Выберите первую строку в каждой группе GROUP BY?
Как следует из названия, я бы хотел выбрать первую строку каждого набора строк, сгруппированных с GROUP BY,
В частности, если у меня есть purchases таблица, которая выглядит так:
SELECT * FROM purchases;
Мой вывод:
id | клиент | всего ---+----------+------ 1 | Джо | 5 2 | Салли | 3 3 | Джо | 2 4 | Салли | 1
Я хотел бы запросить для id самой крупной покупки (total) сделал каждый customer, Что-то вроде этого:
SELECT FIRST(id), customer, FIRST(total)
FROM purchases
GROUP BY customer
ORDER BY total DESC;
Ожидаемый результат:
ПЕРВЫЙ (id) | клиент | ПЕРВЫЙ (всего)
----------+----------+-------------
1 | Джо | 5
2 | Салли | 3
21 ответ
В Oracle 9.2+ (а не в 8i+, как было изначально указано), SQL Server 2005+, PostgreSQL 8.4+, DB2, Firebird 3.0+, Teradata, Sybase, Vertica:
WITH summary AS (
SELECT p.id,
p.customer,
p.total,
ROW_NUMBER() OVER(PARTITION BY p.customer
ORDER BY p.total DESC) AS rk
FROM PURCHASES p)
SELECT s.*
FROM summary s
WHERE s.rk = 1
Поддерживается любой базой данных:
Но вам нужно добавить логику, чтобы разорвать связи:
SELECT MIN(x.id), -- change to MAX if you want the highest
x.customer,
x.total
FROM PURCHASES x
JOIN (SELECT p.customer,
MAX(total) AS max_total
FROM PURCHASES p
GROUP BY p.customer) y ON y.customer = x.customer
AND y.max_total = x.total
GROUP BY x.customer, x.total
В PostgreSQL это обычно проще и быстрее (подробнее об оптимизации производительности ниже):
SELECT DISTINCT ON (customer)
id, customer, total
FROM purchases
ORDER BY customer, total DESC, id;Или короче (если не так ясно) с порядковыми номерами выходных столбцов:
SELECT DISTINCT ON (2)
id, customer, total
FROM purchases
ORDER BY 2, 3 DESC, 1;
Если total может быть NULL (не повредит в любом случае, но вы захотите соответствовать существующим индексам):
...
ORDER BY customer, total DESC NULLS LAST, id;Основные моменты
DISTINCT ONэто стандартное расширение PostgreSQL (где толькоDISTINCTв целомSELECTсписок определен).Укажите любое количество выражений в
DISTINCT ONпредложение, объединенное значение строки определяет дубликаты. Руководство:Очевидно, что две строки считаются различными, если они отличаются хотя бы одним значением столбца. Нулевые значения считаются равными в этом сравнении.
Жирный акцент мой.
DISTINCT ONможно сочетать сORDER BY, Ведущие выражения должны соответствовать ведущимDISTINCT ONвыражения в том же порядке. Вы можете добавить дополнительные выраженияORDER BYвыбрать конкретный ряд из каждой группы сверстников. я добавилidкак последний элемент для разрыва связей:"Выберите строку с наименьшим
idиз каждой группы, разделяющей самые высокиеtotal".Если
totalможет быть NULL, вы, скорее всего, хотите строку с наибольшим ненулевым значением. добавлятьNULLS LASTвроде продемонстрировано. Подробности:SELECTсписок не ограничен выражениями вDISTINCT ONили жеORDER BYв любом случае. (Не требуется в простом случае выше):Вам не нужно включать любое из выражений в
DISTINCT ONили жеORDER BY,Вы можете включить любое другое выражение в
SELECTсписок. Это способствует замене гораздо более сложных запросов подзапросами и агрегатными / оконными функциями.
Я тестировал с Postgres версии 8.3 - 11. Но эта функция была там по крайней мере начиная с версии 7.1, так что в основном всегда.
