Работа с данными, которые больше, чем физическая память в R, используя bigmemory?
Я разрабатываю пакет R под названием biglasso, который подходит для моделей лассо в R для массивных наборов данных с использованием методов отображения памяти, реализованных в библиотеке C++ bigmemory. В частности, для очень большого набора данных (скажем, 10 ГБ) поддерживается файл big.matrix сначала создается с отображенными в память файлами, хранящимися на диске. Затем алгоритм подбора модели обращается к big.matrix через MatrixAccessor, определенный в библиотеке C++ для получения данных для вычислений. Я предполагаю, что метод отображения памяти позволяет работать с данными, которые больше, чем доступная оперативная память, как упоминалось в статье большой памяти.
Для моего пакета все отлично работает в этот момент, если размер данных не превышает доступную оперативную память. Тем не менее, код работает как всегда, когда данные больше, чем ОЗУ, без жалоб, без ошибок, без остановки. На Mac я проверил top Команда и заметили, что статус этой работы продолжал переключаться между "спящим" и "бегущим", я не уверен, что это значит или это указывает на что-то происходящее.
[РЕДАКТИРОВАТЬ:]
Под "невозможно завершить", "запустить навсегда" я имею в виду: работа с 18 ГБ данных с 16 ГБ ОЗУ не может быть завершена в течение более 1,5 часов, но это может быть сделано в течение 5 минут, если с 32 ГБ ОЗУ.
[Конец редактирования]
Вопросы:
(1) Я в основном понимаю, что при отображении памяти используется виртуальная память, поэтому она может обрабатывать данные, превышающие объем оперативной памяти. Но сколько памяти нужно для работы с объектами, превышающими объем оперативной памяти? Есть ли верхняя граница? Или это определяется размером виртуальной памяти? Поскольку виртуальная память бесконечна (ограничена жестким диском), будет ли это означать, что подход отображения памяти может обрабатывать данные, значительно превышающие объем физической ОЗУ?
(2) Можно ли отдельно измерить память, используемую в физической памяти, и виртуальную память?
(3) Есть что-то, что я делаю неправильно? Каковы возможные причины моих проблем здесь?
Очень ценю любые отзывы! Заранее спасибо.
Ниже приведены некоторые подробности моих экспериментов на Mac и Windows и связанные с ними вопросы.
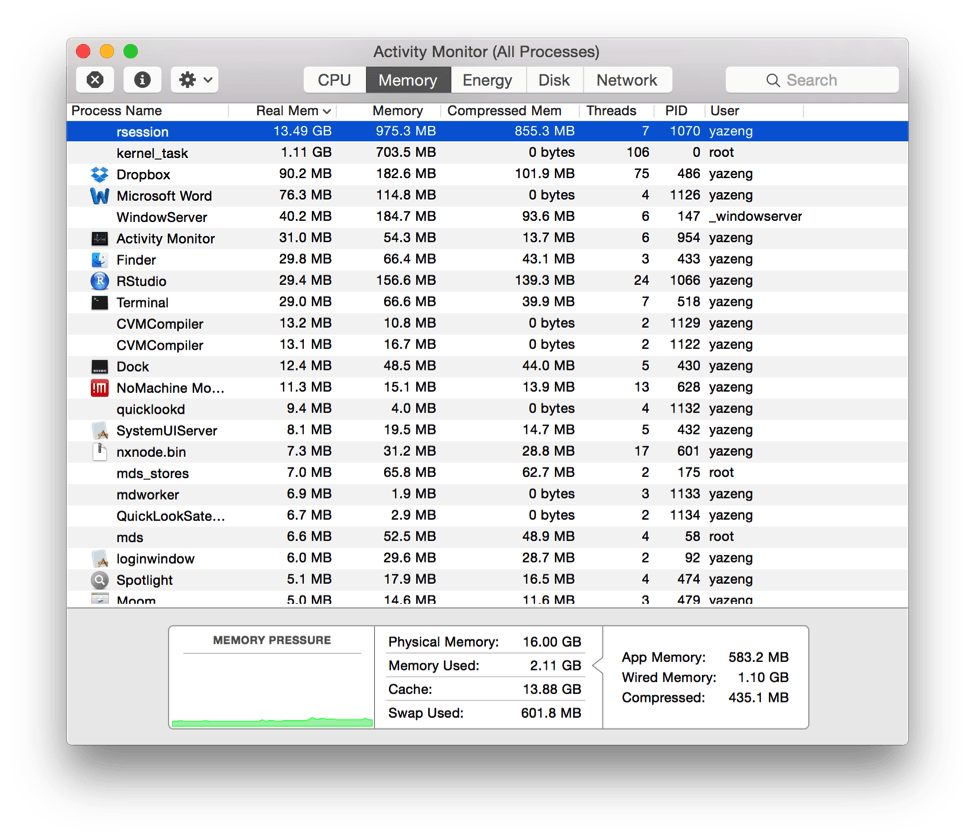
- В Mac OS: физическая память: 16 ГБ; Данные тестирования: 18 ГБ. Вот скриншот использования памяти. Код не может закончиться.
[РЕДАКТИРОВАТЬ 2]
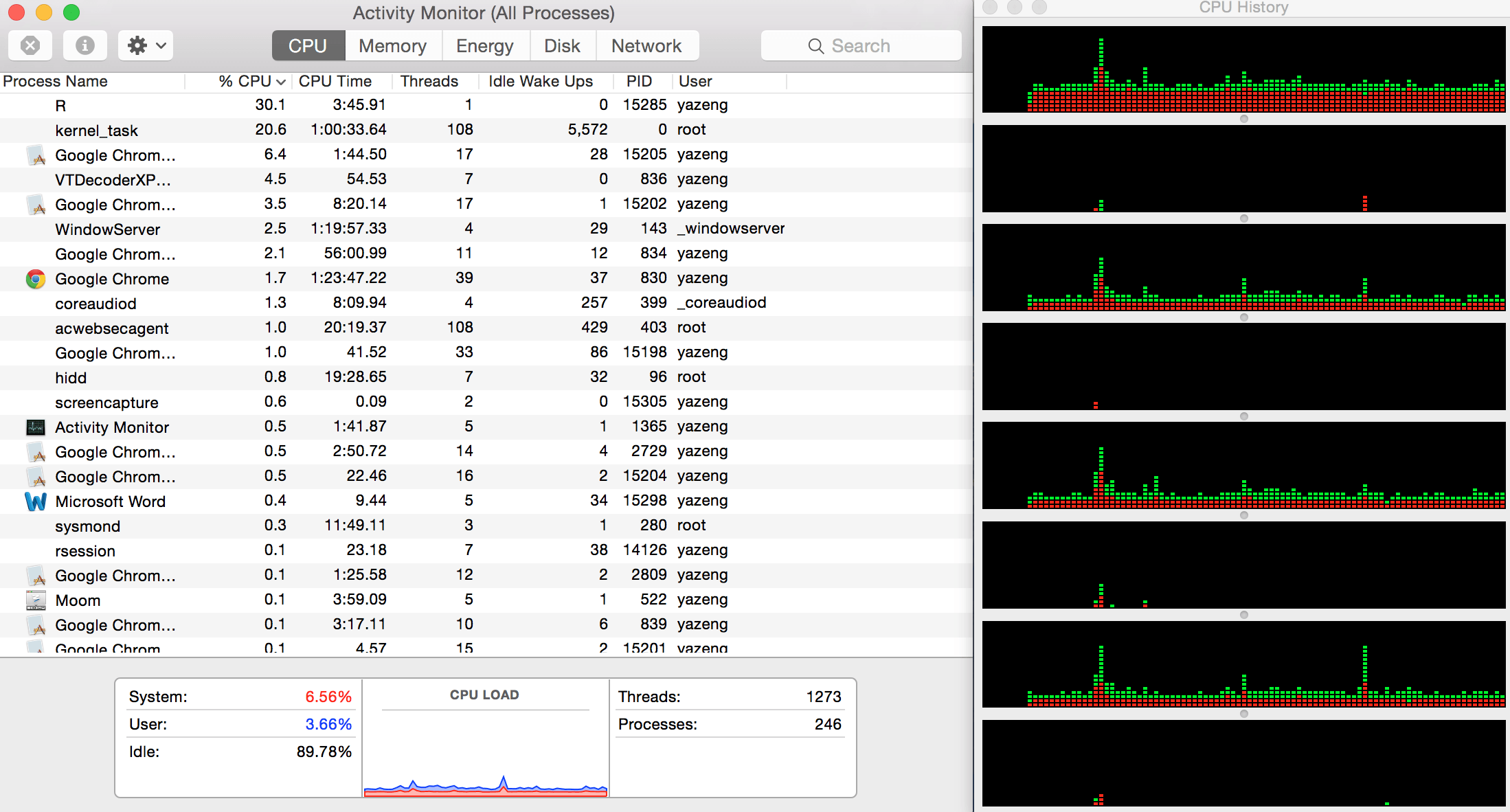
Я приложил использование процессора и историю здесь. Просто используйте одно ядро для вычисления R. Странно, что система использует 6% процессорного времени, а пользователь использует только 3%. А из окна истории процессора есть много красных областей.
Вопрос: что это говорит? Теперь я подозреваю, что это кэш процессора заполнен. Это правильно? Если так, как я мог решить эту проблему?
[КОНЕЦ РЕДАКТИРОВАНИЯ 2]
Вопросы:
(4) Как я понимаю, в столбце "память" указана память, используемая в физической памяти, а в столбце "реальная память" - общее использование памяти, как указано здесь. Это верно? Используемая память всегда показывает ~ 2 ГБ, поэтому я не понимаю, почему так много памяти в ОЗУ не используется.
(5) Незначительный вопрос. Как я заметил, кажется, что "используемая память" + "Кэш" всегда должен быть меньше, чем "Физическая память" (в нижней средней части). Это правильно?
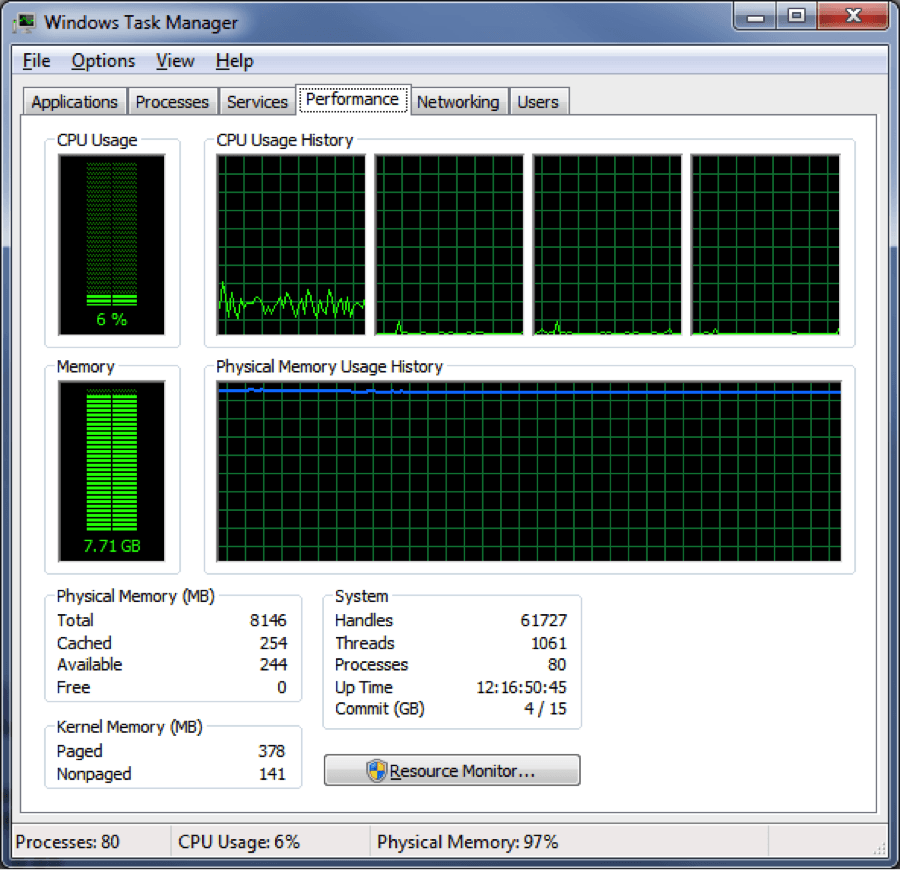
- На Windows-машине: физическая память: 8 ГБ; Данные тестирования: 9 ГБ. Я заметил, что, когда моя работа началась, использование памяти продолжало увеличиваться, пока не достигло предела. Работа не может закончиться также. Я также проверил функции в пакете biganalytics (также используя bigmemory) и обнаружил, что память тоже взрывается.
2 ответа
"Не могу закончить" здесь неоднозначно. Возможно, ваши вычисления завершатся, если вы будете ждать достаточно долго. Когда вы работаете с виртуальной памятью, вы размещаете ее на диске и вне его, что в тысячи-миллионы раз медленнее, чем хранение в оперативной памяти. Замедление, которое вы увидите, зависит от того, как ваш алгоритм обращается к памяти. Если ваш алгоритм посещает каждую страницу только один раз в фиксированном порядке, это не займет много времени. Если ваш алгоритм перескочил по всей структуре данных O(n^2) раз, подкачка страниц замедлит вас настолько, что будет непрактично завершить.
В Windows может быть полезно проверить TaskManager -> Performance-> Resourcemonitor -> Disk disk, чтобы увидеть, сколько данных записывается на диск по идентификатору вашего процесса. Это может дать представление о том, сколько данных поступает в виртуальную память из ОЗУ, если скорость записи становится узким местом и т. Д.