SSIS конвертировать между Unicode и Non-Unicode Error
У меня есть пакет ssis, где я использую источник OLEDB, ссылающийся на таблицу SQL Server 2005. Все столбцы, кроме столбца даты, являются NVARCHAR(255). Я использую пункт назначения Excel и использую оператор SQL для создания листа в книге Excel, SQL находится в диспетчере соединений Excel (фактически это оператор создания таблицы, который создает лист) и выводится из сопоставления столбцов из DB.
Независимо от того, что я сделал, я получаю эту ошибку преобразования unicode -> non-unicode между моим источником и местом назначения. Попробовал преобразование в строку [DT_STR] между S > D, удалил ее, изменил таблицу SQL VARCHAR на NVARCHAR и все еще получаю эту ошибку flippin.
Поскольку я создаю лист в Excel с помощью оператора SQL, я не вижу никакого способа заранее определить, какие типы данных столбцов будут в листе Excel. Я предполагаю, что это будут метаданные по умолчанию, но я не знаю.
Итак, как я могу предотвратить появление этой ошибки между назначением таблицы SQL и созданием листа Excel с этим SQL-оператором SSIS?
Моя ошибка:
Ошибка при выполнении задачи потока данных [Источник OLE DB [1]]: столбец "MyColumn" не может преобразовывать строковые типы данных в формате Unicode и Unicode.
И для всех nvarchar столбцов.
Цени любую помощь
Спасибо
Эндрю
13 ответов
Ниже Шаги работали для меня:
1). щелкните правой кнопкой мыши на исходной задаче.
2). нажмите "Показать расширенный редактор". расширенная опция редактирования исходной задачи в ssis
3). Перейдите на вкладку "Свойства входа и выхода".
4). выберите выходной столбец, для которого вы получаете ошибку.
5). Тип данных будет "String [DT_STR]".
6). Измените этот тип данных на "Строка Unicode [DT_WSTR]". Изменение типа данных на строку Unicode
7). сохрани и закрой. Надеюсь это поможет!
Добавьте преобразования "Преобразование данных" для преобразования строковых столбцов из строк не в Юникоде (DT_STR) в строки Юникода (DT_WSTR).
Вы должны сделать это для всех строковых столбцов...
Недостающий кусок здесь Data Conversion объект. Он должен находиться между источником OLE DB и объектом назначения.
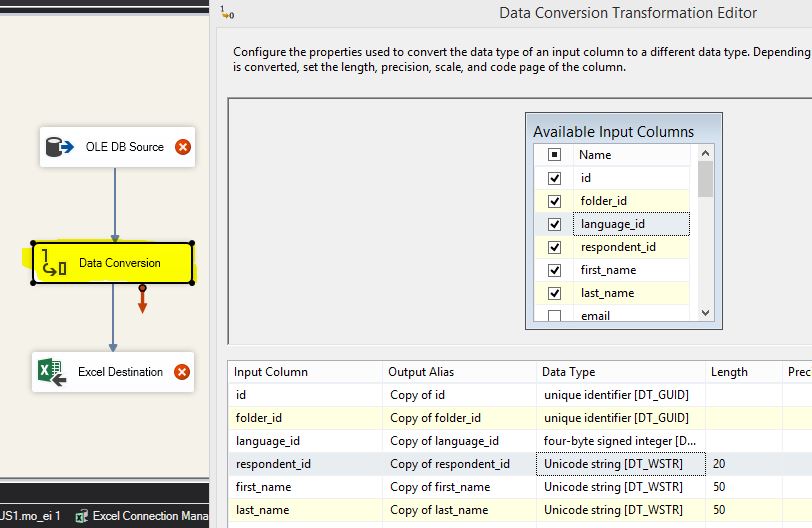
Сначала добавьте блок преобразования данных в диаграмму потока данных.
Откройте блок преобразования данных и отметьте столбец, для которого отображается ошибка. Ниже измените его тип данных на строку Unicode (DT_WSTR) или любой другой тип данных и сохраните его.
Перейти к блоку назначения. Перейдите к отображению в нем и сопоставьте вновь созданный элемент с соответствующим адресом и сохраните.
Щелкните правой кнопкой мыши свой проект в решении explorer.select properties. Выберите свойства конфигурации и выберите отладку в нем. В этом случае установите для параметра Run64BitRunTime значение false (поскольку Excel не очень хорошо обрабатывает 64-разрядное приложение).
Вместо добавления ранее предложенного преобразования данных вы можете привести столбец nvarchar к столбцу varchar. Это предотвращает ненужный шаг и имеет более высокую производительность, чем альтернатива.
В выборе вашего оператора SQL заменить date с CAST(date AS varchar([size])), По какой-то причине это еще не меняет тип выходных данных. Для этого сделайте следующее:
- Щелкните правой кнопкой мыши на шаге OLE DB Source и откройте расширенный редактор.
- Перейти к входным и выходным свойствам
- Выберите столбцы вывода
- Выберите свой столбец
- В разделе Свойства типа данных измените Data Type на строку [DT_STR]
- Измените длину на длину, указанную в заявлении CAST
После этого ваши исходные данные будут выведены как varchar, и ваша ошибка исчезнет.
Никто, кажется, не упоминает об этом, но преобразование varchar в nvarchar в исходном запросе также решает проблему.
