Как перебирать строки в DataFrame в Pandas?
У меня есть DataFrame из панд:
import pandas as pd
inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}]
df = pd.DataFrame(inp)
print df
Выход:
c1 c2
0 10 100
1 11 110
2 12 120
Теперь я хочу перебрать строки этого кадра. Для каждой строки я хочу иметь возможность доступа к ее элементам (значениям в ячейках) по имени столбцов. Например:
for row in df.rows:
print row['c1'], row['c2']
Возможно ли это сделать в пандах?
Я нашел этот похожий вопрос. Но это не дает мне ответ, который мне нужен. Например, там предлагается использовать:
for date, row in df.T.iteritems():
или же
for row in df.iterrows():
Но я не понимаю, что row Объект и как я могу с ним работать.
36 ответов
Q: Как перебирать строки в DataFrame в Pandas?
Не надо!
Итерации в пандах - это анти-паттерн, и вы должны делать это только тогда, когда исчерпали все возможные варианты. Вы не должны рассматривать использование какой-либо функции с " iter "В названии чего-то больше, чем несколько тысяч строк, иначе вам придется привыкнуть к большим ожиданиям.
Вы хотите распечатать DataFrame? использование DataFrame.to_string(),
Вы хотите что-то вычислить? В этом случае ищите методы в следующем порядке (список изменен здесь):
- Векторизация
- Подпрограммы Cython
- Список Пониманий (
forпетля) DataFrame.apply()
я. Сокращения, которые могут быть выполнены в Cython
II. Итерация в пространстве питонаDataFrame.itertuples()а такжеiteritems()DataFrame.iterrows()
iterrows а также itertuples (оба получают много голосов в ответах на этот вопрос) следует использовать в очень редких случаях, таких как генерация объектов строк / именных имен для последовательной обработки, что действительно является единственной вещью, для которой эти функции полезны.
Обращение к власти
Страница документации по итерации имеет огромное красное окно с предупреждением:
Итерация по объектам панд обычно медленная. Во многих случаях повторение вручную по строкам не требуется [...].
Быстрее, чем зацикливание: векторизация, Cython
Большое количество базовых операций и вычислений "векторизовано" пандами (либо через NumPy, либо через функции Cythonized). Это включает в себя арифметику, сравнения, (большинство) сокращений, изменение формы (например, поворот), объединений и групповых операций. Просмотрите документацию по основным функциям, чтобы найти подходящий векторизованный метод для вашей проблемы.
Если ничего не существует, не стесняйтесь писать свои собственные, используя собственные расширения Cython.
Следующая лучшая вещь: список понимания
Если вы выполняете итерацию, потому что нет векторизованного решения, и производительность важна (но не настолько важна, чтобы пройти через процесс кефонизации вашего кода), используйте понимание списка, как следующий лучший / самый простой вариант.
Чтобы перебрать строки, используя один столбец, используйте
result = [f(x) for x in df['col']]
Чтобы перебрать строки, используя несколько столбцов, вы можете использовать
# two column format
result = [f(x, y) for x, y in zip(df['col1'], df['col2'])]
# many column format
result = [f(row[0], ..., row[n]) for row in df[['col1', ...,'coln']].values]
Если вам нужен целочисленный индекс строки во время итерации, используйте enumerate:
result = [f(...) for i, row in enumerate(df[...].values)]
(где df.index[i] получает индексную метку.)
Если вы можете превратить его в функцию, вы можете использовать понимание списка. Вы можете заставить произвольно сложные вещи работать благодаря простоте и скорости необработанного Python.
Для перебора строки DataFrame в пандах можно использовать:
for index, row in df.iterrows(): print row["c1"], row["c2"]for row in df.itertuples(index=True, name='Pandas'): print getattr(row, "c1"), getattr(row, "c2")
itertuples() должен быть быстрее чем iterrows()
Но имейте в виду, согласно документам (панды 0.21.1 на данный момент):
iterrows:
dtypeможет не совпадать от строки к строкеПоскольку iterrows возвращает Series для каждой строки, он не сохраняет dtypes по строкам (dtypes сохраняются по столбцам для DataFrames).
iterrows: не изменять строки
Вы никогда не должны изменять то, что вы повторяете. Это не гарантирует работу во всех случаях. В зависимости от типов данных итератор возвращает копию, а не представление, и запись в него не будет иметь никакого эффекта.
Вместо этого используйте DataFrame.apply():
new_df = df.apply(lambda x: x * 2)itertuples:
Имена столбцов будут переименованы в позиционные имена, если они являются недопустимыми идентификаторами Python, повторяются или начинаются с подчеркивания. При большом количестве столбцов (>255) возвращаются обычные кортежи.
В то время как iterrows() хороший вариант, иногда itertuples() может быть намного быстрее:
df = pd.DataFrame({'a': randn(1000), 'b': randn(1000),'N': randint(100, 1000, (1000)), 'x': 'x'})
%timeit [row.a * 2 for idx, row in df.iterrows()]
# => 10 loops, best of 3: 50.3 ms per loop
%timeit [row[1] * 2 for row in df.itertuples()]
# => 1000 loops, best of 3: 541 µs per loop
Вы можете использовать функцию df.iloc следующим образом:
for i in range(0, len(df)):
print df.iloc[i]['c1'], df.iloc[i]['c2']
Вы также можете использовать df.apply() перебирать строки и обращаться к нескольким столбцам для функции.
def valuation_formula(x, y):
return x * y * 0.5
df['price'] = df.apply(lambda row: valuation_formula(row['x'], row['y']), axis=1)
Как эффективно выполнять итерацию
Если вам действительно нужно выполнить итерацию фрейма данных Pandas, вы, вероятно, не захотите использовать iterrows (). Есть разные методы и обычныеiterrows()далеко не лучший. itertuples () может быть в 100 раз быстрее.
Коротко:
- Как правило, используйте
df.itertuples(name=None). В частности, когда у вас есть фиксированное количество столбцов и меньше 255 столбцов. См. Пункт (3) - В противном случае используйте
df.itertuples()кроме случаев, когда в ваших столбцах есть специальные символы, такие как пробелы или "-". См. Пункт (2) - Можно использовать
itertuples()даже если в вашем фрейме данных есть странные столбцы, используя последний пример. См. Пункт (4) - Только использовать
iterrows()если вы не можете предыдущие решения. См. Пункт (1)
Различные методы перебора строк в кадре данных Pandas:
Создайте случайный фрейм данных с миллионом строк и 4 столбцами:
df = pd.DataFrame(np.random.randint(0, 100, size=(1000000, 4)), columns=list('ABCD'))
print(df)
1) Обычный iterrows() удобно, но чертовски медленно:
start_time = time.clock()
result = 0
for _, row in df.iterrows():
result += max(row['B'], row['C'])
total_elapsed_time = round(time.clock() - start_time, 2)
print("1. Iterrows done in {} seconds, result = {}".format(total_elapsed_time, result))
2) По умолчанию itertuples() уже намного быстрее, но он не работает с именами столбцов, такими как My Col-Name is very Strange (вам следует избегать этого метода, если ваши столбцы повторяются или если имя столбца не может быть просто преобразовано в имя переменной Python).:
start_time = time.clock()
result = 0
for row in df.itertuples(index=False):
result += max(row.B, row.C)
total_elapsed_time = round(time.clock() - start_time, 2)
print("2. Named Itertuples done in {} seconds, result = {}".format(total_elapsed_time, result))
3) По умолчанию itertuples() использование name=None еще быстрее, но не очень удобно, поскольку вам нужно определять переменную для каждого столбца.
