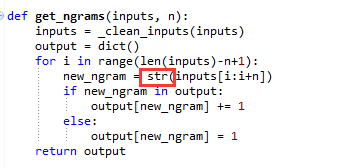
Как получить тот же результат в книге "Соскребание в сети с помощью Python: сбор данных из современного Интернета", глава 7, раздел "Нормализация данных".
Версия Python: 2.7.10
Мой код:
# -*- coding: utf-8 -*-
from urllib2 import urlopen
from bs4 import BeautifulSoup
from collections import OrderedDict
import re
import string
def cleanInput(input):
input = re.sub('\n+', " ", input)
input = re.sub('\[[0-9]*\]', "", input)
input = re.sub(' +', " ", input)
# input = bytes(input, "UTF-8")
input = bytearray(input, "UTF-8")
input = input.decode("ascii", "ignore")
cleanInput = []
input = input.split(' ')
for item in input:
item = item.strip(string.punctuation)
if len(item) > 1 or (item.lower() == 'a' or item.lower() == 'i'):
cleanInput.append(item)
return cleanInput
def ngrams(input, n):
input = cleanInput(input)
output = []
for i in range(len(input)-n+1):
output.append(input[i:i+n])
return output
url = 'https://en.wikipedia.org/wiki/Python_(programming_language)'
html = urlopen(url)
bsObj = BeautifulSoup(html, 'lxml')
content = bsObj.find("div", {"id": "mw-content-text"}).get_text()
ngrams = ngrams(content, 2)
keys = range(len(ngrams))
ngramsDic = {}
for i in range(len(keys)):
ngramsDic[keys[i]] = ngrams[i]
# ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True))
ngrams = OrderedDict(sorted(ngramsDic.items(), key=lambda t: t[1], reverse=True))
print ngrams
print "2-grams count is: " + str(len(ngrams))
Недавно я узнал, как выполнять очистку веб-страниц, следуя книге Web Scraping with Python: Сбор данных из современного Интернета, в то время как в главе 7 "Нормализация данных " я сначала пишу код, такой же, как показано в книге, и получил сообщение об ошибке с терминала:
Traceback (most recent call last):
File "2grams.py", line 40, in <module>
ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True))
AttributeError: 'list' object has no attribute 'items'
Поэтому я изменил код, создав новый словарь, в котором объектами являются списки ngrams, Но у меня совсем другой результат:
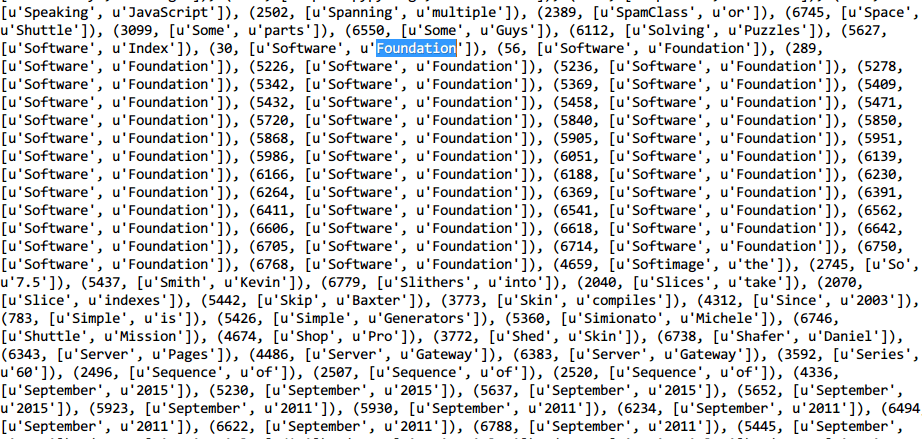
Вопрос:
- Если я хочу получить результат, как показано в книге ( где отсортированы по значениям и частоте), должен ли я написать свои собственные строки для подсчета вхождения каждого 2-грамма, или код в книге уже имел эту функцию (коды в книга была на питоне 3 кода)? записать пример кода на github
- Частота в моем выводе была совсем другой с авторским, например
[u'Software', u'Foundation']происходили 37 раз, но не 40. Какие причины вызвали эту разницу (это могут быть ошибки моего кода)?