У меня возникла та же проблема, и я попробовал все, что здесь написано, но это все равно давало мне ту же ошибку. В столбце, который я пытался преобразовать, оказалось значение NULL.
Удаление значения NULL решило мою проблему.
Ура, Ахмед
В приведенном выше примере я продолжал терять значения, я думаю, что задержка проверки позволит сохранить новые типы данных как часть метаданных.
В диспетчере соединений для "Диспетчера соединений Excel" установите для параметра "Проверка задержки" значение "Ложь" в свойствах.
Затем в задаче потока данных для Excel установите для ValidationExternalMetaData значение False, опять же из свойств.
Теперь это позволит вам щелкнуть правой кнопкой мыши по Задаче назначения Excel и перейти к Расширенному редактору для пункта назначения Excel -> крайняя правая вкладка - Свойства ввода и вывода. В разделе папок "Внешние столбцы" теперь вы можете изменить значения "Типы данных" и "Длина" проблемных столбцов, и теперь их можно сохранить.
Удачи!
Я столкнулся с этим условием, когда установил 32-разрядный клиент Oracle версии 12, подключенный к серверу Oracle 12, работающему в Windows. Хотя Oracle-source и SqlServer-destination НЕ являются Unicode, я продолжал получать это сообщение, как если бы колонки оракула были Unicode. Я решил проблему, вставив поле преобразования данных и выбрав тип DT-STR (не Unicode) для полей varchar2 и DT-WSTR (Unicode) для числовых полей, затем я удалил "COPY OF" из имени выходного поля. Обратите внимание, что я продолжал получать ошибку, потому что я соединил стрелку окна источника с окном конвертации ДО установки типов конверсии. Таким образом, мне пришлось переключить окно источника, и это очистило все ошибки в поле назначения.
Я думаю, людям этого не хватает. В моем случае у меня было 100 символьных столбцов для преобразования между Oracle и MS Sql. Вся эта информация о преобразовании данных и расширенном редакторе невероятно утомительна, если у вас есть столбцы из 100 символов. Кроме того, SSIS является SSIS, он иногда сбрасывает все ваши 100 изменений расширенного редактора, даже если вы установите для VALIDATEEXTERNALMETADATA значение false, что невероятно неприятно. Я бы не возражал против преобразования данных, если бы в этом была какая-то ценность, но 20 лет назад инструменты ETL использовали для преобразования символа оракула в символы ms sql без суеты. То, что говорят Бакалоло и Зафер, является ответом, если у вас много символьных столбцов и вы можете жить с nvarchar, просто объявите все свои столбцы nvarchar в ms sql. Я также обнаружил, что новый Oracle Source (2021) не жалуется на преобразование Unicode в varchar в ms sql.
При создании таблицы в SQL Server сделайте столбцы таблицы
NVARCHAR вместо
VARCHAR.
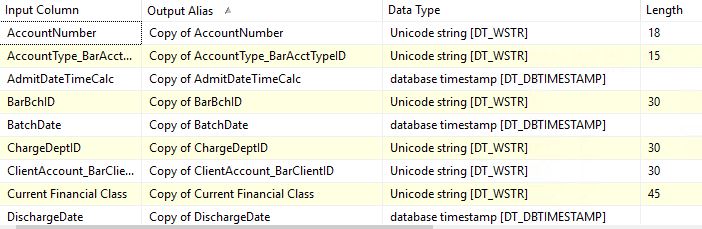
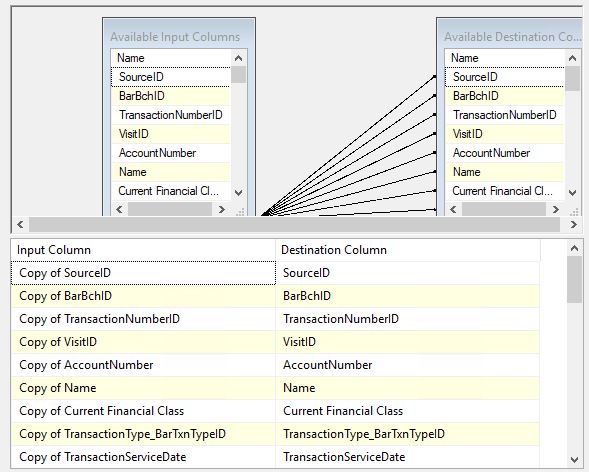
Я знаю, что это очень старый пост, но я столкнулся с той же проблемой и обнаружил, что мне пришлось вручную выбрать выходной псевдоним компонента преобразования в качестве сопоставления в целевом компоненте Excel . Поскольку имена источника OLE DB совпадают с именами столбцов excel, он сопоставлялся с OLE DB, а не с выходным псевдонимом . Например, столбец SourceID из компонента OLE DB, получивший имя Копия SourceID после преобразования. Я не вижу исходного вопроса о том, что они специально выбрали новое имя псевдонима, которое они сопоставили со столбцами БД. Сообщение @Serge Voloshenko подходит ближе всего, но также не упоминает, чтобы убедиться, что отображение происходит. Новый пользователь SSIS может не заметить этого.

Я просто сталкиваюсь с той же проблемой, я решаю ее в своем запросе SQL: используя преобразование напрямую
CONVERT(NVARCHAR(50),'') AS MyVarName
Мне нужно поместить пустую строку (или исправить размер строки) в файл excel. Преобразование принудительного типа MyVarName из DT-STR в DT-WSTR (юникод)