Комплексное преобразование тяги 3 векторов разных размеров
Здравствуйте, у меня есть этот цикл в C+, и я пытался преобразовать его в тяги, но без получения тех же результатов... Есть идеи? благодарю вас
Код C++
for (i=0;i<n;i++)
for (j=0;j<n;j++)
values[i]=values[i]+(binv[i*n+j]*d[j]);
Код тяги
thrust::fill(values.begin(), values.end(), 0);
thrust::transform(make_zip_iterator(make_tuple(
thrust::make_permutation_iterator(values.begin(), thrust::make_transform_iterator(thrust::make_counting_iterator(0), IndexDivFunctor(n))),
binv.begin(),
thrust::make_permutation_iterator(d.begin(), thrust::make_transform_iterator(thrust::make_counting_iterator(0), IndexModFunctor(n))))),
make_zip_iterator(make_tuple(
thrust::make_permutation_iterator(values.begin(), thrust::make_transform_iterator(thrust::make_counting_iterator(0), IndexDivFunctor(n))) + n,
binv.end(),
thrust::make_permutation_iterator(d.begin(), thrust::make_transform_iterator(thrust::make_counting_iterator(0), IndexModFunctor(n))) + n)),
thrust::make_permutation_iterator(values.begin(), thrust::make_transform_iterator(thrust::make_counting_iterator(0), IndexDivFunctor(n))),
function1()
);
Тяговые функции
struct IndexDivFunctor: thrust::unary_function<int, int>
{
int n;
IndexDivFunctor(int n_) : n(n_) {}
__host__ __device__
int operator()(int idx)
{
return idx / n;
}
};
struct IndexModFunctor: thrust::unary_function<int, int>
{
int n;
IndexModFunctor(int n_) : n(n_) {}
__host__ __device__
int operator()(int idx)
{
return idx % n;
}
};
struct function1
{
template <typename Tuple>
__host__ __device__
double operator()(Tuple v)
{
return thrust::get<0>(v) + thrust::get<1>(v) * thrust::get<2>(v);
}
};
2 ответа
Для начала несколько общих комментариев. Ваша петля
for (i=0;i<n;i++)
for (j=0;j<n;j++)
v[i]=v[i]+(B[i*n+j]*d[j]);
является эквивалентом стандартной операции gemv BLAS
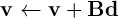
где матрица хранится в главном порядке строк. Оптимальным способом сделать это на устройстве будет использование CUBLAS, а не что-то построенное из примитивов тяги.
Сказав это, абсолютно невозможно, чтобы код направления, который вы разместили, когда-либо делал то, что делает ваш последовательный код. Ошибки, которые вы видите, не являются результатом ассоциативности с плавающей точкой. В корне thrust::transform применяет функтор, предоставленный для каждого элемента итератора ввода, и сохраняет результат в итераторе вывода. Чтобы получить тот же результат, что и опубликованный цикл, thrust::transform Для вызова необходимо выполнить (n*n) операции с функтором fmad, который вы разместили. Ясно, что это не так. Кроме того, нет никаких гарантий, что thrust::transform будет выполнять операцию суммирования / сокращения таким образом, который будет безопасен для гонок памяти.
Правильное решение, вероятно, будет что-то вроде:
- Используйте thrust::transform для вычисления (n*n) произведений элементов B и d
- Используйте thrust::redu_by_key, чтобы свести продукты к частичным суммам, получая Bd
- Используйте thrust::transform, чтобы добавить полученный матрично-векторный продукт к v, чтобы получить конечный результат.
В коде сначала определите функтор следующим образом:
struct functor
{
template <typename Tuple>
__host__ __device__
double operator()(Tuple v)
{
return thrust::get<0>(v) * thrust::get<1>(v);
}
};
Затем выполните следующие действия для вычисления умножения матрицы на вектор.
typedef thrust::device_vector<int> iVec;
typedef thrust::device_vector<double> dVec;
typedef thrust::counting_iterator<int> countIt;
typedef thrust::transform_iterator<IndexDivFunctor, countIt> columnIt;
typedef thrust::transform_iterator<IndexModFunctor, countIt> rowIt;
// Assuming the following allocations on the device
dVec B(n*n), v(n), d(n);
// transformation iterators mapping to vector rows and columns
columnIt cv_begin = thrust::make_transform_iterator(thrust::make_counting_iterator(0), IndexDivFunctor(n));
columnIt cv_end = cv_begin + (n*n);
rowIt rv_begin = thrust::make_transform_iterator(thrust::make_counting_iterator(0), IndexModFunctor(n));
rowIt rv_end = rv_begin + (n*n);
dVec temp(n*n);
thrust::transform(make_zip_iterator(
make_tuple(
B.begin(),
thrust::make_permutation_iterator(d.begin(),rv_begin) ) ),
make_zip_iterator(
make_tuple(
B.end(),
thrust::make_permutation_iterator(d.end(),rv_end) ) ),
temp.begin(),
functor());
iVec outkey(n);
dVec Bd(n);
thrust::reduce_by_key(cv_begin, cv_end, temp.begin(), outkey.begin(), Bd.begin());
thrust::transform(v.begin(), v.end(), Bd.begin(), v.begin(), thrust::plus<double>());
Конечно, это ужасно неэффективный способ вычисления по сравнению с использованием специально разработанного кода умножения матрицы на вектор, такого как dgemv из CUBLAS.
Насколько ваши результаты отличаются? Это совершенно другой ответ или отличается только последними цифрами? Цикл выполняется только один раз или это какой-то итерационный процесс?
Операции с плавающей запятой, особенно те, которые многократно суммируют или умножают определенные значения, не являются ассоциативными из-за проблем точности. Более того, если вы используете быструю математическую оптимизацию, операции могут не соответствовать стандарту IEEE.
Для начала ознакомьтесь с разделом Википедии о числах с плавающей точкой: http://en.wikipedia.org/wiki/Floating_point