Скриншот книги:


5 ответов
У меня такая же проблема, когда я читаю эту книгу.Нграммы должны быть продиктованы. Python версия 3.4
вот мой код:
from urllib.request import urlopen
from bs4 import BeautifulSoup
from collections import OrderedDict
import re
import string
def cleanInput(input):
input = re.sub('\n+',' ', input)
input = re.sub('\[0-9]*\]', '', input)
input = re.sub('\+', ' ', input)
input = bytes(input, 'utf-8')
input = input.decode('ascii', 'ignore')
cleanInput = []
input = input.split(' ')
for item in input:
item = item.strip(string.punctuation)
if len(item) >1 or (item.lower() == 'a' or item.lower() == 'i'):
cleanInput.append(item)
return cleanInput
def ngrams(input, n):
input = cleanInput(input)
output = []
for i in range(len(input)-n+1):
output.append(input[i:i+n])
return output
html = urlopen("http://en.wikipedia.org/wiki/Python_(programming_language)")
bsObj = BeautifulSoup(html, "lxml")
content = bsObj.find("div", {"id": "mw-content-text"}).get_text()
ngrams1 = ngrams(content, 2)
#ngrams1 is something like this [['This', 'article'], ['article', 'is'], ['is', 'about'], ['about', 'the'], ['the', 'programming'], ['programming', 'language'],
ngrams = {}
for i in ngrams1:
j = str(i) #the key of ngrams should not be a list
ngrams[j] = ngrams.get(j, 0) + 1
# ngrams.get(j, 0) means return a value for the given key j. If key j is not available, then returns default value 0.
# when key j appear again, ngrams[j] = ngrams[j]+1
ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True))
print(ngrams)
print("2-grams count is:"+str(len(ngrams)))
Это часть моего результата:
OrderedDict([("['Python', 'Software']", 37), ("['Software', 'Foundation']", 37), ("['of', 'the']", 37), ("['of', 'Python']", 35), ("['Foundation', 'Retrieved']", 32),
В этой главе тоже произошла ошибка, потому что ngrams был списком. Я преобразовал его в диктовку, и это сработало
ngrams1 = OrderedDict(sorted(dict(ngrams1).items(), key=lambda t: t[1], reverse=True))
В списке нет элемента. Я просто изменил список, чтобы диктовать. Вот мой код, который я изменил
def ngrams(input, n):
input = cleanInput(input)
output = dict()
for i in range(len(input)-n+1):
new_ng = " ".join(input[i:i+n])
if new_ng in output:
output[new_ng] += 1
else:
output[new_ng] = 1
return output
Более элегантным решением этого было бы использование collection.defaultdict.
Вот мой код (с использованием Python 2.7+):
import requests
import re
import string
from bs4 import BeautifulSoup
from collections import OrderedDict, defaultdict
def clean_input(input):
input = re.sub('\n+', " ", input)
input = re.sub('\[[0-9]*\]', "", input)
input = re.sub(' +', " ", input)
input = bytes(input).decode(encoding='utf-8')
input = input.encode(encoding='ascii', errors='ignore')
clean_input = []
input = input.split(' ')
for item in input:
item = item.strip(string.punctuation)
if len(item) > 1 or (item.lower() == 'a' or item.lower() == 'i'):
clean_input.append(item)
return clean_input
def ngrams(input, n):
input = clean_input(input)
output = []
for i in xrange(len(input)-n+1):
output.append(input[i:i+n])
return output
response = requests.get("http://en.wikipedia.org/wiki/Python_(programming_language")
bsObj = BeautifulSoup(response.content, "html.parser")
content = bsObj.find("div", {"id":"mw-content-text"}).get_text()
ngrams1 = ngrams(content, 2)
ngrams = defaultdict(int)
for k in ngrams1:
ngrams[str(k)] += 1
ngrams = OrderedDict(sorted(ngrams.items(), key=(lambda t: t[1]), reverse=True))
print ngrams
print "2-grams count is: %d" % len(ngrams)
Это часть моего результата:
OrderedDict([("['Python', 'programming']", 5), ("['programming', 'language']", 4), ("['for', 'Python']", 3), ("['the', 'page']", 2), ("['language', 'in']", 2), ("['sister', 'projects']", 1), ("['language', 'article']", 1), ("['page', 'I']", 1), ("['see', 'Why']", 1),
На самом деле, большинство наших книг по программированию уже сказали вам, где найти материал или код о книге, которую вы читаете.
Для этой книги вы можете найти весь пример кода по адресу:
http://pythonscraping.com/code/ и перенаправит вас на
https://github.com/REMitchell/python-scraping.
