Мой полу-контролируемый линейный дискриминантный анализ не работает вообще
Я работаю над LDA (линейный дискриминантный анализ), и вы можете обратиться к http://www.ccs.neu.edu/home/vip/teach/MLcourse/5_features_dimensions/lecture_notes/LDA/LDA.pdf.
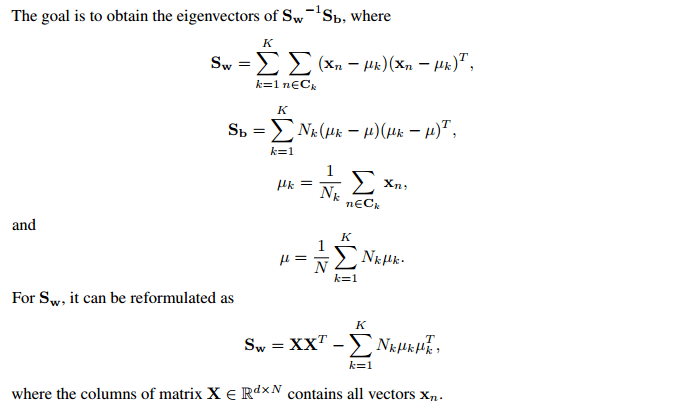
Моя идея о полууправляемом LDA: я могу использовать помеченные данные $X\in R^{d\times N}$, чтобы вычислить все члены в $S_w$ и $S_b$. Теперь у меня также есть немеченые данные $Y\in R^{d\times M}$, и такие данные могут быть дополнительно использованы для оценки ковариационной матрицы $XX^T$ в $S_w$ по $\frac{N}{N+M}(XX^T+YY^T)$, который интуитивно получает лучшую оценку ковариации.
Реализация различных LDA: я также добавляю масштабированную матрицу идентичности к $S_w$ для всех сравниваемых методов, параметр масштабирования должен настраиваться разными методами. Я делю тренировочные данные на две части: помеченные $X\in R^{d\times N}$, немеченые $ Y \ in R ^ {d \ times M} $ с $N/M$ в диапазоне от $0,5$ до $0,05$, Я управляю своим LDA под собственным контролем на трех видах реальных наборов данных.
Как сделать классификацию: в качестве матрицы преобразования $ \ Phi $ используются собственные векторы $S_w^{-1}S_b$, тогда 
Результаты эксперимента: 1) В данных тестирования точность классификации моего полуавтоматического LDA, обученного на данных $X$ и $Y$, всегда немного хуже, чем у стандартного LDA, обученного только на данных $X$. 2) Кроме того, в одних реальных данных оптимальный параметр масштабирования может сильно отличаться для этих двух методов для достижения наилучшей точности классификации.
Не могли бы вы сказать мне причину и дать мне предложение заставить работать мой поднадзорный LDA? Мои коды были проверены. Большое спасибо.