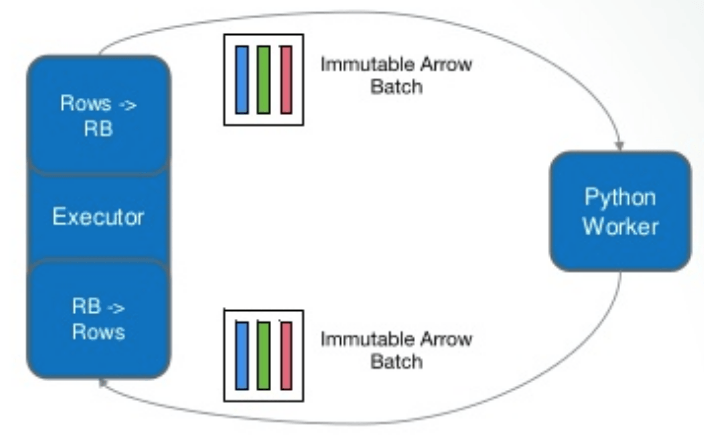
Доступ Spark Java Executor к Arrow Record Batch из Python Worker в PySpark?
Каким образом код исполнителя Java Spark, например работника раздела, может использовать Arrow для доступа к пакетам записей Arrow после их обработки работником Python в PySpark? То есть на сопутствующей диаграмме мы хотели бы получить прямой доступ к "возвращенному" пакету Arrow из Executor вместо доступа к строкам из преобразования пакета.