это больше приспособлено для авторов плагинов, но большинство из них применимо.