Распределение Zipf: Как измерить Распределение Zipf, используя Python / Numpy
У меня есть файл (скажем, corpus.txt) около 700 строк, каждая строка содержит числа, разделенные -, Например:
86-55-267-99-121-72-336-89-211
59-127-245-343-75-245-245
Сначала мне нужно прочитать данные из файла, найти частоту каждого числа, измерить распределение этих чисел по Zipf, а затем построить график распределения. Я выполнил первые две части задания. Я застрял в рисовании дистрибутива Zipf.
я знаю это numpy.random.zipf(a, size=None) следует использовать для этого. Но я нахожу это чрезвычайно трудным, чтобы использовать это. Любые указатели или фрагмент кода будут чрезвычайно полезны.
Код:
# Counts frequency as per given n
def calculateFrequency(fileDir):
frequency = {}
for line in fileDir:
line = line.strip().split('-')
for i in line:
frequency.setdefault(i, 0)
frequency[i] += 1
return frequency
fileDir = open("corpus.txt")
frequency = calculateFrequency(fileDir)
fileDir.close()
print(frequency)
## TODO: Measure and draw zipf distribution
1 ответ
Как указано numpy.random.zipf(a, size=None) будет производить график образцов, взятых из zipf распределение с указанным параметром> 1.
Тем не менее, так как ваш вопрос был труден в использовании numpy.random.zipf метод, вот наивная попытка, как обсуждалось на сайте документации scipy zipf.
Ниже моделируется corpus.txt это имеет 10 строк случайных данных на строку. Однако каждая строка может иметь дубликаты по сравнению с другими строками для имитации повторения.
16-45-3-21-16-34-30-45-5-28
11-40-22-10-40-48-22-23-22-6
40-5-33-31-46-42-47-5-27-14
5-38-12-22-19-1-11-35-40-24
20-11-24-10-9-24-20-50-21-4
1-25-22-13-32-14-1-21-19-2
25-36-18-4-28-13-29-14-13-13
37-6-36-50-21-17-3-32-47-28
31-20-8-1-13-24-24-16-33-47
26-17-39-16-2-6-15-6-40-46
Рабочий код
import csv
from operator import itemgetter
import matplotlib.pyplot as plt
from scipy import special
import numpy as np
#Read '-' seperated corpus data and get its frequency in a dict
frequency = {}
with open('corpus.txt', 'rb') as csvfile:
reader = csv.reader(csvfile, delimiter='-', quotechar='|')
for line in reader:
for word in line:
count = frequency.get(word,0)
frequency[word] = count + 1
#define zipf distribution parameter
a = 2.
#get list of values from frequency and convert to numpy array
s = frequency.values()
s = np.array(s)
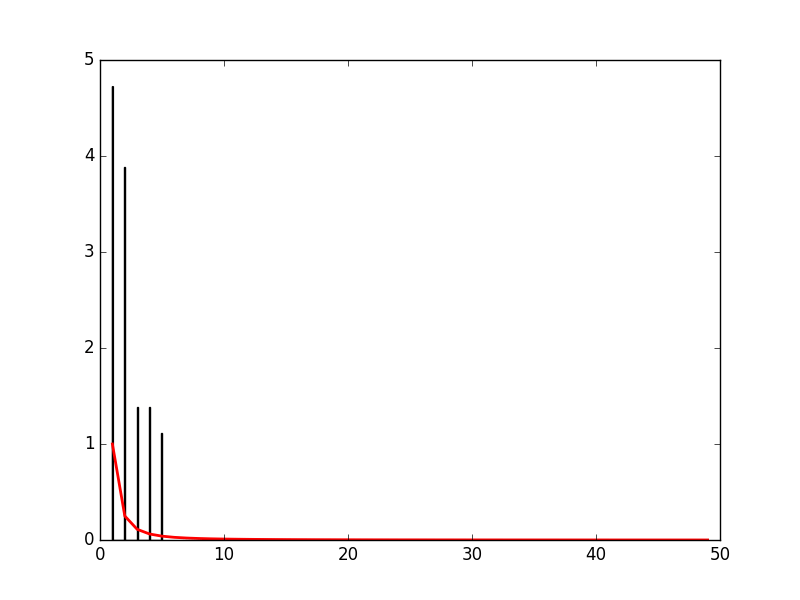
# Display the histogram of the samples, along with the probability density function:
count, bins, ignored = plt.hist(s, 50, normed=True)
x = np.arange(1., 50.)
y = x**(-a) / special.zetac(a)
plt.plot(x, y/max(y), linewidth=2, color='r')
plt.show()
График гистограммы выборок вместе с функцией плотности вероятности