Тогда вы можете найти свой код в папке chapter7. 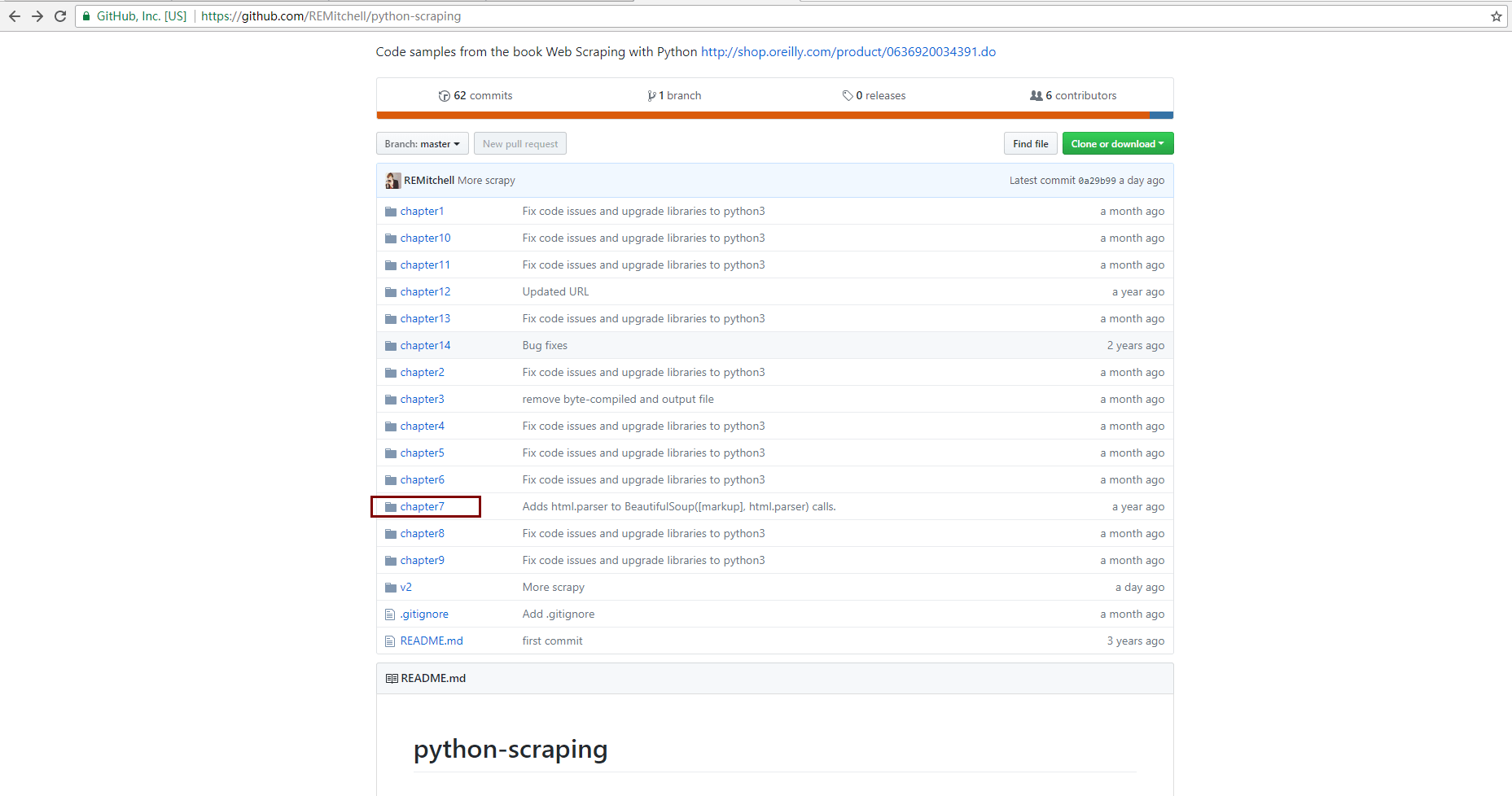 Вы можете увидеть следующий скриншот в своей книге и URL примера кода, который я пометил синим прямоугольником:
Вы можете увидеть следующий скриншот в своей книге и URL примера кода, который я пометил синим прямоугольником: 
Пример кода в 2-clean2grams.py:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
from collections import OrderedDict
def cleanInput(input):
input = re.sub('\n+', " ", input)
input = re.sub('\[[0-9]*\]', "", input)
input = re.sub(' +', " ", input)
input = bytes(input, "UTF-8")
input = input.decode("ascii", "ignore")
cleanInput = []
input = input.split(' ')
for item in input:
item = item.strip(string.punctuation)
if len(item) > 1 or (item.lower() == 'a' or item.lower() == 'i'):
cleanInput.append(item)
return cleanInput
def getNgrams(input, n):
input = cleanInput(input)
output = dict()
for i in range(len(input)-n+1):
newNGram = " ".join(input[i:i+n])
if newNGram in output:
output[newNGram] += 1
else:
output[newNGram] = 1
return output
html = urlopen("http://en.wikipedia.org/wiki/Python_(programming_language)")
bsObj = BeautifulSoup(html, "html.parser")
content = bsObj.find("div", {"id":"mw-content-text"}).get_text()
#ngrams = getNgrams(content, 2)
#print(ngrams)
#print("2-grams count is: "+str(len(ngrams)))
ngrams = getNgrams(content, 2)
ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True))
print(ngrams)
В этом примере кода вы можете получить такой результат:
[('Python Software', 37), ('Software Foundation', 37), ...
Если вы хотите, чтобы ваш результат, как:
[("['Python', 'Software']", 37), ("['Software', 'Foundation']", 37), ...
Вам просто нужно сделать небольшую модификацию следующим образом: