Простой график продольных данных в R
У меня простой вопрос, но я потратил несколько дней, пытаясь понять это. У меня есть длинный файл данных с повторными измерениями, как показано ниже.
ID DEPRESSION TIME GENDER
1 5 1 MALE
1 5 2 MALE
1 4 3 MALE
2 3 1 MALE
2 6 2 MALE
2 8 3 MALE
3 2 1 FEMALE
3 2 2 FEMALE
3 2 3 FEMALE
Я хочу представить тенденции депрессии с течением времени для мужчин и женщин. Однако все мои попытки привели к тому, что у каждого удостоверения личности была своя линия.
Я просто хочу одну строку для мужчины и одну линию для женщины.
1 ответ
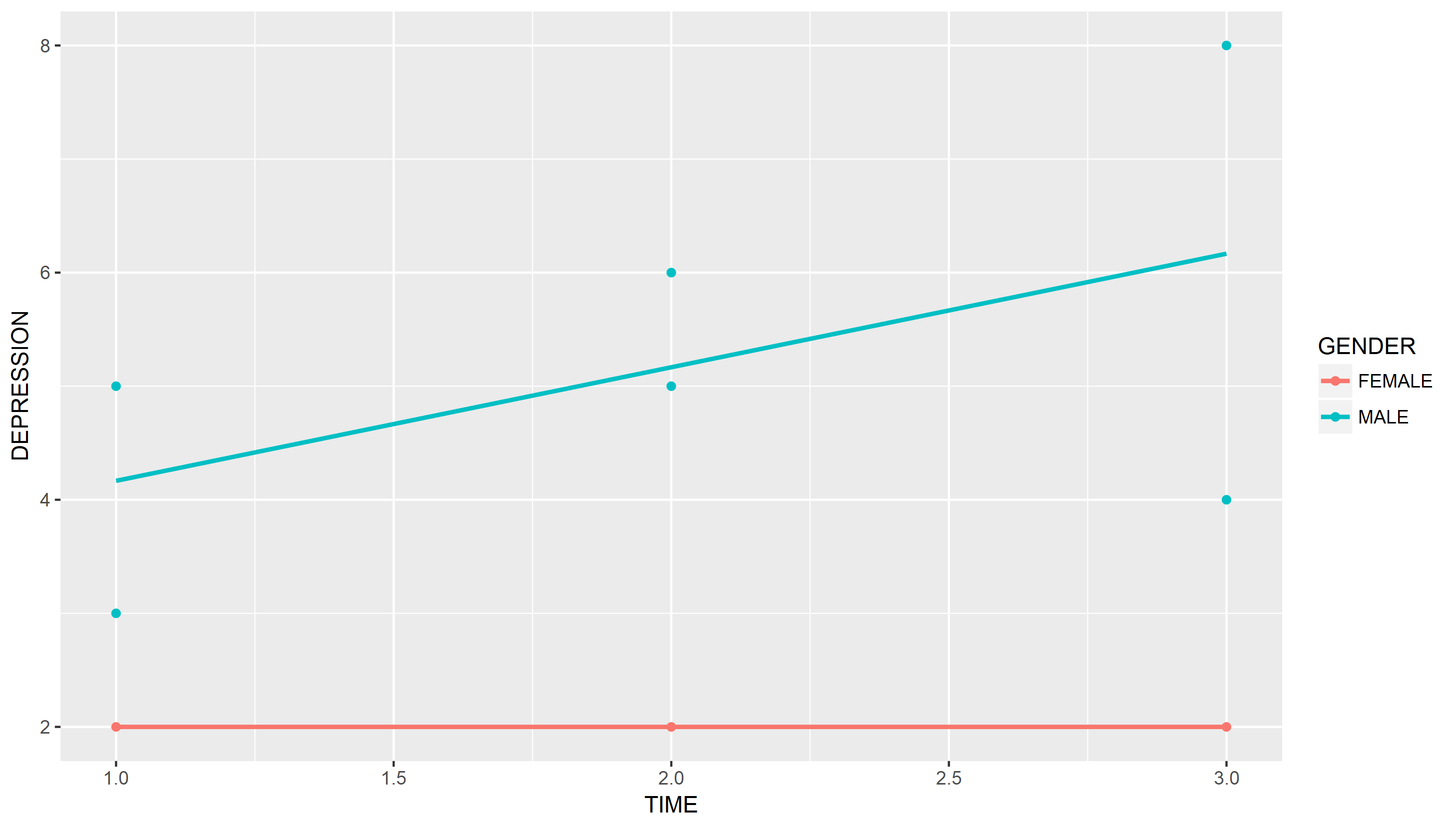
Вот решение ggplot2. Здесь я предполагаю, что когда вы говорите, что хотите "тренд", вы хотите подогнать какую-либо модель к данным. Здесь мне подходит линейная модель для каждого пола.
Я не думаю, что этот график настолько хорош, потому что в нем нет указаний на то, как ID подключены. Вы можете справиться с этим несколькими способами, вы можете отобразить shape в ID если у вас есть только несколько предметов, или соедините их с geom_path и карта group в ID,
library(ggplot2)
df <- read.table(
text = "
ID DEPRESSION TIME GENDER
1 5 1 MALE
1 5 2 MALE
1 4 3 MALE
2 3 1 MALE
2 6 2 MALE
2 8 3 MALE
3 2 1 FEMALE
3 2 2 FEMALE
3 2 3 FEMALE
",
header = TRUE
)
ggplot(df, aes(x = TIME, y = DEPRESSION, color = GENDER)) +
geom_point() +
stat_smooth(method = "lm", se = FALSE)
Для средних линий необходимо предварительно вычислить средние значения для каждой группы в новом кадре данных. Здесь я использую dplyr"s group_by а также summarise за это, давая мне df_summarised, Тогда я могу использовать новый фрейм данных для geom_hline слой только путем изменения data аргумент.
library(ggplot2)
library(dplyr)
df <- read.table(
text = "
ID DEPRESSION TIME GENDER
1 5 1 MALE
1 5 2 MALE
1 4 3 MALE
2 3 1 MALE
2 6 2 MALE
2 8 3 MALE
3 2 1 FEMALE
3 2 2 FEMALE
3 2 3 FEMALE
",
header = TRUE
)
df_summarised <- df %>%
group_by(GENDER) %>%
summarise(MEAN_DEPRESSION = mean(DEPRESSION))
ggplot(df) +
geom_point(aes(x = TIME, y = DEPRESSION, color = GENDER) +
geom_hline(aes(yintercept = MEAN_DEPRESSION, color= GENDER), data = df_summarised)
