Панды нечеткие обнаруживают дубликаты
Как можно использовать нечеткое сопоставление в пандах для обнаружения дублирующих строк (эффективно)
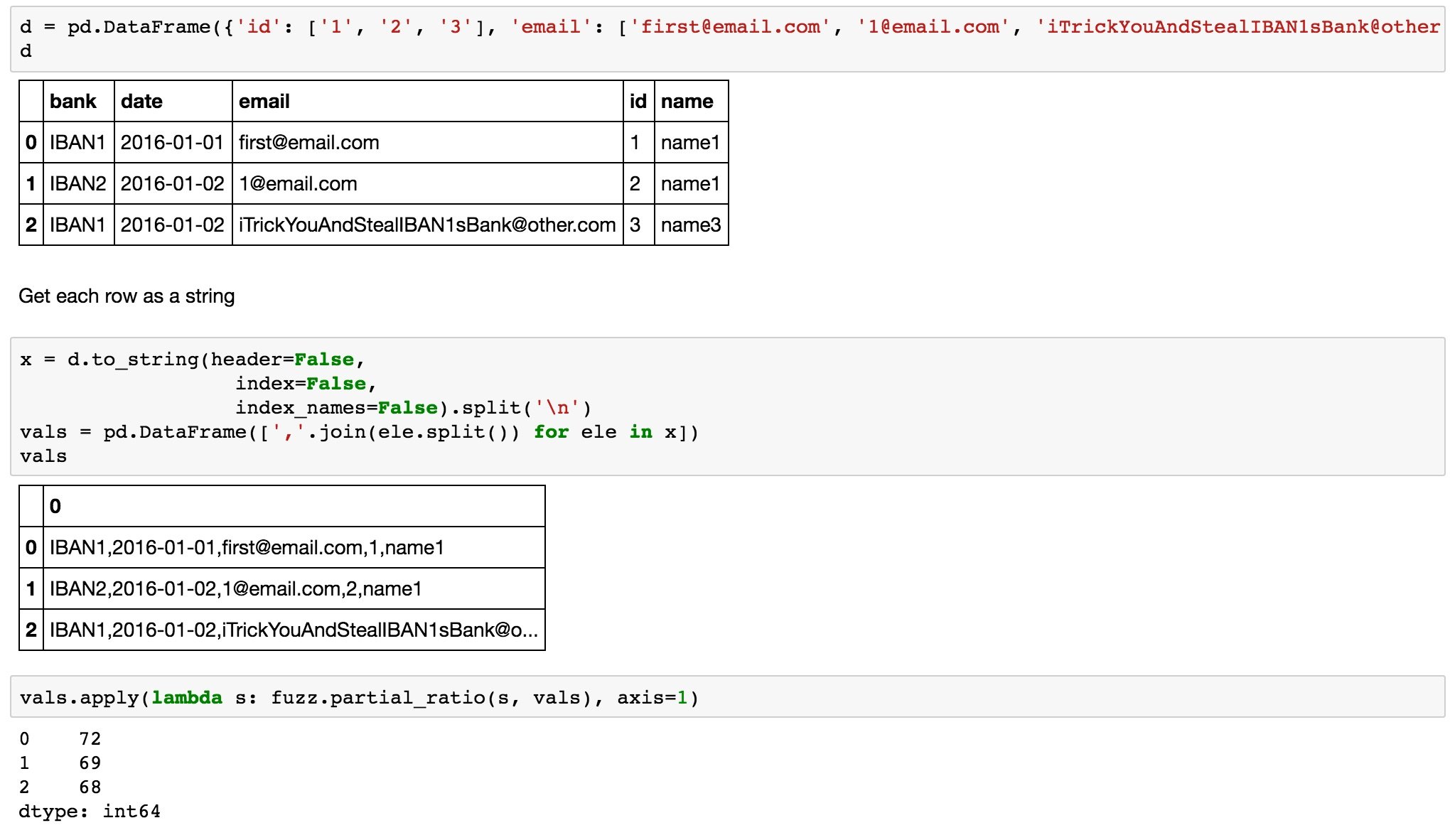
Как найти дубликаты одного столбца против всех остальных без гигантского цикла for преобразования row_i toString() и сравнения его со всеми остальными?
1 ответ
Не специфично для панд, но в экосистеме питона библиотека дедупеонов, похоже, делает то, что вы хотите. В частности, он позволяет сравнивать каждый столбец строки в отдельности, а затем объединять информацию в единую оценку вероятности совпадения.
pandas-dedupe - ваш друг здесь. Вы можете попробовать сделать следующее:
import pandas as pd
from pandas_deudpe import dedupe_dataframe
df = pd.DataFrame.from_dict({'bank':['bankA', 'bankA', 'bankB', 'bankX'],'email':['email1', 'email1', 'email2', 'email3'],'name':['jon', 'john', 'mark', 'pluto']})
dd = dedupe_dataframe(df, ['bank', 'name', 'email'], sample_size=1)
Если вы также хотите установить каноническое имя для тех же объектов, установите canonicalize=True.
[Я один из участников pandas-dedupe]
Теперь существует пакет, упрощающий использование библиотеки дедупликации с пандами: pandas-dedupe
(Я разработчик исходной библиотеки дедупликации, но не пакета pandas-dedupe)