Как определить маркеры для Водораздела в OpenCV?
Я пишу для Android с OpenCV. Я сегментирую изображение, подобное приведенному ниже, используя водораздел, управляемый маркером, без того, чтобы пользователь вручную отмечал изображение. Я планирую использовать региональные максимумы в качестве маркеров.
minMaxLoc() дал бы мне значение, но как я могу ограничить его с каплями, которые меня интересуют? Могу ли я использовать результаты findContours() или cvBlob blob для ограничения ROI и применения максимумов к каждому blob?

3 ответа
Прежде всего: функция minMaxLoc находит только глобальный минимум и глобальный максимум для данного входа, поэтому он в основном бесполезен для определения региональных минимумов и / или региональных максимумов. Но ваша идея верна, извлечение маркеров на основе региональных минимумов / максимумов для выполнения преобразования водораздела на основе маркеров совершенно нормально. Позвольте мне попытаться уточнить, что такое преобразование Watershed и как вы должны правильно использовать реализацию, представленную в OpenCV.
Некоторое приличное количество статей, посвященных водоразделу, описывает это подобно тому, что следует ниже (я могу пропустить некоторые детали, если вы не уверены: спросите). Рассмотрим поверхность какого-либо региона, который вы знаете, он содержит долины и пики (среди других деталей, которые здесь для нас не важны). Предположим, что под этой поверхностью у вас есть только вода, цветная вода. Теперь сделайте отверстия в каждой долине вашей поверхности, и тогда вода начнет заполнять всю область. В какой-то момент встретятся разноцветные воды, и когда это произойдет, вы построите плотину так, чтобы они не касались друг друга. В конце концов у вас есть коллекция плотин, которая является водоразделом, разделяющим всю разноцветную воду.
Теперь, если вы сделаете слишком много отверстий на этой поверхности, у вас будет слишком много областей: чрезмерная сегментация. Если вы делаете слишком мало, вы получаете недостаточную сегментацию. Таким образом, практически любой документ, который предлагает использовать водораздел, на самом деле представляет методы, позволяющие избежать этих проблем для приложения, с которым имеет дело документ.
Я написал все это (что, возможно, слишком наивно для тех, кто знает, что такое преобразование "Водораздел"), потому что оно напрямую отражает то, как вы должны использовать реализации "Водораздел" (что текущий принятый ответ делает совершенно неправильно). Давайте начнем с примера OpenCV сейчас, используя привязки Python.
Изображение, представленное в вопросе, состоит из множества объектов, которые в основном расположены слишком близко и в некоторых случаях перекрываются. Полезность водораздела здесь состоит в том, чтобы правильно разделить эти объекты, а не группировать их в один компонент. Поэтому вам нужен как минимум один маркер для каждого объекта и хорошие маркеры для фона. В качестве примера сначала оцифровываем входное изображение Оцу и выполняем морфологическое открытие для удаления небольших объектов. Результат этого шага показан ниже на левом изображении. Теперь с двоичным изображением рассмотрите применение преобразования расстояния к нему, результат справа.


С результатом преобразования расстояния мы можем рассмотреть некоторый порог, такой, что мы рассматриваем только области, наиболее удаленные от фона (левое изображение ниже). Делая это, мы можем получить маркер для каждого объекта, пометив различные области после более раннего порога. Теперь мы можем также рассмотреть границу расширенной версии левого изображения выше, чтобы составить наш маркер. Полный маркер показан справа внизу (некоторые маркеры слишком темные, чтобы их можно было увидеть, но каждая белая область на левом изображении представлена на правом изображении).


Этот маркер, который мы имеем здесь, имеет большой смысл. каждый colored water == one marker начнет заполнять область, и преобразование водораздела построит дамбы, чтобы препятствовать тому, чтобы различные "цвета" слились. Если мы сделаем преобразование, мы получим изображение слева. Рассматривая только дамбы, составляя их с оригинальным изображением, мы получаем результат справа.


import sys
import cv2
import numpy
from scipy.ndimage import label
def segment_on_dt(a, img):
border = cv2.dilate(img, None, iterations=5)
border = border - cv2.erode(border, None)
dt = cv2.distanceTransform(img, 2, 3)
dt = ((dt - dt.min()) / (dt.max() - dt.min()) * 255).astype(numpy.uint8)
_, dt = cv2.threshold(dt, 180, 255, cv2.THRESH_BINARY)
lbl, ncc = label(dt)
lbl = lbl * (255 / (ncc + 1))
# Completing the markers now.
lbl[border == 255] = 255
lbl = lbl.astype(numpy.int32)
cv2.watershed(a, lbl)
lbl[lbl == -1] = 0
lbl = lbl.astype(numpy.uint8)
return 255 - lbl
img = cv2.imread(sys.argv[1])
# Pre-processing.
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, img_bin = cv2.threshold(img_gray, 0, 255,
cv2.THRESH_OTSU)
img_bin = cv2.morphologyEx(img_bin, cv2.MORPH_OPEN,
numpy.ones((3, 3), dtype=int))
result = segment_on_dt(img, img_bin)
cv2.imwrite(sys.argv[2], result)
result[result != 255] = 0
result = cv2.dilate(result, None)
img[result == 255] = (0, 0, 255)
cv2.imwrite(sys.argv[3], img)
Я хотел бы объяснить простой код о том, как использовать водораздел здесь. Я использую OpenCV-Python, но я надеюсь, что вам не составит труда понять.
В этом коде я буду использовать водораздел как инструмент для извлечения фона на переднем плане. (Этот пример является аналогом кода C++ в кулинарной книге OpenCV). Это простой случай, чтобы понять водораздел. Кроме того, вы можете использовать водораздел для подсчета количества объектов на этом изображении. Это будет немного продвинутая версия этого кода.
1 - Сначала мы загружаем наше изображение, преобразуем его в оттенки серого и пороговое значение подходящего значения. Я взял бинаризацию Оцу, чтобы найти лучшее пороговое значение.
import cv2
import numpy as np
img = cv2.imread('sofwatershed.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
Ниже приведен результат, который я получил:

(даже этот результат хорош, потому что большой контраст между передним и фоновым изображениями)
2 - Теперь мы должны создать маркер. Маркер - это изображение того же размера, что и исходное изображение, 32SC1 (32-битный подписанный одиночный канал).
Теперь в исходном изображении будут некоторые области, в которых вы просто уверены, что эта часть принадлежит переднему плану. Отметьте такой регион 255 на маркерном изображении. Теперь область, где вы обязательно будете фоном, помечена 128. Область, в которой вы не уверены, помечена 0. Это то, что мы собираемся делать дальше.
A - Регион переднего плана:- У нас уже есть пороговое изображение, где таблетки белого цвета. Мы их немного размыли, так что мы уверены, что оставшаяся область принадлежит переднему плану.
fg = cv2.erode(thresh,None,iterations = 2)
фг:

B - Фоновая область:- Здесь мы расширяем пороговое изображение, чтобы фоновая область была уменьшена. Но мы уверены, что оставшаяся черная область имеет 100% фона. Мы установили его на 128.
bgt = cv2.dilate(thresh,None,iterations = 3)
ret,bg = cv2.threshold(bgt,1,128,1)
Теперь мы получаем bg следующим образом:
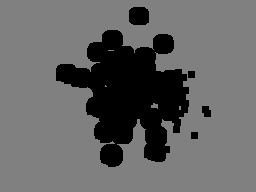
C - Теперь мы добавим fg и bg:
marker = cv2.add(fg,bg)
Ниже то, что мы получаем:

Теперь мы можем ясно понять из приведенного выше изображения, что белый регион на 100% передний план, серый регион на 100% фон, а черный регион мы не уверены.
Затем мы конвертируем его в 32SC1:
marker32 = np.int32(marker)
3 - Наконец, мы применяем водораздел и конвертируем результат обратно в изображение uint8:
cv2.watershed(img,marker32)
m = cv2.convertScaleAbs(marker32)
м:

4 - Мы правильно пороговую, чтобы получить маску и выполнить bitwise_and с входным изображением:
ret,thresh = cv2.threshold(m,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
res = cv2.bitwise_and(img,img,mask = thresh)
Res:

Надеюсь, поможет!!!
КОВЧЕГ
предисловие
Я в основном участвую, потому что я нашел, что учебник по водоразделу в документации OpenCV (и пример C++), а также ответ mmgp выше, был довольно запутанным. Я пересматривал водораздел подход несколько раз, чтобы в конечном итоге отказаться от разочарования. Я наконец понял, что мне нужно, по крайней мере, попробовать этот подход и увидеть его в действии. Это то, что я придумал после того, как перебрал все учебники, с которыми сталкивался.
Помимо того, что я новичок в области компьютерного зрения, большая часть моих проблем, вероятно, была связана с моим требованием использовать библиотеку OpenCVSharp, а не Python. В C# нет встроенных операторов мощных массивов, подобных тем, которые можно найти в NumPy (хотя я понимаю, что это было перенесено через IronPython), поэтому я немного постарался как в понимании, так и в реализации этих операций в C#. Кроме того, для протокола, я действительно презираю нюансы и несоответствия в большинстве этих вызовов функций. OpenCVSharp - одна из самых хрупких библиотек, с которыми я когда-либо работал. Но эй, это порт, так чего я ожидал? Но лучше всего - это бесплатно.
Без дальнейших церемоний, давайте поговорим о моей реализации OpenCVSharp водораздела, и, надеюсь, проясним некоторые наиболее острые моменты реализации водораздела в целом.
заявка
Прежде всего, убедитесь, что водораздел - это то, что вам нужно, и разберитесь в его использовании. Я использую окрашенные клетки, как этот:

Мне потребовалось много времени, чтобы понять, что я не могу просто сделать один вызов водораздела, чтобы дифференцировать каждую клетку в поле. Наоборот, сначала я должен был изолировать часть поля, а затем назвать водораздел на этой небольшой части. Я выделил свою область интересов (ROI) с помощью ряда фильтров, которые я кратко объясню здесь:

- Начните с исходного изображения (слева, обрезано для демонстрационных целей)
- Изолировать красный канал (слева посередине)
- Применить адаптивный порог (справа посередине)
- Найдите контуры, затем удалите контуры с небольшими участками (справа)
После того, как мы очистили контуры, полученные в результате вышеупомянутых операций с порогом, пришло время найти кандидатов на водораздел. В моем случае я просто перебрал все контуры, превышающие определенную область.
Код
Скажем, мы изолировали этот контур от вышеуказанного поля в качестве нашего ROI:

Давайте посмотрим, как мы будем кодировать водораздел.
Мы начнем с пустого мата и нарисуем только контур, определяющий нашу рентабельность инвестиций:
var isolatedContour = new Mat(source.Size(), MatType.CV_8UC1, new Scalar(0, 0, 0));
Cv2.DrawContours(isolatedContour, new List<List<Point>> { contour }, -1, new Scalar(255, 255, 255), -1);
Для того, чтобы призыв к водоразделу заработал, ему понадобится пара "подсказок" о рентабельности инвестиций. Если вы начинающий начинающий, как я, я рекомендую заглянуть на страницу CMM для быстрого ознакомления. Достаточно сказать, что мы собираемся создать подсказки о ROI слева, создав форму справа:

Чтобы создать белую часть (или "фон") этой "подсказки", мы просто Dilate изолированная форма выглядит так:
var kernel = Cv2.GetStructuringElement(MorphShapes.Ellipse, new Size(2, 2));
var background = new Mat();
Cv2.Dilate(isolatedContour, background, kernel, iterations: 8);
Чтобы создать черную часть посередине (или "передний план"), мы будем использовать преобразование расстояния, за которым следует порог, который переносит нас из фигуры слева в фигуру справа:

Это займет несколько шагов, и вам, возможно, придется поиграться с нижней границей вашего порога, чтобы получить результаты, которые вам подходят:
var foreground = new Mat(source.Size(), MatType.CV_8UC1);
Cv2.DistanceTransform(isolatedContour, foreground, DistanceTypes.L2, DistanceMaskSize.Mask5);
Cv2.Normalize(foreground, foreground, 0, 1, NormTypes.MinMax); //Remember to normalize!
foreground.ConvertTo(foreground, MatType.CV_8UC1, 255, 0);
Cv2.Threshold(foreground, foreground, 150, 255, ThresholdTypes.Binary);
Затем мы вычтем эти два мата, чтобы получить окончательный результат нашей формы "подсказки":
var unknown = new Mat(); //this variable is also named "border" in some examples
Cv2.Subtract(background, foreground, unknown);
Опять же, если мы Cv2.ImShow неизвестно, это будет выглядеть так:

Ницца! Мне было легко обернуться. Однако следующая часть меня озадачила. Давайте посмотрим на превращение нашей "подсказки" в нечто Watershed Функция может использовать. Для этого нам нужно использовать ConnectedComponents, которая в основном представляет собой большую матрицу пикселей, сгруппированных в силу их индекса. Например, если у нас был коврик с буквами "HI", ConnectedComponents может вернуть эту матрицу:
0 0 0 0 0 0 0 0 0
0 1 0 1 0 2 2 2 0
0 1 0 1 0 0 2 0 0
0 1 1 1 0 0 2 0 0
0 1 0 1 0 0 2 0 0
0 1 0 1 0 2 2 2 0
0 0 0 0 0 0 0 0 0
Итак, 0 - это фон, 1 - это буква "H", а 2 - это буква "I". (Если вы дошли до этой точки и хотите визуализировать свою матрицу, я рекомендую проверить этот поучительный ответ.) Теперь, вот как мы будем использовать ConnectedComponents создать маркеры (или метки) для водосбора:
var labels = new Mat(); //also called "markers" in some examples
Cv2.ConnectedComponents(foreground, labels);
labels = labels + 1;
//this is a much more verbose port of numpy's: labels[unknown==255] = 0
for (int x = 0; x < labels.Width; x++)
{
for (int y = 0; y < labels.Height; y++)
{
//You may be able to just send "int" in rather than "char" here:
var labelPixel = (int)labels.At<char>(y, x); //note: x and y are inexplicably
var borderPixel = (int)unknown.At<char>(y, x); //and infuriatingly reversed
if (borderPixel == 255)
labels.Set(y, x, 0);
}
}
Обратите внимание, что функция Watershed требует, чтобы область границы была помечена 0. Итак, мы установили для всех пикселей границы значение 0 в массиве меток / маркеров.
На данный момент, мы должны быть готовы Watershed, Однако в моем конкретном приложении полезно просто визуализировать небольшую часть всего исходного изображения во время этого вызова. Это может быть необязательным для вас, но сначала я просто замаскирую небольшой фрагмент источника, расширив его:
var mask = new Mat();
Cv2.Dilate(isolatedContour, mask, new Mat(), iterations: 20);
var sourceCrop = new Mat(source.Size(), source.Type(), new Scalar(0, 0, 0));
source.CopyTo(sourceCrop, mask);
А затем сделайте волшебный звонок:
Cv2.Watershed(sourceCrop, labels);
Результаты
Выше Watershed вызов изменит labels на месте. Вам придется вернуться к воспоминанию о матрице, полученной в результате ConnectedComponents, Разница здесь в том, что если в водоразделе обнаружены плотины между водоразделами, они будут помечены как "-1" в этой матрице. Словно ConnectedComponents В результате различные водоразделы будут отмечены аналогичным образом с увеличением числа. Для моих целей я хотел сохранить их в отдельных контурах, поэтому я создал этот цикл, чтобы разделить их:
var watershedContours = new List<Tuple<int, List<Point>>>();
for (int x = 0; x < labels.Width; x++)
{
for (int y = 0; y < labels.Height; y++)
{
var labelPixel = labels.At<Int32>(y, x); //note: x, y switched
var connected = watershedContours.Where(t => t.Item1 == labelPixel).FirstOrDefault();
if (connected == null)
{
connected = new Tuple<int, List<Point>>(labelPixel, new List<Point>());
watershedContours.Add(connected);
}
connected.Item2.Add(new Point(x, y));
if (labelPixel == -1)
sourceCrop.Set(y, x, new Vec3b(0, 255, 255));
}
}
Затем я хотел напечатать эти контуры случайными цветами, поэтому я создал следующий мат:
var watershed = new Mat(source.Size(), MatType.CV_8UC3, new Scalar(0, 0, 0));
foreach (var component in watershedContours)
{
if (component.Item2.Count < (labels.Width * labels.Height) / 4 && component.Item1 >= 0)
{
var color = GetRandomColor();
foreach (var point in component.Item2)
watershed.Set(point.Y, point.X, color);
}
}
Что приводит к следующему, когда показано:

Если мы рисуем на исходном изображении плотины, которые были отмечены -1 ранее, мы получаем это:

Редактирование:
Я забыл отметить: убедитесь, что вы чистите свои коврики после того, как вы закончите с ними. Они останутся в памяти, и OpenCVSharp может показать какое-то непонятное сообщение об ошибке. Я действительно должен использовать using выше, но mat.Release() вариант также.
Кроме того, ответ MMGP выше включает эту строку: dt = ((dt - dt.min()) / (dt.max() - dt.min()) * 255).astype(numpy.uint8), который является шагом растяжения гистограммы, примененным к результатам преобразования расстояния. Я пропустил этот шаг по ряду причин (в основном потому, что я не думал, что гистограммы, которые я видел, были слишком узкими для начала), но ваш пробег может отличаться.