start_time = time.clock()
result = 0
for(_, col1, col2, col3, col4) in df.itertuples(name=None):
result += max(col2, col3)
total_elapsed_time = round(time.clock() - start_time, 2)
print("3. Itertuples done in {} seconds, result = {}".format(total_elapsed_time, result))
4) Наконец, названный itertuples() работает медленнее, чем в предыдущем пункте, но вам не нужно определять переменную для каждого столбца, и он работает с именами столбцов, такими как My Col-Name is very Strange.
start_time = time.clock()
result = 0
for row in df.itertuples(index=False):
result += max(row[df.columns.get_loc('B')], row[df.columns.get_loc('C')])
total_elapsed_time = round(time.clock() - start_time, 2)
print("4. Polyvalent Itertuples working even with special characters in the column name done in {} seconds, result = {}".format(total_elapsed_time, result))
Выход:
A B C D
0 41 63 42 23
1 54 9 24 65
2 15 34 10 9
3 39 94 82 97
4 4 88 79 54
... .. .. .. ..
999995 48 27 4 25
999996 16 51 34 28
999997 1 39 61 14
999998 66 51 27 70
999999 51 53 47 99
[1000000 rows x 4 columns]
1. Iterrows done in 104.96 seconds, result = 66151519
2. Named Itertuples done in 1.26 seconds, result = 66151519
3. Itertuples done in 0.94 seconds, result = 66151519
4. Polyvalent Itertuples working even with special characters in the column name done in 2.94 seconds, result = 66151519
Эта статья представляет собой очень интересное сравнение iterrows и iterrows.
Я искал Как перебирать строки и столбцы и закончил вот так:
for i, row in df.iterrows():
for j, column in row.iteritems():
print(column)
У нас есть несколько вариантов сделать то же самое, многие люди поделились своими ответами.
Ниже я нашел два простых и эффективных метода:
Пример:
import pandas as pd
inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}]
df = pd.DataFrame(inp)
print (df)
#With iterrows method
for index, row in df.iterrows():
print(row["c1"], row["c2"])
#With itertuples method
for row in df.itertuples(index=True, name='Pandas'):
print(row.c1, row.c2)
Примечание: предполагается, что itertuples() работает быстрее, чем iterrows().
Вы можете написать свой собственный итератор, который реализует namedtuple
from collections import namedtuple
def myiter(d, cols=None):
if cols is None:
v = d.values.tolist()
cols = d.columns.values.tolist()
else:
j = [d.columns.get_loc(c) for c in cols]
v = d.values[:, j].tolist()
n = namedtuple('MyTuple', cols)
for line in iter(v):
yield n(*line)
Это прямо сопоставимо с pd.DataFrame.itertuples, Я стремлюсь выполнить ту же задачу с большей эффективностью.
Для данного кадра данных с моей функцией:
list(myiter(df))
[MyTuple(c1=10, c2=100), MyTuple(c1=11, c2=110), MyTuple(c1=12, c2=120)]
Или с pd.DataFrame.itertuples:
list(df.itertuples(index=False))
[Pandas(c1=10, c2=100), Pandas(c1=11, c2=110), Pandas(c1=12, c2=120)]
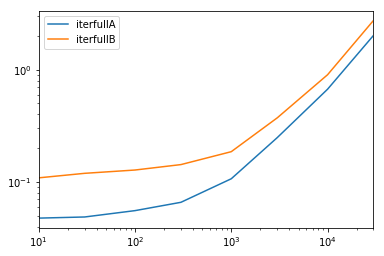
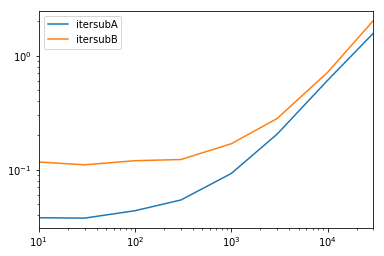
Комплексный тест
Мы тестируем доступность всех столбцов и подмножество столбцов.
def iterfullA(d):
return list(myiter(d))
def iterfullB(d):
return list(d.itertuples(index=False))
def itersubA(d):
return list(myiter(d, ['col3', 'col4', 'col5', 'col6', 'col7']))
def itersubB(d):
return list(d[['col3', 'col4', 'col5', 'col6', 'col7']].itertuples(index=False))
res = pd.DataFrame(
index=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
columns='iterfullA iterfullB itersubA itersubB'.split(),
dtype=float
)
for i in res.index:
d = pd.DataFrame(np.random.randint(10, size=(i, 10))).add_prefix('col')
for j in res.columns:
stmt = '{}(d)'.format(j)
setp = 'from __main__ import d, {}'.format(j)
res.at[i, j] = timeit(stmt, setp, number=100)
res.groupby(res.columns.str[4:-1], axis=1).plot(loglog=True);
Зациклить все строки в dataframe ты можешь использовать:
for x in range(len(date_example.index)):
print date_example['Date'].iloc[x]
ИМХО, самое простое решение
for ind in df.index:
print df['c1'][ind], df['c2'][ind]
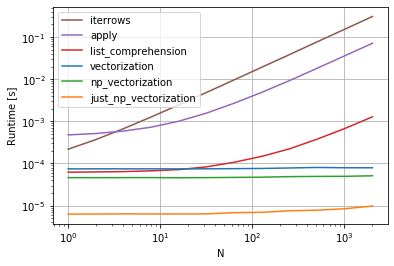
cs95 показывает, что векторизация Pandas намного превосходит другие методы Pandas для вычислений с фреймами данных.
Я хотел добавить, что если вы сначала конвертируете фрейм данных в массив NumPy, а затем используете векторизацию, это даже быстрее, чем векторизация фрейма данных Pandas (и это включает время, чтобы превратить его обратно в серию фреймов данных).
