Преобразовать список фреймов данных в один фрейм данных
У меня есть код, который в одном месте заканчивается списком фреймов данных, которые я действительно хочу преобразовать в один большой фрейм данных.
Я получил несколько указаний из предыдущего вопроса, который пытался сделать что-то похожее, но более сложное.
Вот пример того, с чего я начинаю (это сильно упрощено для иллюстрации):
listOfDataFrames <- vector(mode = "list", length = 100)
for (i in 1:100) {
listOfDataFrames[[i]] <- data.frame(a=sample(letters, 500, rep=T),
b=rnorm(500), c=rnorm(500))
}
Я в настоящее время использую это:
df <- do.call("rbind", listOfDataFrames)
10 ответов
Еще один вариант - использовать функцию plyr:
df <- ldply(listOfDataFrames, data.frame)
Это немного медленнее, чем оригинал:
> system.time({ df <- do.call("rbind", listOfDataFrames) })
user system elapsed
0.25 0.00 0.25
> system.time({ df2 <- ldply(listOfDataFrames, data.frame) })
user system elapsed
0.30 0.00 0.29
> identical(df, df2)
[1] TRUE
Я думаю, что с помощью do.call("rbind", ...) это будет самый быстрый подход, который вы найдете, если только вы не можете сделать что-то вроде (а) использовать матрицы вместо data.frames и (б) предварительно выделить конечную матрицу и присвоить ей, а не увеличивать ее.
Изменить 1:
Основываясь на комментарии Хэдли, вот последняя версия rbind.fill от CRAN:
> system.time({ df3 <- rbind.fill(listOfDataFrames) })
user system elapsed
0.24 0.00 0.23
> identical(df, df3)
[1] TRUE
Это проще, чем rbind, и незначительно быстрее (эти временные интервалы сохраняются в течение нескольких прогонов). И насколько я понимаю, версия plyr на GitHub еще быстрее, чем это.
Используйте bind_rows() из пакета dplyr:
bind_rows(list_of_dataframes, .id = "column_label")
В целях полноты я думал, что ответы на этот вопрос требуют обновления. "Я думаю, что с помощью do.call("rbind", ...) это будет самый быстрый подход, который вы найдете..."Это, вероятно, было верно для мая 2010 года и некоторое время спустя, но примерно в сентябре 2011 года появилась новая функция rbindlist был введен в data.table версия пакета 1.8.2, с замечанием, что "Это делает так же, как do.call("rbind",l), но гораздо быстрее ". Насколько быстрее?
library(rbenchmark)
benchmark(
do.call = do.call("rbind", listOfDataFrames),
plyr_rbind.fill = plyr::rbind.fill(listOfDataFrames),
plyr_ldply = plyr::ldply(listOfDataFrames, data.frame),
data.table_rbindlist = as.data.frame(data.table::rbindlist(listOfDataFrames)),
replications = 100, order = "relative",
columns=c('test','replications', 'elapsed','relative')
)
test replications elapsed relative
4 data.table_rbindlist 100 0.11 1.000
1 do.call 100 9.39 85.364
2 plyr_rbind.fill 100 12.08 109.818
3 plyr_ldply 100 15.14 137.636

Код:
library(microbenchmark)
dflist <- vector(length=10,mode="list")
for(i in 1:100)
{
dflist[[i]] <- data.frame(a=runif(n=260),b=runif(n=260),
c=rep(LETTERS,10),d=rep(LETTERS,10))
}
mb <- microbenchmark(
plyr::rbind.fill(dflist),
dplyr::bind_rows(dflist),
data.table::rbindlist(dflist),
plyr::ldply(dflist,data.frame),
do.call("rbind",dflist),
times=1000)
ggplot2::autoplot(mb)
сессия:
R version 3.3.0 (2016-05-03)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 7 x64 (build 7601) Service Pack 1
> packageVersion("plyr")
[1] ‘1.8.4’
> packageVersion("dplyr")
[1] ‘0.5.0’
> packageVersion("data.table")
[1] ‘1.9.6’
ОБНОВЛЕНИЕ: Rerun 31-Jan-2018. Бежал на одном компьютере. Новые версии пакетов. Добавлено семя для любителей семян.