Индекс
Идеальным индексом для вышеуказанного запроса будет многостолбцовый индекс, охватывающий все три столбца в соответствующей последовательности и с соответствующим порядком сортировки:
CREATE INDEX purchases_3c_idx ON purchases (customer, total DESC, id);
Может быть слишком специализированным. Но используйте его, если производительность чтения для конкретного запроса имеет решающее значение. Если у вас есть DESC NULLS LAST в запросе используйте то же самое в индексе, чтобы порядок сортировки соответствовал и индекс был применим.
Эффективность / Оптимизация производительности
Взвесьте стоимость и выгоду перед созданием индивидуальных индексов для каждого запроса. Потенциал вышеуказанного индекса во многом зависит от распределения данных.
Индекс используется, потому что он предоставляет предварительно отсортированные данные. В Postgres 9.2 или более поздних версиях запрос также может быть полезен при сканировании только индекса, если индекс меньше базовой таблицы. Индекс должен быть отсканирован полностью.
Для нескольких строк на клиента (высокая мощность в столбце
customer), это очень эффективно. Тем более, если вам все равно нужен отсортированный вывод. Преимущество уменьшается с ростом числа строк на одного клиента.
В идеале тебе хватитwork_memобработать соответствующий шаг сортировки в ОЗУ, а не пролить на диск. Но в целом настройкаwork_memслишком высокий может иметь неблагоприятные последствия. РассматриватьSET LOCALдля исключительно больших запросов. Найдите, сколько вам нужно сEXPLAIN ANALYZE, Упоминание " Диск: " на этапе сортировки указывает на необходимость большего:Для многих строк на клиента (низкая мощность в столбце
customer), свободное сканирование индекса (иначе говоря, "пропустить сканирование") было бы (намного) более эффективным, но это не реализовано до Postgres 11. (Реализация сканирования только по индексу планируется для Postgres 12. См. здесь и здесь.)
Пока есть более быстрые методы запроса, чтобы заменить это. В частности, если у вас есть отдельная таблица с уникальными покупателями, это типичный вариант использования. Но также, если вы этого не сделаете:
эталонный тест
У меня был простой тест, который уже устарел. Я заменил его подробным тестом в этом отдельном ответе.
эталонный тест
Тестирование наиболее интересных кандидатов с Postgres 9.4 и 9.5 с наполовину реалистичной таблицей из 200 тыс. Строк в purchases и 10к отличных customer_id (в среднем 20 строк на клиента).
Для Postgres 9.5 я провел 2-й тест с 86446 различными клиентами. Смотрите ниже (в среднем 2,3 строки на клиента).
Настроить
Главный стол
CREATE TABLE purchases (
id serial
, customer_id int -- REFERENCES customer
, total int -- could be amount of money in Cent
, some_column text -- to make the row bigger, more realistic
);
Я использую serial (Ограничение PK добавлено ниже) и целое число customer_id так как это более типичная установка. Также добавлено some_column наверстать как правило больше столбцов.
Фиктивные данные, PK, index - типичная таблица также содержит несколько мертвых кортежей:
INSERT INTO purchases (customer_id, total, some_column) -- insert 200k rows
SELECT (random() * 10000)::int AS customer_id -- 10k customers
, (random() * random() * 100000)::int AS total
, 'note: ' || repeat('x', (random()^2 * random() * random() * 500)::int)
FROM generate_series(1,200000) g;
ALTER TABLE purchases ADD CONSTRAINT purchases_id_pkey PRIMARY KEY (id);
DELETE FROM purchases WHERE random() > 0.9; -- some dead rows
INSERT INTO purchases (customer_id, total, some_column)
SELECT (random() * 10000)::int AS customer_id -- 10k customers
, (random() * random() * 100000)::int AS total
, 'note: ' || repeat('x', (random()^2 * random() * random() * 500)::int)
FROM generate_series(1,20000) g; -- add 20k to make it ~ 200k
CREATE INDEX purchases_3c_idx ON purchases (customer_id, total DESC, id);
VACUUM ANALYZE purchases;
customer таблица - для лучшего запроса
CREATE TABLE customer AS
SELECT customer_id, 'customer_' || customer_id AS customer
FROM purchases
GROUP BY 1
ORDER BY 1;
ALTER TABLE customer ADD CONSTRAINT customer_customer_id_pkey PRIMARY KEY (customer_id);
VACUUM ANALYZE customer;
Во втором тесте для 9.5 я использовал ту же настройку, но с random() * 100000 чтобы генерировать customer_id чтобы получить только несколько строк в customer_id,
Размеры объекта для стола purchases
Сгенерировано с этим запросом.
what | bytes/ct | bytes_pretty | bytes_per_row
-----------------------------------+----------+--------------+---------------
core_relation_size | 20496384 | 20 MB | 102
visibility_map | 0 | 0 bytes | 0
free_space_map | 24576 | 24 kB | 0
table_size_incl_toast | 20529152 | 20 MB | 102
indexes_size | 10977280 | 10 MB | 54
total_size_incl_toast_and_indexes | 31506432 | 30 MB | 157
live_rows_in_text_representation | 13729802 | 13 MB | 68
------------------------------ | | |
row_count | 200045 | |
live_tuples | 200045 | |
dead_tuples | 19955 | |
Запросы
1. row_number() в CTE ( см. другой ответ)
WITH cte AS (
SELECT id, customer_id, total
, row_number() OVER(PARTITION BY customer_id ORDER BY total DESC) AS rn
FROM purchases
)
SELECT id, customer_id, total
FROM cte
WHERE rn = 1;
2. row_number() в подзапросе (моя оптимизация)
SELECT id, customer_id, total
FROM (
SELECT id, customer_id, total
, row_number() OVER(PARTITION BY customer_id ORDER BY total DESC) AS rn
FROM purchases
) sub
WHERE rn = 1;
3. DISTINCT ON ( см. другой ответ)
SELECT DISTINCT ON (customer_id)
id, customer_id, total
FROM purchases
ORDER BY customer_id, total DESC, id;
4. rCTE с LATERAL подзапрос ( см. здесь)
WITH RECURSIVE cte AS (
( -- parentheses required
SELECT id, customer_id, total
FROM purchases
ORDER BY customer_id, total DESC
LIMIT 1
)
UNION ALL
SELECT u.*
FROM cte c
, LATERAL (
SELECT id, customer_id, total
FROM purchases
WHERE customer_id > c.customer_id -- lateral reference
ORDER BY customer_id, total DESC
LIMIT 1
) u
)
SELECT id, customer_id, total
FROM cte
ORDER BY customer_id;
5. customer стол с LATERAL ( см. здесь)
SELECT l.*
FROM customer c
, LATERAL (
SELECT id, customer_id, total
FROM purchases
WHERE customer_id = c.customer_id -- lateral reference
ORDER BY total DESC
LIMIT 1
) l;
6. array_agg() с ORDER BY ( см. другой ответ)
SELECT (array_agg(id ORDER BY total DESC))[1] AS id
, customer_id
, max(total) AS total
FROM purchases
GROUP BY customer_id;
Результаты
Время выполнения вышеуказанных запросов с EXPLAIN ANALYZE (и все варианты выключены), лучший из 5 трасс.
Все запросы использовали сканирование только по индексу purchases2_3c_idx (среди других шагов). Некоторые из них только для меньшего размера индекса, другие более эффективно.
А. Postgres 9,4 с 200 тыс. Строк и ~ 20 на customer_id
1. 273.274 ms
2. 194.572 ms
3. 111.067 ms
4. 92.922 ms
5. 37.679 ms -- winner
6. 189.495 ms
Б. То же самое с Postgres 9,5
1. 288.006 ms
2. 223.032 ms
3. 107.074 ms
4. 78.032 ms
5. 33.944 ms -- winner
6. 211.540 ms
C. То же, что и B., но с ~ 2,3 строками на customer_id
1. 381.573 ms
2. 311.976 ms
3. 124.074 ms -- winner
4. 710.631 ms
5. 311.976 ms
6. 421.679 ms
Оригинальный (устаревший) тест 2011 года
Я выполнил три теста с PostgreSQL 9.1 для реальной таблицы из 65579 строк и одностолбцовых индексов btree для каждого из трех задействованных столбцов и взял лучшее время выполнения из 5 запусков.