Если вы добавите следующие функции в тестовый код cs95, это станет очевидным:
def np_vectorization(df):
np_arr = df.to_numpy()
return pd.Series(np_arr[:,0] + np_arr[:,1], index=df.index)
def just_np_vectorization(df):
np_arr = df.to_numpy()
return np_arr[:,0] + np_arr[:,1]
Добавляя к ответам выше, иногда полезный образец:
# Borrowing @KutalmisB df example
df = pd.DataFrame({'col1': [1, 2], 'col2': [0.1, 0.2]}, index=['a', 'b'])
# The to_dict call results in a list of dicts
# where each row_dict is a dictionary with k:v pairs of columns:value for that row
for row_dict in df.to_dict(orient='records'):
print(row_dict)
Что приводит к:
{'col1':1.0, 'col2':0.1}
{'col1':2.0, 'col2':0.2}
Есть способ перебрать строки throw при получении взамен DataFrame, а не Series. Я не вижу, чтобы кто-нибудь упоминал, что вы можете передать index как список для строки, которая должна быть возвращена как DataFrame:
for i in range(len(df)):
row = df.iloc[[i]]
Обратите внимание на использование двойных скобок. Это возвращает DataFrame с одной строкой.
Используйте itertuples (). Это быстрее, чем iterrows ():
for row in df.itertuples():
print "c1 :",row.c1,"c2 :",row.c2
Зациклить все строки в dataframe и удобно использовать значения каждой строки, namedtuples может быть преобразован в ndarrays. Например:
df = pd.DataFrame({'col1': [1, 2], 'col2': [0.1, 0.2]}, index=['a', 'b'])
Итерация по строкам:
for row in df.itertuples(index=False, name='Pandas'):
print np.asarray(row)
результаты в:
[ 1. 0.1]
[ 2. 0.2]
Обратите внимание, что если index=Trueиндекс добавляется в качестве первого элемента кортежа, что может быть нежелательно для некоторых приложений.
Короче говоря
- Если возможно, используйте векторизацию
- Если операция не может быть векторизована - используйте составные части списка
- Если вам нужен один объект, представляющий всю строку - используйте itertuples
- Если вышеперечисленное работает слишком медленно - попробуйте swifter.apply
- Если все еще слишком медленно - попробуйте программу Cython
Контрольный показатель

Ключевые выводы:
- Используйте векторизацию.
- Скорость профилирования вашего кода! Не думайте, что что-то быстрее, потому что вы думаете, что оно быстрее; профилируйте его скорость и докажите, что он быстрее. Результаты могут Вас удивить.
Как перебирать Pandas без итерации
После нескольких недель работы над этим ответом я пришел к следующему:
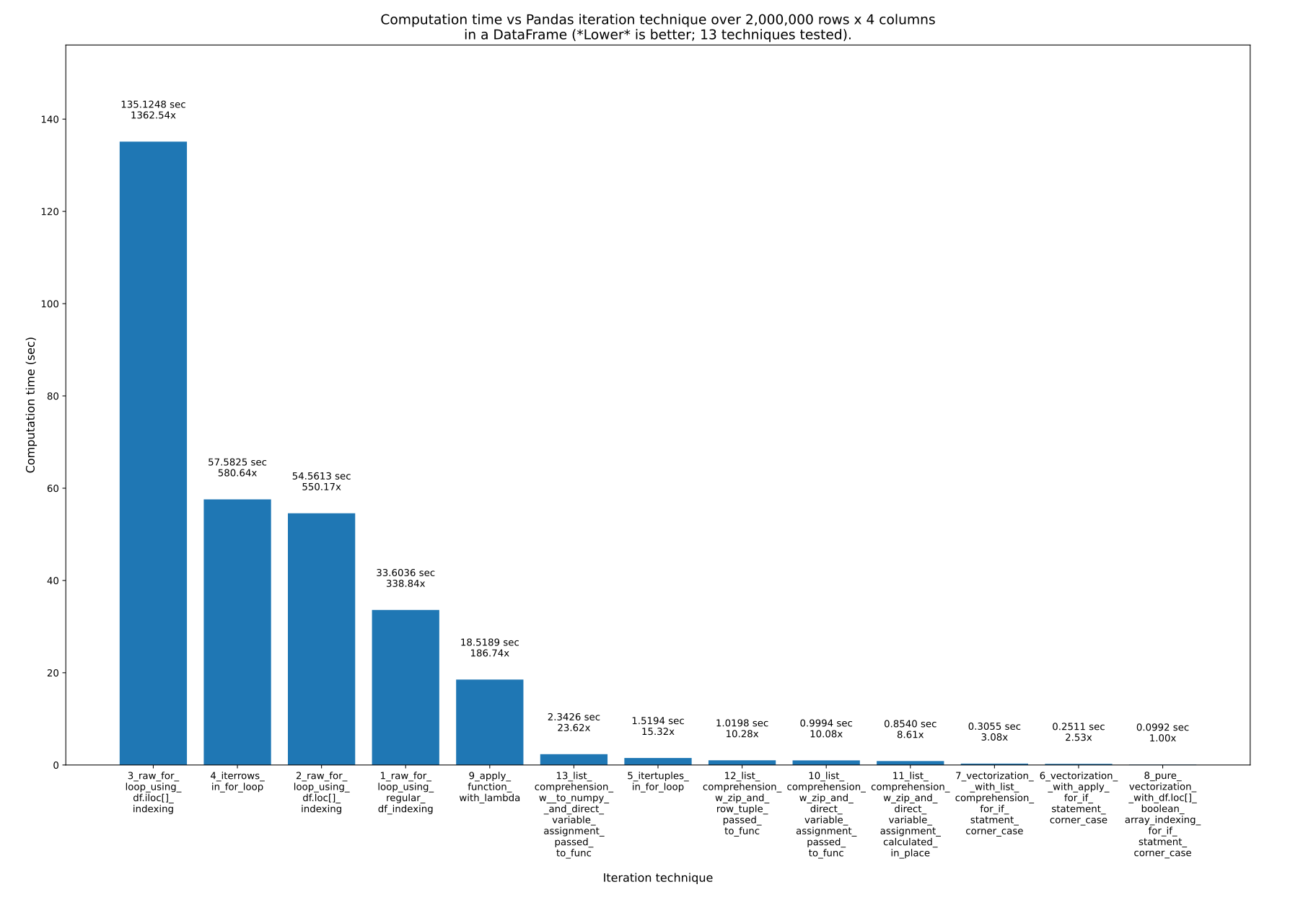
Вот 13 методов перебора Pandas . Как видите, время, необходимое для этого, сильно различается . Самая быстрая техника примерно в 1363 раза быстрее самой медленной! Ключевой вывод, , — не повторять! Вместо этого используйте векторизацию ( ).На самом деле все это означает, что вам следует использовать массивы непосредственно в математических формулах, а не пытаться вручную перебирать массивы. Базовые объекты, конечно, должны это поддерживать, но и Numpy, и Pandas это поддерживают.
Есть много способов использовать векторизацию в Pandas, которые вы можете увидеть на графике и в моем примере кода ниже. При непосредственном использовании массивов базовый цикл по-прежнему имеет место, но (я думаю) в очень оптимизированном базовом коде C, а не в чистом Python.
Полученные результаты
Было протестировано 13 техник, пронумерованных от 1 до 13. Номер и название техники указаны под каждой полосой. Общее время расчета указано над каждым баром. Ниже находится множитель, показывающий, насколько дольше это заняло, чем самый быстрый метод, показанный справа:
От pandas_dataframe_iteration_vs_vectorization_vs_list_comprehension_speed_tests.svgв моем репозитории (созданном с помощью ).
Краткое содержание
Понимание списков и векторизация (возможно, с логической индексацией ) — это все, что вам действительно нужно.
Используйте понимание списков (хорошо) и векторизацию (лучше всего). Я думаю, что чистая векторизация всегда возможна, но может потребовать дополнительной работы в сложных вычислениях. Найдите в этом ответе слова «логическое индексирование» , «логический массив» и «логическая маска» (все три — одно и то же), чтобы увидеть некоторые из более сложных случаев, когда таким образом можно использовать чистую векторизацию.
Вот 13 техник, перечисленных в порядке от самого быстрого до самого медленного . Я рекомендую никогда не использовать последние (самые медленные) 3-4 техники.
Эмпирические правила:
- Методы 3,4 и 2 никогда не следует использовать. Они очень медленные и не имеют никаких преимуществ. Однако имейте в виду: это не метод индексации, такой как или
.iloc[]это делает эти методы плохими, но, скорее, плохими их делает цикл, в котором они находятся ! я использую.loc[]например, внутри самого быстрого подхода (чистая векторизация)! Итак, вот 3 самых медленных метода, которые никогда не следует использовать:
- Самое приятное в этом то, что его можно использовать с любой функцией, предназначенной для работы с отдельными значениями или значениями массива. А это означает, что внутри функции могут быть действительно сложные операторы и другие вещи. Итак, компромисс здесь заключается в том, что он дает вам большую универсальность с действительно читаемым и повторно используемым кодом за счет использования внешних функций вычислений, но при этом дает вам большую скорость!
- В простых случаях это то, что вам следует использовать.
- Для сложных случаев, операторов и т. д. можно также использовать чистую векторизацию посредством логического индексирования, но это может добавить дополнительную работу и ухудшить читаемость. Таким образом, вы можете дополнительно использовать понимание списка (обычно лучше всего) или .apply() (обычно медленнее, но не всегда) только для этих крайних случаев, но при этом использовать векторизацию для остальной части вычислений. Пример: см. методы и .
Данные испытаний
Предположим, у нас есть следующий DataFrame Pandas. Он имеет 2 миллиона строк с 4 столбцами (A,B,C, иD), каждый со случайными значениями из-1000к1000:
df =
A B C D
0 -365 842 284 -942
1 532 416 -102 888
2 397 321 -296 -616
3 -215 879 557 895
4 857 701 -157 480
... ... ... ... ...
1999995 -101 -233 -377 -939
1999996 -989 380 917 145
1999997 -879 333 -372 -970
1999998 738 982 -743 312
1999999 -306 -103 459 745
Я создал этот DataFrame следующим образом:
import numpy as np
import pandas as pd
# Create an array (numpy list of lists) of fake data
MIN_VAL = -1000
MAX_VAL = 1000
# NUM_ROWS = 10_000_000
NUM_ROWS = 2_000_000 # default for final tests
# NUM_ROWS = 1_000_000
# NUM_ROWS = 100_000
# NUM_ROWS = 10_000 # default for rapid development & initial tests
NUM_COLS = 4
data = np.random.randint(MIN_VAL, MAX_VAL, size=(NUM_ROWS, NUM_COLS))
# Now convert it to a Pandas DataFrame with columns named "A", "B", "C", and "D"
df_original = pd.DataFrame(data, columns=["A", "B", "C", "D"])
print(f"df = \n{df_original}")
Тестовое уравнение/расчет
Я хотел продемонстрировать, что все эти методы возможны на нетривиальных функциях или уравнениях, поэтому я намеренно сделал уравнение, которое они вычисляют, требующим:
- заявления
- данные из нескольких столбцов в DataFrame
- данные из нескольких строк в DataFrame
Уравнение, которое мы будем вычислять для каждой строки, следующее. Я составил это произвольно, но думаю, что оно содержит достаточно сложности, чтобы вы могли расширить то, что я сделал, для выполнения любого уравнения, которое вы хотите, в Pandas с полной векторизацией:
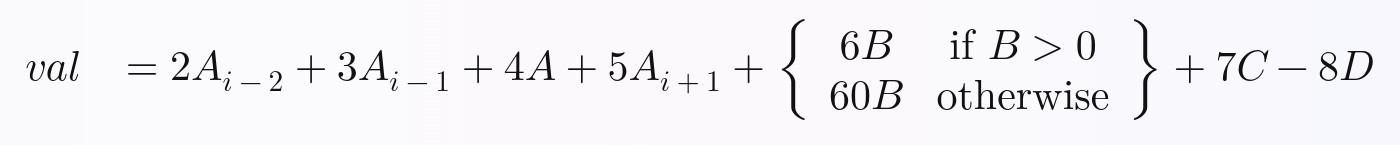
В Python приведенное выше уравнение можно записать следующим образом:
# Calculate and return a new value, `val`, by performing the following equation:
val = (
2 * A_i_minus_2
+ 3 * A_i_minus_1
+ 4 * A
+ 5 * A_i_plus_1
# Python ternary operator; don't forget parentheses around the entire
# ternary expression!
+ ((6 * B) if B > 0 else (60 * B))
+ 7 * C
- 8 * D
)
Альтернативно, вы можете написать это так:
# Calculate and return a new value, `val`, by performing the following equation:
if B > 0:
B_new = 6 * B
else:
B_new = 60 * B
val = (
2 * A_i_minus_2
+ 3 * A_i_minus_1
+ 4 * A
+ 5 * A_i_plus_1
+ B_new
+ 7 * C
- 8 * D
)
Любой из них можно обернуть в функцию. Бывший:
def calculate_val(
A_i_minus_2,
A_i_minus_1,
A,
A_i_plus_1,
B,
C,
D):
val = (
2 * A_i_minus_2
+ 3 * A_i_minus_1
+ 4 * A
+ 5 * A_i_plus_1
# Python ternary operator; don't forget parentheses around the
# entire ternary expression!
+ ((6 * B) if B > 0 else (60 * B))
+ 7 * C
- 8 * D
)
return val
Методы
Полный код доступен для загрузки и запуска в моем этого кодаpython/pandas_dataframe_iteration_vs_vectorization_vs_list_comprehension_speed_tests.pyфайл в моем репозитории .
Вот код для всех 13 техник:
1_raw_for_loop_using_regular_df_indexingval = [np.NAN]*len(df) for i in range(len(df)): if i < 2 or i > len(df)-2: continue val[i] = calculate_val( df["A"][i-2], df["A"][i-1], df["A"][i], df["A"][i+1], df["B"][i], df["C"][i], df["D"][i], ) df["val"] = val # put this column back into the dataframe2_raw_for_loop_using_df.loc[]_indexingval = [np.NAN]*len(df) for i in range(len(df)): if i < 2 or i > len(df)-2: continue val[i] = calculate_val( df.loc[i-2, "A"], df.loc[i-1, "A"], df.loc[i, "A"], df.loc[i+1, "A"], df.loc[i, "B"], df.loc[i, "C"], df.loc[i, "D"], ) df["val"] = val # put this column back into the dataframe3_raw_for_loop_using_df.iloc[]_indexing# column indices i_A = 0 i_B = 1 i_C = 2 i_D = 3 val = [np.NAN]*len(df) for i in range(len(df)): if i < 2 or i > len(df)-2: continue val[i] = calculate_val( df.iloc[i-2, i_A], df.iloc[i-1, i_A], df.iloc[i, i_A], df.iloc[i+1, i_A], df.iloc[i, i_B], df.iloc[i, i_C], df.iloc[i, i_D], ) df["val"] = val # put this column back into the dataframe4_iterrows_in_for_loopval = [np.NAN]*len(df) for index, row in df.iterrows(): if index < 2 or index > len(df)-2: continue val[index] = calculate_val( df["A"][index-2], df["A"][index-1], row["A"], df["A"][index+1], row["B"], row["C"], row["D"], ) df["val"] = val # put this column back into the dataframe
Для всех следующих примеров мы должны сначала подготовить фрейм данных, добавив столбцы с предыдущими и следующими значениями:A_(i-2),A_(i-1), иA_(i+1). Эти столбцы в DataFrame будут называтьсяA_i_minus_2,A_i_minus_1, иA_i_plus_1, соответственно:
df_original["A_i_minus_2"] = df_original["A"].shift(2) # val at index i-2
df_original["A_i_minus_1"] = df_original["A"].shift(1) # val at index i-1
df_original["A_i_plus_1"] = df_original["A"].shift(-1) # val at index i+1
# Note: to ensure that no partial calculations are ever done with rows which
# have NaN values due to the shifting, we can either drop such rows with
# `.dropna()`, or set all values in these rows to NaN. I'll choose the latter
# so that the stats that will be generated with the techniques below will end
# up matching the stats which were produced by the prior techniques above. ie:
# the number of rows will be identical to before.
#
# df_original = df_original.dropna()
df_original.iloc[:2, :] = np.NAN # slicing operators: first two rows,
# all columns
df_original.iloc[-1:, :] = np.NAN # slicing operators: last row, all columns
Запуск векторизованного кода, приведенного выше, для создания этих трех новых столбцов занял в общей сложности 0,044961 секунды.
Теперь перейдем к остальным техникам:
5_itertuples_in_for_loopval = [np.NAN]*len(df) for row in df.itertuples(): val[row.Index] = calculate_val( row.A_i_minus_2, row.A_i_minus_1, row.A, row.A_i_plus_1, row.B, row.C, row.D, ) df["val"] = val # put this column back into the dataframe6_vectorization__with_apply_for_if_statement_corner_casedef calculate_new_column_b_value(b_value): # Python ternary operator b_value_new = (6 * b_value) if b_value > 0 else (60 * b_value) return b_value_new # In this particular example, since we have an embedded `if-else` statement # for the `B` column, pure vectorization is less intuitive. So, first we'll # calculate a new `B` column using # **`apply()`**, then we'll use vectorization for the rest. df["B_new"] = df["B"].apply(calculate_new_column_b_value) # OR (same thing, but with a lambda function instead) # df["B_new"] = df["B"].apply(lambda x: (6 * x) if x > 0 else (60 * x)) # Now we can use vectorization for the rest. "Vectorization" in this case # means to simply use the column series variables in equations directly, # without manually iterating over them. Pandas DataFrames will handle the # underlying iteration automatically for you. You just focus on the math. df["val"] = ( 2 * df["A_i_minus_2"] + 3 * df["A_i_minus_1"] + 4 * df["A"] + 5 * df["A_i_plus_1"] + df["B_new"] + 7 * df["C"] - 8 * df["D"] )7_vectorization__with_list_comprehension_for_if_statment_corner_case# In this particular example, since we have an embedded `if-else` statement # for the `B` column, pure vectorization is less intuitive. So, first we'll # calculate a new `B` column using **list comprehension**, then we'll use # vectorization for the rest. df["B_new"] = [ calculate_new_column_b_value(b_value) for b_value in df["B"] ] # Now we can use vectorization for the rest. "Vectorization" in this case # means to simply use the column series variables in equations directly, # without manually iterating over them. Pandas DataFrames will handle the # underlying iteration automatically for you. You just focus on the math. df["val"] = ( 2 * df["A_i_minus_2"] + 3 * df["A_i_minus_1"] + 4 * df["A"] + 5 * df["A_i_plus_1"] + df["B_new"] + 7 * df["C"] - 8 * df["D"] )8_pure_vectorization__with_df.loc[]_boolean_array_indexing_for_if_statment_corner_caseПри этом используется логическое индексирование , также известное как логическая маска , для выполнения эквивалента утверждения в уравнении. Таким образом, для всего уравнения можно использовать чистую векторизацию, тем самым максимизируя производительность и скорость.