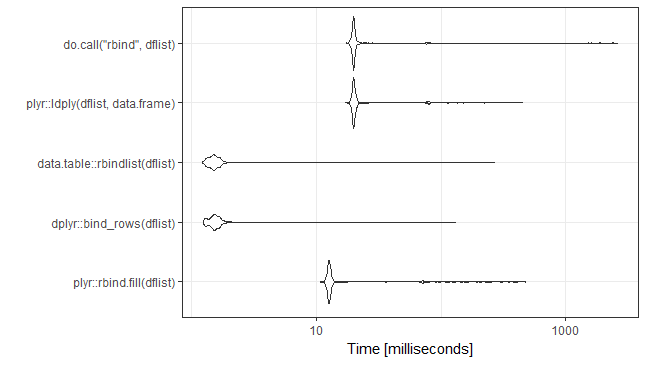
set.seed(21)
library(microbenchmark)
dflist <- vector(length=10,mode="list")
for(i in 1:100)
{
dflist[[i]] <- data.frame(a=runif(n=260),b=runif(n=260),
c=rep(LETTERS,10),d=rep(LETTERS,10))
}
mb <- microbenchmark(
plyr::rbind.fill(dflist),
dplyr::bind_rows(dflist),
data.table::rbindlist(dflist),
plyr::ldply(dflist,data.frame),
do.call("rbind",dflist),
times=1000)
ggplot2::autoplot(mb)+theme_bw()
R version 3.4.0 (2017-04-21)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 7 x64 (build 7601) Service Pack 1
> packageVersion("plyr")
[1] ‘1.8.4’
> packageVersion("dplyr")
[1] ‘0.7.2’
> packageVersion("data.table")
[1] ‘1.10.4’
Существует также bind_rows(x, ...) в dplyr,
> system.time({ df.Base <- do.call("rbind", listOfDataFrames) })
user system elapsed
0.08 0.00 0.07
>
> system.time({ df.dplyr <- as.data.frame(bind_rows(listOfDataFrames)) })
user system elapsed
0.01 0.00 0.02
>
> identical(df.Base, df.dplyr)
[1] TRUE
Вот еще один способ сделать это (просто добавив его в ответы, потому что reduce это очень эффективный функциональный инструмент, который часто упускают из виду в качестве замены для петель. В этом конкретном случае, ни один из них не значительно быстрее, чем do.call)
используя базу R:
df <- Reduce(rbind, listOfDataFrames)
или, используя Tidyverse:
library(tidyverse) # or, library(dplyr); library(purrr)
df <- listOfDataFrames %>% reduce(bind_rows)
Как это сделать в тидиверсе:
df.dplyr.purrr <- listOfDataFrames %>% map_df(bind_rows)
Единственное, что решения с data.table отсутствует столбец идентификатора, чтобы узнать, с какого кадра данных в списке поступают данные.
Что-то вроде этого:
df_id <- data.table::rbindlist(listOfDataFrames, idcol = TRUE)
idcol параметр добавляет столбец (.id) определение источника данных, содержащихся в списке. Результат будет выглядеть примерно так:
.id a b c
1 u -0.05315128 -1.31975849
1 b -1.00404849 1.15257952
1 y 1.17478229 -0.91043925
1 q -1.65488899 0.05846295
1 c -1.43730524 0.95245909
1 b 0.56434313 0.93813197
Обновленный визуальный материал для тех, кто хочет сравнить некоторые из недавних ответов (я хотел сравнить решение purrr и dplyr). В основном я объединил ответы от @TheVTM и @rmf.
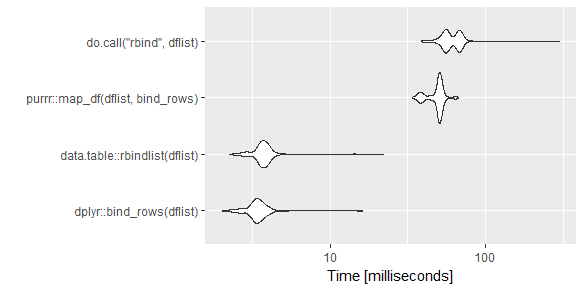
Код:
library(microbenchmark)
library(data.table)
library(tidyverse)
dflist <- vector(length=10,mode="list")
for(i in 1:100)
{
dflist[[i]] <- data.frame(a=runif(n=260),b=runif(n=260),
c=rep(LETTERS,10),d=rep(LETTERS,10))
}
mb <- microbenchmark(
dplyr::bind_rows(dflist),
data.table::rbindlist(dflist),
purrr::map_df(dflist, bind_rows),
do.call("rbind",dflist),
times=500)
ggplot2::autoplot(mb)
Информация о сессии:
sessionInfo()
R version 3.4.1 (2017-06-30)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 7 x64 (build 7601) Service Pack 1
Версии пакета:
> packageVersion("tidyverse")
[1] ‘1.1.1’
> packageVersion("data.table")
[1] ‘1.10.0’
Сpurrr 1.0.0, новая опцияlist_rbind:
library(purrr)
list_rbind(listOfDataFrames, names_to = "column_label")