Лучший язык для извлечения PDF-текста и табулирования его под заголовками строк
То, что я в основном хочу иметь, - это данные PDF под заголовками строк или, чтобы упростить то, что я говорю, я хочу создать базу данных из файла PDF. Каждый PDF состоит из 25-40 страниц в зависимости от количества избирателей.
Страница PDF-файла, о котором я говорю
Я хочу извлечь данные из ящиков (или как вы их говорите) в Access/Excel/SQL, чтобы из каждого ящика
Имя отображается под именем столбца
Отношения отображаются в столбце отношений и т. Д. С другими данными.
Но я понятия не имею, какой язык программирования мне следует изучить, чтобы сделать это. Я пытался найти PDFminer, но я не уверен, сможет ли он выполнить эту задачу или нет.
Если у Вас есть предложения, пожалуйста, дайте мне знать
3 ответа
Гораздо больше гадости, чем я думал, но это работает:
import csv # spreadsheet output
import re # pattern matching
import sys # command-line arguments
import zlib # decompression
# find deflated sections
PARENT = b"FlateDecode"
PARENTLEN = len(PARENT)
START = b"stream\r\n"
STARTLEN = len(START)
END = b"\r\nendstream"
ENDLEN = len(END)
# find output text in PostScript Tj and TJ fields
PS_TEXT = re.compile(r"(?<!\\)\((.*?)(?<!\\)\)")
# return desired per-person records
RECORD = re.compile(r"Name : (.*?)Relation : (.*?)Address : (.*?)Age : (\d+)\s+Sex : (\w?)\s+(\d+)", re.DOTALL)
def get_streams(byte_data):
streams = []
start_at = 0
while True:
# find block containing compressed data
p = byte_data.find(PARENT, start_at)
if p == -1:
# no more streams
break
# find start of data
s = byte_data.find(START, p + PARENTLEN)
if s == -1:
raise ValueError("Found parent at {} bytes with no start".format(p))
# find end of data
e = byte_data.find(END, s + STARTLEN)
if e == -1:
raise ValueError("Found start at {} bytes but no end".format(s))
# unpack compressed data
block = byte_data[s + STARTLEN:e]
unc = zlib.decompress(block)
streams.append(unc)
start_at = e + ENDLEN
return streams
def depostscript(text):
out = []
for line in text.splitlines():
if line.endswith(" Tj"):
# new output line
s = "".join(PS_TEXT.findall(line))
out.append(s)
elif line.endswith(" TJ"):
# continued output line
s = "".join(PS_TEXT.findall(line))
out[-1] += s
return "\n".join(out)
def main(in_pdf, out_csv):
# load .pdf file into memory
with open(in_pdf, "rb") as f:
pdf = f.read()
# get content of all compressed streams
# NB: sample file results in 32 streams
streams = get_streams(pdf)