# If statement to evaluate: # # if B > 0: # B_new = 6 * B # else: # B_new = 60 * B # # In this particular example, since we have an embedded `if-else` statement # for the `B` column, we can use some boolean array indexing through # `df.loc[]` for some pure vectorization magic. # # Explanation: # # Long: # # The format is: `df.loc[rows, columns]`, except in this case, the rows are # specified by a "boolean array" (AKA: a boolean expression, list of # booleans, or "boolean mask"), specifying all rows where `B` is > 0. Then, # only in that `B` column for those rows, set the value accordingly. After # we do this for where `B` is > 0, we do the same thing for where `B` # is <= 0, except with the other equation. # # Short: # # For all rows where the boolean expression applies, set the column value # accordingly. # # GitHub CoPilot first showed me this `.loc[]` technique. # See also the official documentation: # https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.loc.html # # =========================== # 1st: handle the > 0 case # =========================== df["B_new"] = df.loc[df["B"] > 0, "B"] * 6 # # =========================== # 2nd: handle the <= 0 case, merging the results into the # previously-created "B_new" column # =========================== # - NB: this does NOT work; it overwrites and replaces the whole "B_new" # column instead: # # df["B_new"] = df.loc[df["B"] <= 0, "B"] * 60 # # This works: df.loc[df["B"] <= 0, "B_new"] = df.loc[df["B"] <= 0, "B"] * 60 # Now use normal vectorization for the rest. df["val"] = ( 2 * df["A_i_minus_2"] + 3 * df["A_i_minus_1"] + 4 * df["A"] + 5 * df["A_i_plus_1"] + df["B_new"] + 7 * df["C"] - 8 * df["D"] )9_apply_function_with_lambdadf["val"] = df.apply( lambda row: calculate_val( row["A_i_minus_2"], row["A_i_minus_1"], row["A"], row["A_i_plus_1"], row["B"], row["C"], row["D"] ), axis='columns' # same as `axis=1`: "apply function to each row", # rather than to each column )10_list_comprehension_w_zip_and_direct_variable_assignment_passed_to_funcdf["val"] = [ # Note: you *could* do the calculations directly here instead of using a # function call, so long as you don't have indented code blocks such as # sub-routines or multi-line if statements. # # I'm using a function call. calculate_val( A_i_minus_2, A_i_minus_1, A, A_i_plus_1, B, C, D ) for A_i_minus_2, A_i_minus_1, A, A_i_plus_1, B, C, D in zip( df["A_i_minus_2"], df["A_i_minus_1"], df["A"], df["A_i_plus_1"], df["B"], df["C"], df["D"] ) ]11_list_comprehension_w_zip_and_direct_variable_assignment_calculated_in_placedf["val"] = [ 2 * A_i_minus_2 + 3 * A_i_minus_1 + 4 * A + 5 * A_i_plus_1 # Python ternary operator; don't forget parentheses around the entire # ternary expression! + ((6 * B) if B > 0 else (60 * B)) + 7 * C - 8 * D for A_i_minus_2, A_i_minus_1, A, A_i_plus_1, B, C, D in zip( df["A_i_minus_2"], df["A_i_minus_1"], df["A"], df["A_i_plus_1"], df["B"], df["C"], df["D"] ) ]12_list_comprehension_w_zip_and_row_tuple_passed_to_funcdf["val"] = [ calculate_val( row[0], row[1], row[2], row[3], row[4], row[5], row[6], ) for row in zip( df["A_i_minus_2"], df["A_i_minus_1"], df["A"], df["A_i_plus_1"], df["B"], df["C"], df["D"] ) ]13_list_comprehension_w__to_numpy__and_direct_variable_assignment_passed_to_funcdf["val"] = [ # Note: you *could* do the calculations directly here instead of using a # function call, so long as you don't have indented code blocks such as # sub-routines or multi-line if statements. # # I'm using a function call. calculate_val( A_i_minus_2, A_i_minus_1, A, A_i_plus_1, B, C, D ) for A_i_minus_2, A_i_minus_1, A, A_i_plus_1, B, C, D # Note: this `[[...]]` double-bracket indexing is used to select a # subset of columns from the dataframe. The inner `[]` brackets # create a list from the column names within them, and the outer # `[]` brackets accept this list to index into the dataframe and # select just this list of columns, in that order. # - See the official documentation on it here: # https://pandas.pydata.org/docs/user_guide/indexing.html#basics # - Search for the phrase "You can pass a list of columns to [] to # select columns in that order." # - I learned this from this comment here: # https://stackoverflow.com/questions/16476924/how-to-iterate-over-rows-in-a-dataframe-in-pandas/55557758#comment136020567_55557758 # - One of the **list comprehension** examples in this answer here # uses `.to_numpy()` like this: # https://stackoverflow.com/a/55557758/4561887 in df[[ "A_i_minus_2", "A_i_minus_1", "A", "A_i_plus_1", "B", "C", "D" ]].to_numpy() # NB: `.values` works here too, but is deprecated. See: # https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.values.html ]
Вот еще раз результаты:
Также используя предварительно сдвинутые ряды в технике 4-х петель.
Я хотел посмотреть, удалят ли этоifпроверка и использование предварительно смещенных строк в методах с четырьмя циклами будет иметь большой эффект:
if i < 2 or i > len(df)-2:
continue
...поэтому я создал этот файл со следующими изменениями: pandas_dataframe_iteration_vs_vectorization_vs_list_comprehension_speed_tests_mod.py. Найдите в файле «MOD:», чтобы найти 4 новых модифицированных метода.
Было лишь небольшое улучшение. Вот результаты этих 17 техник, а 4 новых имеют слово_MOD_в начале имени, сразу после номера. На этот раз это более 500 тысяч строк, а не 2 миллиона:

Еще.iterrtuples()
На самом деле нюансов при использовании больше. Чтобы углубиться в некоторые из них, прочитайте . Вот гистограмма, которую я построил на основе его результатов:
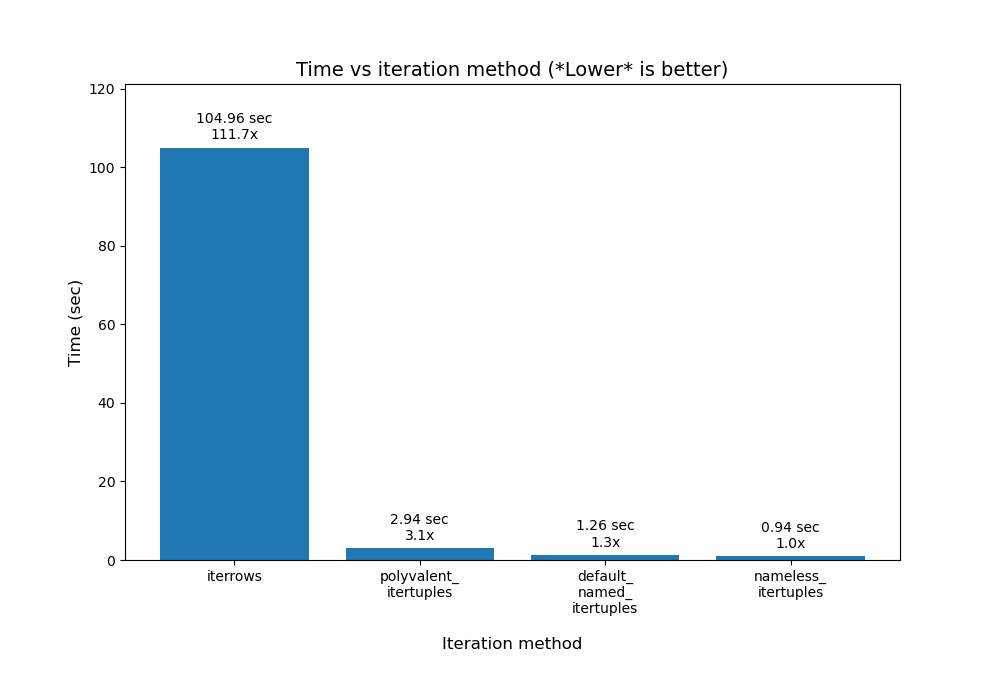
Мой код построения его результатов находится в python/pandas_plot_bar_chart_better_GREAT_AUTOLABEL_DATA.pyв моем репозитории eRCaGuy_hello_worldeRCaGuy_hello_world.eRCaGuy_hello_world
Будущая работа
Использование Cython (Python, скомпилированный в код C) или просто необработанные функции C, вызываемые Python, потенциально может быть быстрее, но я не собираюсь делать это для этих тестов. Я бы рассматривал и тестировал эти варианты только для большой оптимизации.
