antlr parse xml потерянное совпадение токена или дублированное совпадение
Я новичок в ANTLR и пытаюсь следовать грамматике в ANTLRWorks1.4.3.
grammar TextGra;
element : starttag (element)* endtag
;
starttag: '<' TAGNAME '>';
endtag : '</' TAGNAME '>';
TAGNAME : ('a'..'z')|('A'..'Z')|('0'..'9');
WS : (' '|'\r'|'\n')+ {skip();} ;
когда попробуйте разобрать простой фрагмент XML, как это
<a><b><c></c></b></a>
потерял два последних элемента endtag, как справиться с этой ситуацией? или это неправильный путь? Имя тега не может быть ограничено в моей ситуации. Сравните с другим кодом синтаксического анализа xml. или грамматика может использовать $0 для ссылки на предыдущий сопоставленный токен?(как в регулярном выражении). В этой ситуации определите тэг в конце тега по предыдущему совпадающему тегу запуска. Спасибо всем за ответ!
1 ответ
Я предполагаю, что вы используете интерпретатор ANTLRWorks: нет, он глючит. Всегда используйте отладчик, включенный в ANTLRWorks (нажмите CTRL+D, чтобы запустить отладчик).
Я не изменил вашу грамматику или ввод, и это то, что произвел переводчик:
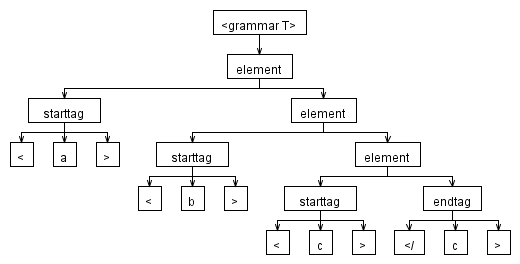
И отладчик произвел это:
