Невозможно правильно прочитать данные обратно
Я пытаюсь сохранить класс человека, у которого есть список домашних животных, в файл CSV и прочитать его обратно в соответствующие объекты. Я могу написать это правильно, но не могу читать. Пожалуйста, смотрите ниже -
Person.java
import java.util.ArrayList;
import java.util.List;
public class Person {
private String name;
private List<Pet> pets;
public Person() {
}
public Person(final String name, final List<Pet> pets) {
this.name = name;
this.pets = pets;
}
/**
* @return the name
*/
public String getName() {
return name;
}
/**
* @return the pets
*/
public List<Pet> getPets() {
return pets;
}
/**
* @param pets
* the pets to set
*/
public void setAddPet(final Pet pet) {
if (pets == null) {
pets = new ArrayList<Pet>();
}
pets.add(pet);
}
/**
* @param name
* the name to set
*/
public void setName(final String name) {
this.name = name;
}
/**
* @param pets
* the pets to set
*/
public void setPets(final List<Pet> pets) {
this.pets = pets;
}
@Override
public String toString() {
return String.format("Person [name=%s, pets=%s]", name, pets);
}
}
Pet.java
public class Pet {
private String typeOfAnimal;
private String color;
public Pet() {
}
public Pet(final String typeOfAnimal, final String color) {
this.typeOfAnimal = typeOfAnimal;
this.color = color;
}
/**
* @return the color
*/
public String getColor() {
return color;
}
/**
* @return the typeOfAnimal
*/
public String getTypeOfAnimal() {
return typeOfAnimal;
}
/**
* @param color
* the color to set
*/
public void setColor(final String color) {
this.color = color;
}
/**
* @param typeOfAnimal
* the typeOfAnimal to set
*/
public void setTypeOfAnimal(final String typeOfAnimal) {
this.typeOfAnimal = typeOfAnimal;
}
@Override
public String toString() {
return String.format("Pet [typeOfAnimal=%s, color=%s]", typeOfAnimal, color);
}
}
Writer.java
import java.io.FileWriter;
import java.util.Arrays;
import java.util.List;
import org.supercsv.cellprocessor.constraint.NotNull;
import org.supercsv.cellprocessor.ift.CellProcessor;
import org.supercsv.io.dozer.CsvDozerBeanWriter;
import org.supercsv.io.dozer.ICsvDozerBeanWriter;
import org.supercsv.prefs.CsvPreference;
public class Writer {
private static final String[] HEADERS = new String[] { "name", "pets" };
private static final CellProcessor[] processors = new CellProcessor[] { new NotNull(),
new NotNull() };
private static final String CSV_FILENAME = "C:\\Users\\Desktop\\Test.csv";
public static void writeWithDozerCsvBeanWriter() throws Exception {
// create the survey responses to write
final Person person1 = new Person("Dereck", Arrays.asList(new Pet("Dog",
"Black")));
final Person person2 =
new Person("Gavin", Arrays.asList(new Pet("Squirrel", "Brown"), new Pet("Cat",
"White")));
final List<Person> people = Arrays.asList(person1, person2);
ICsvDozerBeanWriter beanWriter = null;
try {
beanWriter =
new CsvDozerBeanWriter(new FileWriter(CSV_FILENAME),
CsvPreference.STANDARD_PREFERENCE);
// configure the mapping from the fields to the CSV columns
beanWriter.configureBeanMapping(Person.class, HEADERS);
// write the header
beanWriter.writeHeader(HEADERS);
// write the beans
for (final Person person : people) {
beanWriter.write(person, processors);
}
} finally {
if (beanWriter != null) {
beanWriter.close();
}
}
}
}
Reader.java
import java.io.FileReader;
import org.supercsv.cellprocessor.Optional;
import org.supercsv.cellprocessor.constraint.NotNull;
import org.supercsv.cellprocessor.ift.CellProcessor;
import org.supercsv.io.CsvBeanReader;
import org.supercsv.io.ICsvBeanReader;
import org.supercsv.prefs.CsvPreference;
public class Reader {
private static final String CSV_FILENAME = "C:\\Users\\Desktop\\Test.csv";
/**
* An example of reading using CsvBeanReader.
*/
public static void readWithCsvBeanReader() throws Exception {
ICsvBeanReader beanReader = null;
try {
beanReader =
new CsvBeanReader(new FileReader(CSV_FILENAME),
CsvPreference.STANDARD_PREFERENCE);
// the header elements are used to map the values to the bean (names must
match)
final String[] header = beanReader.getHeader(true);
// set up the field mapping and processors dynamically
final String[] fieldMapping = new String[header.length];
final CellProcessor[] processors = new CellProcessor[header.length];
for (int i = 0; i < header.length; i++) {
if (i < 1) {
// normal mappings
fieldMapping[i] = header[i];
processors[i] = new NotNull();
} else {
// attribute mappings
fieldMapping[i] = "AddPet";
processors[i] = new Optional(new ParsePersonPet(header));
}
}
Person person;
while ((person = beanReader.read(Person.class, fieldMapping, processors)) !=
null) {
System.out.println(String.format("person=%s", person));
}
} finally {
if (beanReader != null) {
beanReader.close();
}
}
}
}
ParsePersonPet.java
import org.supercsv.cellprocessor.CellProcessorAdaptor;
import org.supercsv.util.CsvContext;
public class ParsePersonPet extends CellProcessorAdaptor {
private final String[] header;
public ParsePersonPet(final String[] header) {
this.header = header;
}
@Override
public Object execute(final Object value, final CsvContext context) {
if (value == null) {
return null;
}
final Pet pet = new Pet();
pet.setTypeOfAnimal((String) value);
return pet;
}
}
В настоящее время он записывается в CSV, как показано ниже -
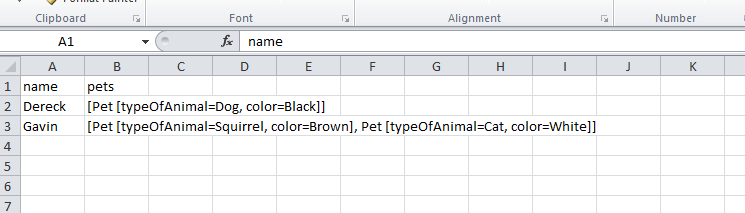
Но когда я читаю это назад и распечатываю это, это печатает как ниже -
person=Person [name=Dereck, pets=[Pet [typeOfAnimal=[Pet [typeOfAnimal=Dog,
color=Black]], color=null]]]
person=Person [name=Gavin, pets=[Pet [typeOfAnimal=[Pet [typeOfAnimal=Squirrel,
color=Brown], Pet [typeOfAnimal=Cat, color=White]], color=null]]]
Я знаю, что проблема в ParsePersonPet.java в
pet.setTypeOfAnimal((String) value);
Но значение, кажется, возвращается в виде строки как Pet [typeOfAnimal=Dog, color=Black] Нужно ли использовать String Tokenizer и устанавливать соответствующие значения? Это может быть довольно утомительно, верно? Что мне здесь делать?
Спасибо
Обновление: я получил код для работы, изменив мой ParsePersonPet ниже:
import org.supercsv.cellprocessor.CellProcessorAdaptor;
import org.supercsv.util.CsvContext;
public class ParsePersonPet extends CellProcessorAdaptor {
private final String[] header;
public ParsePersonPet(final String[] header) {
this.header = header;
}
@Override
public Object execute(final Object value, final CsvContext context) {
if (value == null) {
return null;
}
final String str = (String) value;
final Pet pet = new Pet();
pet.setTypeOfAnimal(getValue("typeOfAnimal", str));
pet.setColor(getValue("color", str));
return pet;
}
public String getValue(final String strValueToSearchFor, final String str) {
if (str.contains(strValueToSearchFor)) {
final int startIndex =
str.lastIndexOf(strValueToSearchFor) + strValueToSearchFor.length() + 1;
int endIndex = str.indexOf(",", startIndex);
if (endIndex == -1) {
endIndex = str.indexOf("]", startIndex);
}
return str.substring(startIndex, endIndex);
}
return null;
}
}
Мне нужно знать, как избежать использования setAddpet и использовать вместо него setPets, а также что мне делать, если у меня вместо списка есть карта домашних животных.
Спасибо
1 ответ
У вас есть 2 варианта. Перейдите к "Быстрый ответ", если хотите.
Продолжайте использовать стандартный CsvBeanReader/Writer
Как вы знаете, CsvBeanReader а также CsvBeanWriter не может обрабатывать индексированные или вложенные отображения, поэтому для доступа к полям дочернего класса должны быть методы получения / установки родительского класса.
Super CSV выполнит вызов сотового процессора toString() на значение затем экранируйте запятые, кавычки и переводы строк, если это необходимо. Так в вашем писателе, после NotNull() убедитесь, что список не является нулевым, он просто делает toString() и сбежать. Таким образом, в конечном итоге вы получите один столбец с домашними животными в файле CSV.
Если бы вы хотели столбец для каждого питомца, вы должны иметь отдельный получатель (getPet1(), getPet2()и т. д.), который просто получает доступ к нужному питомцу в списке. Вы должны знать, сколько питомцев вы хотите поддерживать - в CSV не должно быть переменных столбцов. Я представляю, что вы на самом деле хотите 2 колонки для каждого питомца - тип и цвет животного - чтобы у вас могли быть разные добытчики ((getPet1Type(), getPet1Color()и т. д.) или напишите процессоры с 2 ячейками (FmtPetType и FmtPetColor), которые просто возвращают тип или цвет.
Таким образом, ваш CSV-файл будет выглядеть примерно так:
name,pet1Type,pet1Color,pet2Type,pet2Color
Jo,Dog,Black,Cat,White
Быстрый ответ
В противном случае, если вы хотите сохранить toString список домашних животных (зная, что ваш CSV-файл труднее для анализа другими людьми), вам нужно написать собственный процессор для ячеек, который может принять toString()перечислим и снова разберем его в списке домашних животных. Это немного больно, но выполнимо. Вам не понадобится setAddPet() метод, так как он мог бы просто использовать setPets(),
Используйте CsvDozerBeanReader и CsvDozerBeanWriter
Я видел ваш другой вопрос, так что я знаю, что вы уже использовали расширение dozer. В этом случае я бы порекомендовал это. Чтобы получить CSV-файл, который я предложил выше, вы можете настроить fieldMapping с помощью:
String[] fieldMapping = {"name","pets[0].typeOfAnimal","pets[0].color",
"pets[1].typeOfAnimal","pets[1].color"};
И не нужно беспокоиться о каких-либо пользовательских процессорах ячеек. Если у вас много домашних животных, вы можете просто создать динамическое отображение поля, как я предложил в вашем другом вопросе.