В настоящее время я не знаю Cython и не чувствую необходимости его изучать. Как вы можете видеть выше, простое правильное использование чистой векторизации уже работает невероятно быстро, обрабатывая 2 миллиона строк всего за 0,1 секунды, или 20 миллионов строк в секунду.
Рекомендации
Куча официальной документации Pandas, особенно
DataFrameдокументация здесь: https://pandas.pydata.org/pandas-docs/stable/reference/frame.html.как говорит здесь @cs95Этот отличный ответ от @cs95 — именно здесь я, в частности, научился использовать понимание списка для перебора DataFrame.
этот ответ @Romain CapronЭтот ответ о
itertuples(), автор @Romain Capron — я внимательно изучил его и отредактировал/отформатировал.Все это мой собственный код, но я хочу отметить, что у меня были десятки чатов с GitHub Copilot (в основном), Bing AI и ChatGPT, чтобы разобраться во многих из этих методов и отладить свой код по ходу работы.
Bing Chat выдал мне красивое уравнение LaTeX со следующей подсказкой. Конечно, я проверил вывод:
Преобразуйте этот код Python в красивое уравнение, которое я могу вставить в Stack Overflow:
val = ( 2 * A_i_minus_2 + 3 * A_i_minus_1 + 4 * A + 5 * A_i_plus_1 # Python ternary operator; don't forget parentheses around the entire ternary expression! + ((6 * B) if B > 0 else (60 * B)) + 7 * C - 8 * D )
Смотрите также
Этот ответ также размещен на моем личном сайте здесь: https://gabrielstaples.com/python_iterate_over_pandas_dataframe/
«программирование массивов»https://en.wikipedia.org/wiki/Array_programming — программирование массивов, или «векторизация»:
В информатике программирование массивов относится к решениям, которые позволяют применять операции ко всему набору значений одновременно. Такие решения обычно используются в научных и инженерных целях.
Современные языки программирования, поддерживающие программирование массивов (также известные как векторные или многомерные языки), были разработаны специально для обобщения операций над скалярами для прозрачного применения к векторам, матрицам и многомерным массивам. К ним относятся APL, J, Fortran, MATLAB, Analytica, Octave, R, Cilk Plus, Julia, Perl Data Language (PDL). В этих языках операцию, которая работает с целыми массивами, можно назвать векторизованной операцией
 независимо от того, выполняется ли она на векторном процессоре, реализующем векторные инструкции.
независимо от того, выполняется ли она на векторном процессоре, реализующем векторные инструкции.Действительно ли циклы for в пандах плохи? Когда мне следует беспокоиться?
Есть ли у pandas iterrows проблемы с производительностью?
- Этот ответ
-
...Основываясь на моих результатах, я бы сказал, что это лучшие подходы в следующем порядке: лучшие в первую очередь:
- векторизация,
- понимание списка,
-
.itertuples(), -
.apply(), - сырой
forпетля, -
.iterrows().
Я не тестировал Cython.
-
- Этот ответ
я рекомендую использоватьdf.at[row, column](источник ). Например :
for row in range(len(df)):
print(df.at[row, 'c1'], df.at[row, 'c2'])
Вывод будет:
10 100
11 110
12 120
Как многие ответы здесь правильно и четко указывают, вы обычно не должны пытаться зацикливаться в Pandas, а должны писать векторизованный код. Но остается вопрос, стоит ли вам когда-либо писать циклы в Pandas, и если да, то как лучше всего использовать цикл в таких ситуациях.
Я считаю, что существует по крайней мере одна общая ситуация, в которой уместны циклы: когда вам нужно вычислить некоторую функцию, которая зависит от значений в других строках несколько сложным образом. В этом случае код цикла часто проще, удобнее для чтения и менее подвержен ошибкам, чем векторизованный код.Код цикла может быть даже быстрее.
Я попытаюсь показать это на примере. Предположим, вы хотите получить кумулятивную сумму столбца, но сбрасывать ее всякий раз, когда какой-либо другой столбец равен нулю:
import pandas as pd
import numpy as np
df = pd.DataFrame( { 'x':[1,2,3,4,5,6], 'y':[1,1,1,0,1,1] } )
# x y desired_result
#0 1 1 1
#1 2 1 3
#2 3 1 6
#3 4 0 4
#4 5 1 9
#5 6 1 15
Это хороший пример, в котором вы, безусловно, могли бы написать одну строку Pandas для достижения этой цели, хотя она не особенно удобочитаема, особенно если вы еще не достаточно опытны с Pandas:
df.groupby( (df.y==0).cumsum() )['x'].cumsum()
Это будет достаточно быстро для большинства ситуаций, хотя вы также можете написать более быстрый код, избегая
В качестве альтернативы, что, если мы запишем это в виде цикла? С NumPy вы можете сделать что-то вроде следующего:
import numba as nb
@nb.jit(nopython=True) # Optional
def custom_sum(x,y):
x_sum = x.copy()
for i in range(1,len(df)):
if y[i] > 0: x_sum[i] = x_sum[i-1] + x[i]
return x_sum
df['desired_result'] = custom_sum( df.x.to_numpy(), df.y.to_numpy() )
По общему признанию, там есть небольшие накладные расходы, необходимые для преобразования столбцов DataFrame в массивы NumPy, но основной фрагмент кода - это всего лишь одна строка кода, которую вы могли бы прочитать, даже если вы ничего не знали о Pandas или NumPy:
if y[i] > 0: x_sum[i] = x_sum[i-1] + x[i]
И этот код на самом деле быстрее векторизованного кода. В некоторых быстрых тестах со 100 000 строк вышеупомянутое примерно в 10 раз быстрее, чем групповой подход. Обратите внимание, что одним из ключей к скорости является numba, то есть параметры. Без строки «@nb.jit» код цикла на самом деле примерно в 10 раз медленнее, чем подход groupby .
Очевидно, что этот пример достаточно прост, и вы, вероятно, предпочтете одну строку панд написанию цикла со связанными с ним накладными расходами. Однако есть более сложные версии этой проблемы, для которых удобочитаемость или скорость подхода цикла NumPy / numba, вероятно, имеет смысл.
Для просмотра и изменения значений я бы использовал iterrows(), В цикле for и с использованием распаковки кортежей (см. Пример: i, row), Я использую row только для просмотра значения и использования i с loc метод, когда я хочу изменить значения. Как указывалось в предыдущих ответах, здесь не следует изменять то, что вы повторяете.
for i, row in df.iterrows():
if row['A'] == 'Old_Value':
df.loc[i,'A'] = 'New_value'
Здесь row в цикле есть копия этой строки, а не ее представление. Таким образом, вы не должны писать что-то вроде row['A'] = 'New_Value', он не изменит DataFrame. Тем не менее, вы можете использовать i а также loc и укажите DataFrame для выполнения работы.
