Как ждать завершения запросов GenerateTableFetch
Мой вариант использования такой. У меня есть несколько X-таблиц, которые можно извлечь из MySQL. Я разделяю их, используя SplitText поместить каждую таблицу в отдельный файл потока и вытащить, используя GenerateTableFetch а также ExecuteSQL,
И я хочу получать уведомления или ставить какие-то другие действия, когда импорт будет выполнен для всех таблиц. В SplitText текстовый процессор я маршрутизировал original отношение к Wait на ${filename} с целевым количеством ${fragment.count}, Это будет отслеживать, сколько таблиц сделано.
Но сейчас я не могу понять, как узнать, когда конкретный стол готов. GenerateTableFetch разветвляет файл потока на несколько в зависимости от размера раздела. Но он не записывает такие атрибуты, как фрагмент.счет, которые я могу использовать для ожидания каждой таблицы.
Есть ли способ, которым я могу достичь этого? Или, может быть, есть способ узнать в конце всего потока, все ли файлы потока в потоке были обработаны и ничего не находится в очереди или обрабатывается?
2 ответа
До тех пор, пока поддержка NiFi добавить для этого, мне удалось заставить его работать, используя MergeContent, Использовать table_name как Correlation attribute name а затем использовать merged отношении Wait использование процессора ${merge.count} как цель. Смотрите скриншоты, если кто-то хочет сделать то же самое.
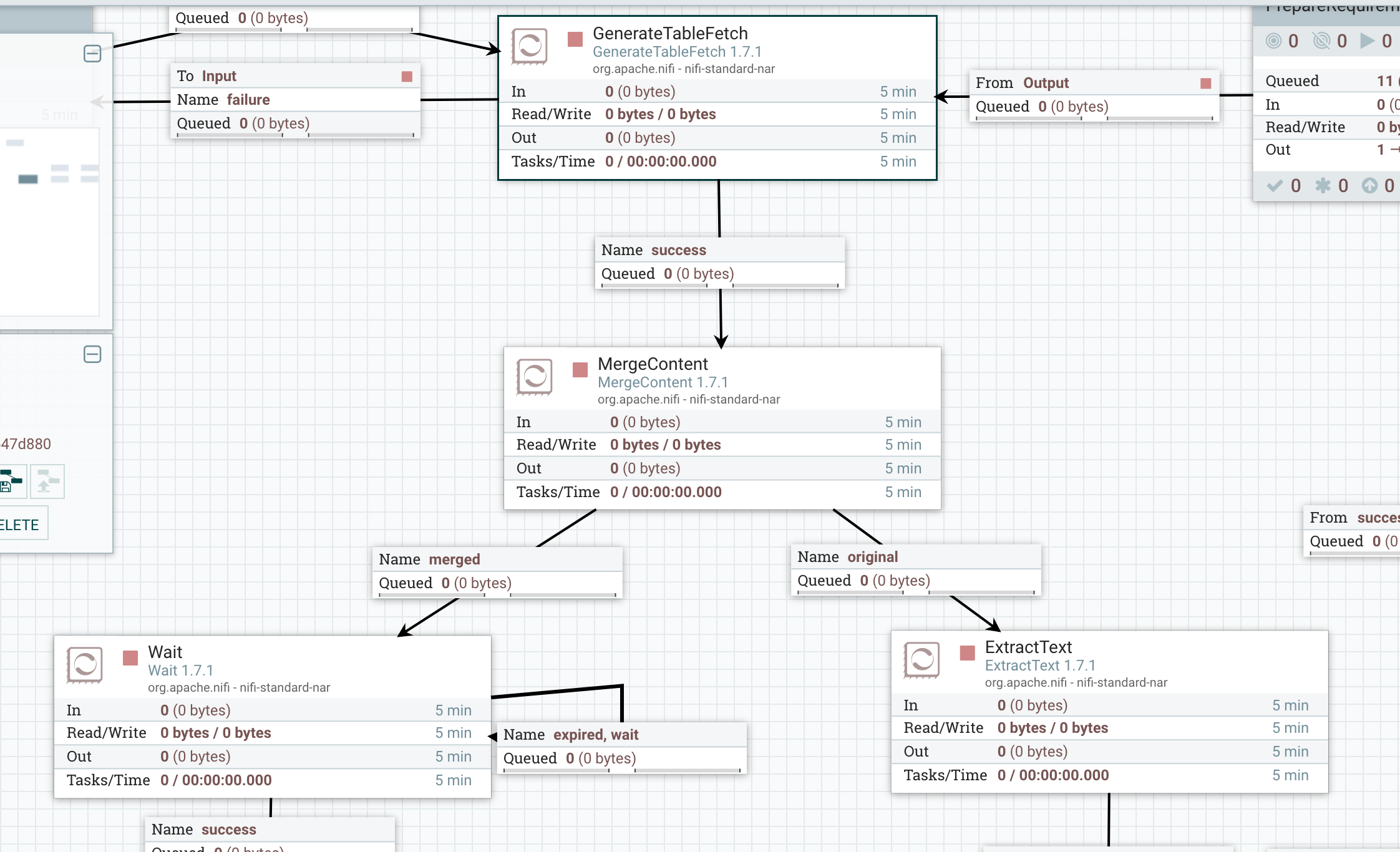


Если у вас есть автономный экземпляр NiFi (или вы не распределяете файлы потока между кластером по узлам ExecuteSQL), вы можете вместо этого использовать QueryDatabaseTable, он (по умолчанию) будет выдавать все файлы потока только при обработке всего набора результатов. Если все строки входят в один файл потока, то тот факт, что файл потока был передан в нисходящем направлении, указывает на то, что выборка завершена.
Я написал NIFI-5601, чтобы рассказать об улучшении добавления атрибутов фрагмента.* В потоковые файлы, сгенерированные GTF.