Чувствительная к затратам функция потерь в Tensorflow
Я занимаюсь исследованием чувствительной к стоимости нейронной сети на основе Tensorflow. Но из-за статической структуры графа Tensorflow. Некоторая структура NN не могла быть реализована мной.
Моя функция потерь (стоимость), матрица затрат и прогресс вычислений описаны ниже, и моя цель - вычислить общую стоимость и затем оптимизировать NN:
Приблизительно вычислительный прогресс: 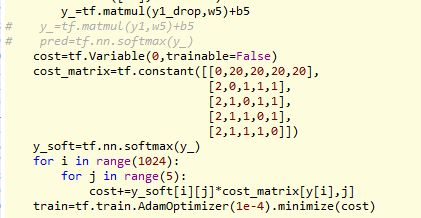
-
y_является последним выходом полного подключения CNN, который имеет форму(1024,5) -
yТензор, который имеет форму (1024) и указывает основную истинуx[i] -
y_soft[i] [j]указывает на вероятностьx[i]быть классомj
Как я могу реализовать это в Tensorflow?
1 ответ
cost_matrix:
[[0,1,100],
[1,0,1],
[1,20,0]]
этикетка:
[1,2]
у *:
[[0,1,0],
[0,0,1]]
у (прогноз):
[[0.2,0.3,0.5],
[0.1,0.2,0.7]]
этикетки,cost_matrix->cost_embedding:
[[1,0,1],
[1,20,0]]
Очевидно, что 0,3 в [0,2,0,3,0,5] относится к правомерной вероятности [0,1,0], поэтому оно не должно приводить к потере.
0,7 в [0,1,0,2,0,7] то же самое. Другими словами, pos со значением 1 в y * не соответствует потере.
Итак, у меня (1-й *):
[[1,0,1],
[1,1,0]]
Тогда энтропия - это цель * log (прогноз) + (1-цель) * log (1-прогноз), а значение 0 в y *, следует использовать (1-цель) * log (1-прогноз), поэтому я использую (1-предсказание) сказал (1-й)
1-й:
[[0.8,*0.7*,0.5],
[0.9,0.8,*0.3*]]
(курсив num бесполезен)
таможенная потеря
[[1,0,1], [1,20,0]] * log([[0.8,0.7,0.5],[0.9,0.8,0.3]]) *
[[1,0,1],[1,1,0]]
и вы можете увидеть (1-й *) можно сюда
поэтому потеря составляет -tf.reduce_mean(cost_embedding*log(1-y)), чтобы сделать ее применимой, должно быть:
-tf.reduce_mean(cost_embedding*log(tf.clip((1-y),1e-10)))
демо ниже
import tensorflow as tf
import numpy as np
hidden_units = 50
num_class = 3
class Model():
def __init__(self,name_scope,is_custom):
self.name_scope = name_scope
self.is_custom = is_custom
self.input_x = tf.placeholder(tf.float32,[None,hidden_units])
self.input_y = tf.placeholder(tf.int32,[None])
self.instantiate_weights()
self.logits = self.inference()
self.predictions = tf.argmax(self.logits,axis=1)
self.losses,self.train_op = self.opitmizer()
def instantiate_weights(self):
with tf.variable_scope(self.name_scope + 'FC'):
self.W = tf.get_variable('W',[hidden_units,num_class])
self.b = tf.get_variable('b',[num_class])
self.cost_matrix = tf.constant(
np.array([[0,1,100],[1,0,100],[20,5,0]]),
dtype = tf.float32
)
def inference(self):
return tf.matmul(self.input_x,self.W) + self.b
def opitmizer(self):
if not self.is_custom:
loss = tf.nn.sparse_softmax_cross_entropy_with_logits\
(labels=self.input_y,logits=self.logits)
else:
batch_cost_matrix = tf.nn.embedding_lookup(
self.cost_matrix,self.input_y
)
loss = - tf.log(1 - tf.nn.softmax(self.logits))\
* batch_cost_matrix
train_op = tf.train.AdamOptimizer().minimize(loss)
return loss,train_op
import random
batch_size = 128
norm_model = Model('norm',False)
custom_model = Model('cost',True)
split_point = int(0.9 * dataset_size)
train_set = datasets[:split_point]
test_set = datasets[split_point:]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(100):
batch_index = random.sample(range(split_point),batch_size)
train_batch = train_set[batch_index]
train_labels = lables[batch_index]
_,eval_predict,eval_loss = sess.run([norm_model.train_op,
norm_model.predictions,norm_model.losses],
feed_dict={
norm_model.input_x:train_batch,
norm_model.input_y:train_labels
})
_,eval_predict1,eval_loss1 = sess.run([custom_model.train_op,
custom_model.predictions,custom_model.losses],
feed_dict={
custom_model.input_x:train_batch,
custom_model.input_y:train_labels
})
# print 'norm',eval_predict,'\ncustom',eval_predict1
print np.sum(((eval_predict == train_labels)==True).astype(np.int)),\
np.sum(((eval_predict1 == train_labels)==True).astype(np.int))
if i%10 == 0:
print 'norm_test',sess.run(norm_model.predictions,
feed_dict={
norm_model.input_x:test_set,
norm_model.input_y:lables[split_point:]
})
print 'custom_test',sess.run(custom_model.predictions,
feed_dict={
custom_model.input_x:test_set,
custom_model.input_y:lables[split_point:]
})