Существует так много способов перебора строк в панде. Один очень простой и интуитивно понятный способ:
df=pd.DataFrame({'A':[1,2,3], 'B':[4,5,6],'C':[7,8,9]})
print(df)
for i in range(df.shape[0]):
# For printing the second column
print(df.iloc[i,1])
# For printing more than one columns
print(df.iloc[i,[0,2]])
Самый простой способ - использовать
apply функция
def print_row(row):
print row['c1'], row['c2']
df.apply(lambda row: print_row(row), axis=1)
Наверное, самое элегантное решение (но, конечно, не самое эффективное):
for row in df.values:
c2 = row[1]
print(row)
# ...
for c1, c2 in df.values:
# ...
Обратите внимание, что:
- документация явно рекомендует использование
.to_numpy()вместо - это может быть плохой идеей для
DataFrames со столбцами смешанного типа - есть веские причины не использовать цикл в первую очередь
Тем не менее, я думаю, что этот вариант должен быть включен здесь как прямое решение (как кажется) тривиальной проблемы.
Вы также можете сделать numpy индексация для еще больших ускорений. На самом деле это не итерация, но она работает намного лучше, чем итерация для определенных приложений.
subset = row['c1'][0:5]
all = row['c1'][:]
Вы также можете привести его к массиву. Предполагается, что эти индексы / выборки уже действуют как массивы Numpy, но я столкнулся с проблемами и должен был разыграть
np.asarray(all)
imgs[:] = cv2.resize(imgs[:], (224,224) ) #resize every image in an hdf5 file
df.iterrows() возвращает кортеж (a,b), где a - индекс, а b - строка.
1. Перебратьdf.indexи доступ черезat[]
Вполне читаемый метод — перебор индекса (как предложено @Grag2015). Однако вместо используемой там цепной индексации используйтеatпо эффективности:
for ind in df.index:
print(df.at[ind, 'col A'])
Преимущество этого метода передfor i in range(len(df))это работает, даже если индекс неRangeIndex. См. следующий пример:
df = pd.DataFrame({'col A': list('ABCDE'), 'col B': range(5)}, index=list('abcde'))
for ind in df.index:
print(df.at[ind, 'col A'], df.at[ind, 'col B']) # <---- OK
df.at[ind, 'col C'] = df.at[ind, 'col B'] * 2 # <---- can assign values
for ind in range(len(df)):
print(df.at[ind, 'col A'], df.at[ind, 'col B']) # <---- KeyError
Если требуется целочисленное расположение строки (например, чтобы получить значения предыдущей строки), оберните ееenumerate():
for i, ind in enumerate(df.index):
prev_row_ind = df.index[i-1] if i > 0 else df.index[i]
df.at[ind, 'col C'] = df.at[prev_row_ind, 'col B'] * 2
2. Используйте с
Хотя это намного быстрее, чемiterrows(), основным недостатком является то, что он искажает метки столбцов, если они содержат пробел (например,'col C'становится_1и т. д.), что затрудняет доступ к значениям в итерации.
Вы можете использоватьdf.columns.get_loc()чтобы получить целочисленное местоположение метки столбца и использовать его для индексации именованных кортежей. Обратите внимание, что первым элементом каждого именованного кортежа является метка индекса, поэтому для правильного доступа к столбцу по целочисленной позиции вам нужно либо добавить 1 ко всему, что возвращается изget_locили распакуйте кортеж вначале.
df = pd.DataFrame({'col A': list('ABCDE'), 'col B': range(5)}, index=list('abcde'))
for row in df.itertuples(name=None):
pos = df.columns.get_loc('col B') + 1 # <---- add 1 here
print(row[pos])
for ind, *row in df.itertuples(name=None):
# ^^^^^^^^^ <---- unpacked here
pos = df.columns.get_loc('col B') # <---- already unpacked
df.at[ind, 'col C'] = row[pos] * 2
print(row[pos])
3. Преобразование в словарь и повторение
Другой способ перебрать кадр данных — преобразовать его в словарь вorient='index'и перебратьdict_itemsилиdict_values.
df = pd.DataFrame({'col A': list('ABCDE'), 'col B': range(5)})
for row in df.to_dict('index').values():
# ^^^^^^^^^ <--- iterate over dict_values
print(row['col A'], row['col B'])
for index, row in df.to_dict('index').items():
# ^^^^^^^^ <--- iterate over dict_items
df.at[index, 'col A'] = row['col A'] + str(row['col B'])
Это не искажает такие типы данных, какiterrows, не искажает метки столбцов, напримерitertuplesи не зависит от количества столбцов (zip(df['col A'], df['col B'], ...)если столбцов много, то быстро станет громоздким).
Наконец, как уже упоминалось в @cs95 , избегайте циклов, насколько это возможно. Особенно если ваши данные числовые, если вы немного покопаетесь, в библиотеке найдется оптимизированный метод для вашей задачи.
Тем не менее, в некоторых случаях итерация более эффективна, чем векторизованные операции. Одной из распространенных таких задач является сохранение кадра данных pandas во вложенный json. По крайней мере, начиная с pandas 1.5.3,itertuples()цикл выполняется намного быстрее, чем любая векторизованная операция, включающаяgroupby.applyметод в таком случае.
В этом примере iloc используется для выделения каждой цифры в кадре данных.
import pandas as pd
a = [1, 2, 3, 4]
b = [5, 6, 7, 8]
mjr = pd.DataFrame({'a':a, 'b':b})
size = mjr.shape
for i in range(size[0]):
for j in range(size[1]):
print(mjr.iloc[i, j])
Отказ от ответственности: хотя здесь так много ответов, которые рекомендуют не использовать итеративный (циклический) подход (и я в основном согласен), я все же считаю его разумным подходом для следующей ситуации:
Расширить кадр данных данными из сетевого запроса
Допустим, у вас есть большой фрейм данных, который содержит неполные пользовательские данные. Теперь вам нужно расширить эти данные дополнительными столбцами, например
ageа также
gender.
Оба значения должны быть получены из внутреннего API. Затраты (время ожидания) для сетевого запроса намного превосходят итерацию кадра данных. Мы говорим о времени прохождения сети туда и обратно в сотни миллисекунд по сравнению с ничтожно малым выигрышем при использовании альтернативных подходов к итерациям.
1 дорогостоящий сетевой запрос для каждой строки
Так что в этом случае я бы предпочел использовать итеративный подход. Хотя сетевой запрос стоит дорого, он гарантированно запускается только один раз для каждой строки в кадре данных. Вот пример использования DataFrame.iterrows:
Пример
for index, row in users_df.iterrows():
user_id = row['user_id']
# trigger expensive network request once for each row
response_dict = backend_api.get(f'/api/user-data/{user_id}')
# extend dataframe with multiple data from response
users_df.at[index, 'age'] = response_dict.get('age')
users_df.at[index, 'gender'] = response_dict.get('gender')