Какая разница между размером и количеством в пандах?
В этом разница между groupby("x").count а также groupby("x").size в пандах?
Размер только исключает ноль?
3 ответа
size включает в себя NaN ценности, count не:
In [46]:
df = pd.DataFrame({'a':[0,0,1,2,2,2], 'b':[1,2,3,4,np.NaN,4], 'c':np.random.randn(6)})
df
Out[46]:
a b c
0 0 1 1.067627
1 0 2 0.554691
2 1 3 0.458084
3 2 4 0.426635
4 2 NaN -2.238091
5 2 4 1.256943
In [48]:
print(df.groupby(['a'])['b'].count())
print(df.groupby(['a'])['b'].size())
a
0 2
1 1
2 2
Name: b, dtype: int64
a
0 2
1 1
2 3
dtype: int64
Помимо уже упомянутых, подумал, что я бы указал на пару дополнительных случаев для вашей справки.
Как уже упоминалось в других ответах, основное отличие состоит в том, что count исключит количество NaNs, в то время как size будет считать все элементы. GroupBy показывает, что он делает это различие на основе вывода, возвращаемого при вызове этих функций:
np.random.seed(0)
df = pd.DataFrame(np.random.choice(3, (5, 2)), columns=list('AB'))
df
A B
0 0 1
1 0 1
2 1 2
3 0 2
4 0 0
GroupBy.count возвращает DataFrame при вызове count на всех столбцах,
result = df.groupby('A').count()
result
B
A
0 4
1 1
type(result)
# pandas.core.frame.DataFrame
В то время как GroupBy.size возвращает серию:
result = df.groupby('A').size()
result
A
0 4
1 1
dtype: int64
type(result)
# pandas.core.series.Series
Причина в том, что size одинаково для всех столбцов, поэтому возвращается только один результат. Между тем, count для каждого столбца может отличаться в зависимости от количества NaN в каждом столбце.
Другой пример - как pivot_table относится к этим данным. Предположим, мы хотели бы вычислить кросс-табуляцию
df
A B
0 0 1
1 0 1
2 1 2
3 0 2
4 0 0
pd.crosstab(df.A, df.B) # Result we expect, but with `pivot_table`.
B 0 1 2
A
0 1 2 1
1 0 0 1
С pivot_tableможно оформить size:
df.pivot_table(index='A', columns='B', aggfunc='size', fill_value=0)
B 0 1 2
A
0 1 2 1
1 0 0 1
Но count не работает; пустой DataFrame возвращается:
df.pivot_table(index='A', columns='B', aggfunc='count')
Empty DataFrame
Columns: []
Index: [0, 1]
Я считаю, что причина этого в том, что 'count' должно быть сделано на серии, которая передается в values аргумент, и когда ничего не передается, панда решает не делать никаких предположений.
Просто добавьте немного к ответу @Edchum, даже если данные не имеют значений NA, результат count() более подробный, используя приведенный выше пример:
grouped = df.groupby('a')
grouped.count()
Out[197]:
b c
a
0 2 2
1 1 1
2 2 3
grouped.size()
Out[198]:
a
0 2
1 1
2 3
dtype: int64
Когда мы имеем дело с обычными фреймами данных, то единственной разницей будет включение значений NAN, что означает, что count не включает значения NAN при подсчете строк.
Но если мы используем эти функции с groupby затем, чтобы получить правильные результаты count() мы должны связать любое числовое поле с groupby чтобы получить точное количество групп, где для size() нет необходимости в этом типе ассоциации.
В дополнение ко всем приведенным выше ответам я хотел бы указать еще на одно различие, которое мне кажется значительным.
Вы можете соотнести Панды Datarame размер и количество с помощью Java Vectorsразмер и длина. Когда мы создаем вектор, ему выделяется некоторая предопределенная память. когда мы приближаемся к количеству элементов, которое он может занимать при добавлении элементов, ему выделяется больше памяти. Точно так же вDataFrame по мере добавления элементов память, выделенная для него, увеличивается.
Атрибут размера дает номер ячейки памяти, выделенной для DataFrame тогда как count дает количество элементов, которые фактически присутствуют в DataFrame. Например,
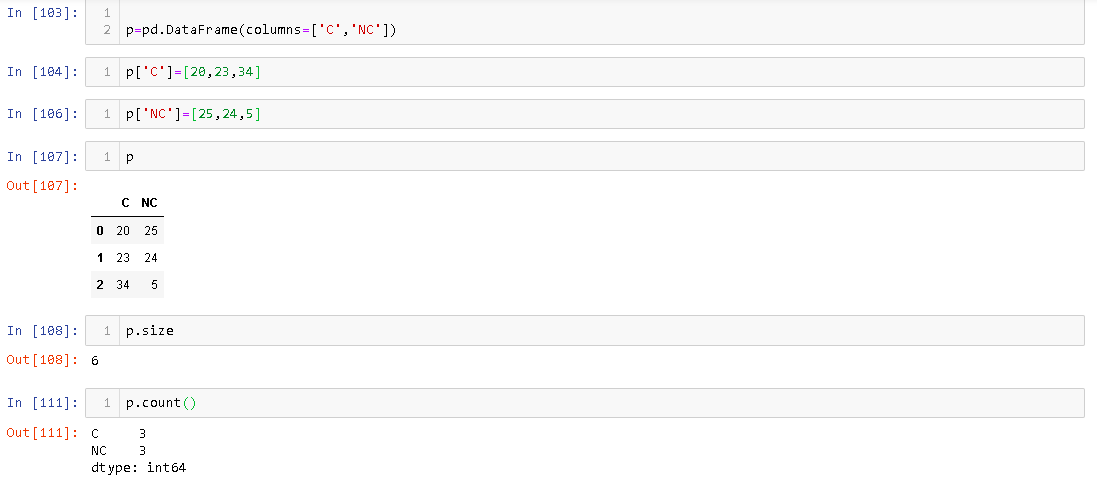
Вы можете видеть, что в DataFrame, его размер - 6.
Этот ответ охватывает разницу в размере и количестве DataFrame и нет Pandas Series. Я не проверял, что происходит сSeries