Использование регулярных выражений, чтобы избавиться от новых строк в адресах
У меня есть набор адресных данных, в котором было три основных столбца: номер политики, адрес и номер индекса. В середине некоторых адресов есть новые строки, от которых я хочу избавиться. Но я не хочу избавляться от новых строк, разделяющих каждую строку данных. Я использую текстовую панель и пытаюсь создать регулярное выражение, которое может найти конкретные строки, которые я хочу удалить, используя поиск и замену.
Каждый индекс представляет собой случайное число, за которым следует "_CDB", поэтому я пытался создать регулярное выражение, которое удаляет все символы новой строки, которым не предшествует "_CDB". Так что мое текущее выражение использует lookbehind, который выглядит следующим образом (?<!_CDB)\n, но все же, кажется, он находит каждую новую строку, а не только те, которым не предшествует "_CDB".
Было бы очень хорошо, если бы кто-то мог предложить, где я иду не так, или предложить другой способ устранения этих новых строк в середине адресов.
Спасибо
1 ответ
Описание
Вы, вероятно, зацикливаетесь на строках с пробелами в конце строки. Я бы просто сопоставил все возвращаемые символы и захватил _CDB\nтогда просто замени
(_CDB\s*[\n\r]+)|[\n\r]
Заменить: $1
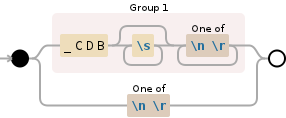
пример
Live Demo
https://regex101.com/r/qT6nU8/1
Пример текста
321321312, 1111 deer park road
kenosha
wi
53144, 1111_CDB
321321312, 222 deer park road
kenosha
wi
53144, 222_CDB
321321312, 333 deer park road
kenosha
wi
53144, 333_CDB
321321312, 4444 deer park road
kenosha
wi
53144, 4444_CDB
После замены
321321312, 1111 deer park roadkenoshawi53144, 1111_CDB
321321312, 222 deer park roadkenoshawi53144, 222_CDB
321321312, 333 deer park roadkenoshawi53144, 333_CDB
321321312, 4444 deer park roadkenoshawi53144, 4444_CDB
объяснение
NODE EXPLANATION
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
_CDB '_CDB'
----------------------------------------------------------------------
\s* whitespace (\n, \r, \t, \f, and " ") (0
or more times (matching the most amount
possible))
----------------------------------------------------------------------
[\n\r]+ any character of: '\n' (newline), '\r'
(carriage return) (1 or more times
(matching the most amount possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
[\n\r] any character of: '\n' (newline), '\r'
(carriage return)
----------------------------------------------------------------------