Источник событий без CQRS
Я знаю это CQRS может быть реализовано с или без event sourcing, но работает ли другая сторона? Есть ли event sourcing без CQRS имеет смысл? Если так, как это должно быть реализовано?
5 ответов
Да, это так.
По сути, вся идея событийного источника заключается в том, чтобы просто сохранить изменения, которые привели к текущему состоянию, вместо сохранения текущего состояния. Таким образом, благодаря использованию источников событий вы автоматически получаете историю и можете проводить анализ временных рядов ваших данных и пытаться извлечь уроки из прошлого.
Используете ли вы CQRS - это совсем другая история: CQRS - это разделение записи в приложении и чтения из него.
Таким же образом вы можете использовать CQRS без источников событий, вы можете использовать источник событий без CQRS. Оба независимы друг от друга, они просто случайно очень хорошо подходят друг другу.
CQRS - это отделение чтения от записи. Для операций записи нужны такие вещи, как блокировка, гарантированный порядок и всегда самое последнее состояние. В классических системах (реляционных базах данных) вы также предоставляете эту гарантию для операций чтения, что оказывает огромное влияние на производительность и большие проблемы с масштабируемостью. Вот почему в CQRS вы предоставляете операциям чтения отдельную копию данных, которая оптимизирована для быстрого чтения, например, она денормализована и помещена в более эффективные и быстрые системы (например, кэш памяти), я бы назвал это "представлением чтения [ по системным данным]".
CQRS работает без ES, потому что вы можете создать оптимизированное представление для чтения из традиционного хранилища данных (например, реляционной базы данных).
ES работает без CQRS, но только если количество событий достаточно мало. Потому что вы храните все изменения системы в базе данных, и каждое чтение должно использовать одну и ту же базу данных и перебирать все события, необходимые для выполнения запроса. В конце концов, будет слишком много событий, которые нужно будет прочитать, чтобы ответить, и время, необходимое для ответа, станет слишком длинным.
Имеет ли смысл источник событий без CQRS?
Да, в том смысле, что CQRS и Event Sourcing являются ортогональными проблемами.
Это то, что говорится на банке - у вас есть одна модель, которая управляет историей, которая применяет обновления к этой истории в ответ на команды и строит из этой истории ответы на запросы.
class BankAccount {
final History<Transactions> transactions;
void deposit(Money money) {...}
Money computeInterestAccruedSince(Date lastReview) { ... }
}
Я еще не видел ситуацию, когда вы используете ES без CQRS, потому что это будет иметь место только в том случае, если вам не нужны какие-либо возможности запросов / анализа для более чем 1 объекта. 99% всех случаев это требование;)
Вам определенно понадобится что-то вроде CQRS, если вы хотите выполнять запросы к нескольким объектам, так как вы будете применять другой способ запроса данных, отличающийся от использования источников событий. (если только вы не хотите воспроизводить все события каждый раз, когда вы запрашиваете..) Как вы реализуете часть CQRS, пока не ясно. Он просто описывает чтение и письмо - это две разные проблемы, которые решаются по-разному.
Итак, в общем: нет, это не имеет никакого смысла.
Да, источник событий можно использовать без CQRS (как уже указывалось в существующих ответах), но необходимость реализации разделения записи (событий, журналов и т. д.) от чтения (из проекций, представлений и т. д.) Кажется, это происходит естественным образом при достижении определенного уровня сложности.
Случайно наткнулся на пост , и хотя речь идет о распределенных системах, управляемых событиями , можно легко найти параллели между концепциями, описанными в тексте, и CQRS. + поиск событий . Это длинная и насыщенная статья, но ее стоит прочитать.
Процитируем самое актуальное из раздела « Место журнала в архитектуре системы »:
Вот как это работает. Система разделена на две логические части: журнал и уровень обслуживания. В журнале фиксируются изменения состояния в последовательном порядке. Обслуживающие узлы хранят любой индекс, необходимый для обслуживания запросов (например, хранилище значений ключа может иметь что-то вроде btree или sstable, а поисковая система будет иметь инвертированный индекс).
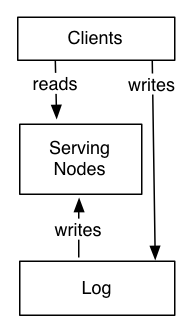

Актуально только косвенно, но после прочтения статьи The Log: Что каждый инженер-программист должен знать об объединяющей абстракции данных в реальном времениThe Log я сразу же начал исследовать, как соединить точки между описываемыми в ней концепциями и источниками событий CQRS + — и, следовательно, почему (почти) никто не рекомендует Kafka в качестве хранилища событий . На мой взгляд, этот ответ является лучшим, и введенная там терминология кажется недооцененной (т. е. «последующая обработка событий» и «источник истины, управляемый приложением»).