# we only want the streams which contain text data
# NB: sample file results in 22 text streams
text_streams = []
for stream in streams:
try:
text = stream.decode()
text_streams.append(text)
except UnicodeDecodeError:
pass
# of the remaining blocks, we only want those containing the text '(Relation : '
# NB: sample file results in 4 streams
text_streams = [t for t in text_streams if '(Relation : ' in t]
# consolidate target text
# NB: sample file results in 886 lines of text
text = "\n".join(depostscript(ts) for ts in text_streams)
# pull desired data from text
records = []
for name,relation,address,age,sex,num in RECORD.findall(text):
name = name.strip()
relation = relation.strip()
t = address.strip().splitlines()
code = t[-1]
address = " ".join(t[:-1])
age = int(age)
sex = sex.strip()
num = int(num)
records.append((num, code, name, relation, address, age, sex))
# save results as csv
with open(out_csv, "w", newline='') as outf:
wr = csv.writer(outf)
wr.writerows(records)
if __name__ == "__main__":
if len(sys.argv) < 3:
print("Usage: python {} input.pdf output.csv".format(__name__))
else:
main(sys.argv[1], sys.argv[2])
При запуске в командной строке, как
python myscript.py voters.pdf voters.csv
он производит электронную таблицу.csv, как
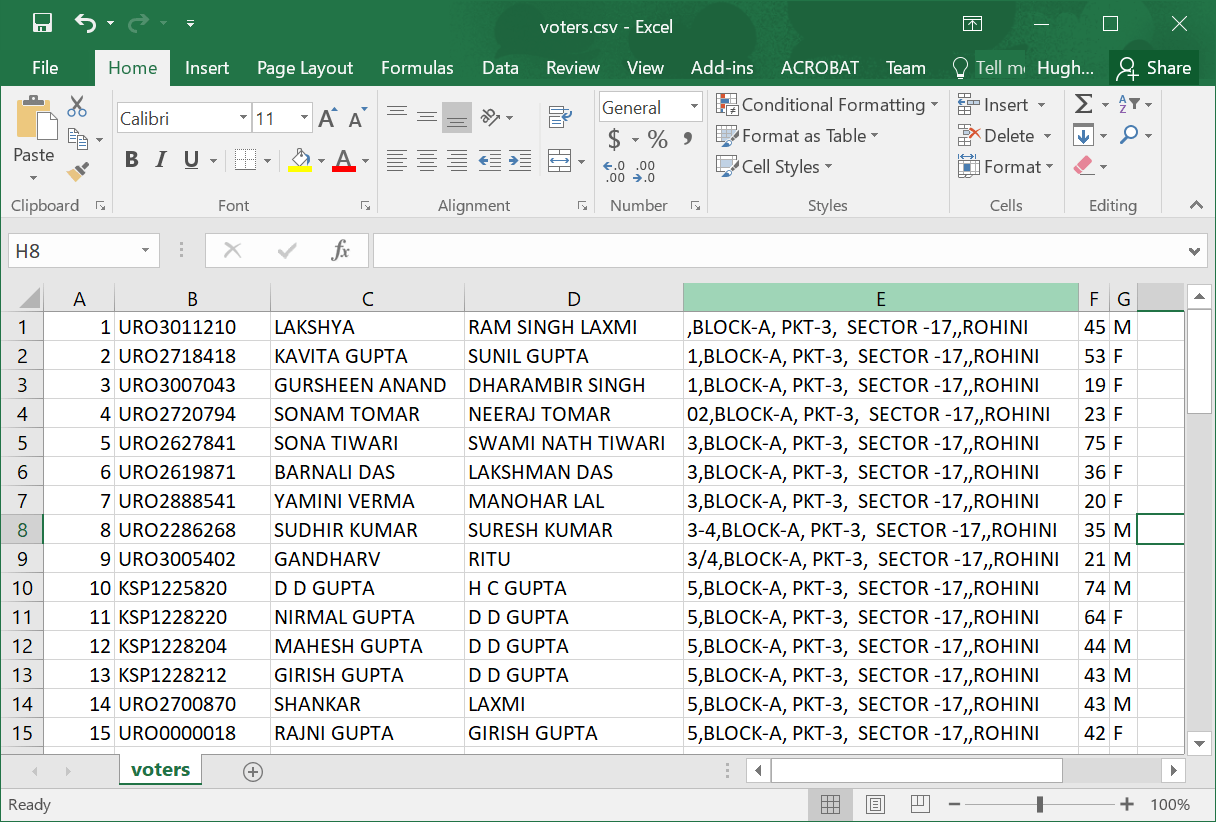
PyMuPDF делает это довольно легко. Я взял страницу, похожую на ту, которую вы хотите обработать, по адресу http://ceodelhi.gov.in/WriteReadData/AssemblyConstituency4/AC13/AC0130022.pdf и применил эту библиотеку следующим образом, чтобы получить HTML, который легко анализируется, скажем, BeautifulSoup или lxml.
>>> import fitz
>>> doc = fitz.open('AC0130022.pdf')
>>> page = doc.loadPage(3)
>>> text = page.getText(output='html')
>>> len(text)
52807
>>> open('page3.html','w').write(text)
52807
Там есть учебник для PyMuPDF по адресу https://pythonhosted.org/PyMuPDF/tutorial.html.
Я сделал работу в колледже, в которой мне нужно было прочитать pdf и извлечь из них некоторые данные. Я использовал PyPDF2 в то время. У меня было много проблем с кодировкой символов при извлечении данных, и у людей, которые использовали Java (я не могу сказать, какую библиотеку они использовали), таких проблем не было.
Я советую вам попробовать использовать Java или другую библиотеку pypdf, отличную от PytoPDF2.
Когда дело доходит до обработки "строковых" данных, я думаю, что Python - лучший вариант.
Еще одна вещь, которую я думаю, вы должны рассмотреть. Если у вас недостаточно опыта программирования, Python - отличный язык для начала, Java немного страшнее.