Сравнение первого запроса @OMGPonies (A) к вышесказанному DISTINCT ON решение (B):
Выделите всю таблицу, в этом случае получается 5958 строк.
A: 567.218 ms B: 386.673 msИспользуйте условие
WHERE customer BETWEEN x AND yв результате чего 1000 строк.A: 249.136 ms B: 55.111 msВыберите одного клиента с
WHERE customer = x,A: 0.143 ms B: 0.072 ms
Тот же тест повторяется с индексом, описанным в другом ответе
CREATE INDEX purchases_3c_idx ON purchases (customer, total DESC, id);
1A: 277.953 ms
1B: 193.547 ms
2A: 249.796 ms -- special index not used
2B: 28.679 ms
3A: 0.120 ms
3B: 0.048 ms
Это общая проблема с наибольшим числом групп, которая уже имеет хорошо протестированные и высоко оптимизированные решения. Лично я предпочитаю левое решение Билла Карвина ( оригинальный пост с множеством других решений).
Обратите внимание, что кучу решений этой распространенной проблемы можно найти в одном из самых официальных источников, руководстве по MySQL! См. Примеры распространенных запросов:: Строки, удерживающие групповой максимум определенного столбца.
В Postgres вы можете использовать array_agg как это:
SELECT customer,
(array_agg(id ORDER BY total DESC))[1],
max(total)
FROM purchases
GROUP BY customer
Это даст вам id каждого покупателя крупнейшей покупки.
Некоторые вещи на заметку:
array_aggявляется агрегатной функцией, поэтому она работает сGROUP BY,array_aggПозволяет указать порядок размещения только для себя, чтобы он не ограничивал структуру всего запроса. Существует также синтаксис для сортировки значений NULL, если вам нужно сделать что-то отличное от значения по умолчанию.- Как только мы построим массив, мы берем первый элемент. (Массивы Postgres индексируются 1, а не 0).
- Вы могли бы использовать
array_aggаналогичным образом для вашего третьего выходного столбца, ноmax(total)проще - В отличие от
DISTINCT ON, с помощьюarray_aggпозволяет вам сохранитьGROUP BYВ случае, если вы хотите этого по другим причинам.
Запрос:
SELECT purchases.*
FROM purchases
LEFT JOIN purchases as p
ON
p.customer = purchases.customer
AND
purchases.total < p.total
WHERE p.total IS NULL
КАК ЭТО РАБОТАЕТ! (Я был там)
Мы хотим убедиться, что у нас только самая высокая сумма для каждой покупки.
Некоторые теоретические материалы (пропустите эту часть, если вы хотите понять только запрос)
Пусть Total будет функцией T (customer, id), где она возвращает значение с указанным именем и id. Чтобы доказать, что данный итог (T (customer, id)) является наибольшим, мы должны доказать, что мы хотим доказать либо
- Tx T(customer,id) > T(customer,x) (эта сумма выше, чем все остальные суммы для этого клиента)
ИЛИ ЖЕ
- ¬∃x T(customer, id)
При первом подходе нам понадобятся все записи для этого имени, которое мне не очень нравится.
Второму нужен умный способ сказать, что не может быть рекорда выше этого.
Вернуться к SQL
Если мы оставили присоединяющиеся таблицы по имени и общему количеству меньше объединенной таблицы:
LEFT JOIN purchases as p
ON
p.customer = purchases.customer
AND
purchases.total < p.total
мы удостоверяемся, что все записи, которые имеют другую запись с более высоким общим количеством для того же пользователя, будут присоединены:
purchases.id, purchases.customer, purchases.total, p.id, p.customer, p.total
1 , Tom , 200 , 2 , Tom , 300
2 , Tom , 300
3 , Bob , 400 , 4 , Bob , 500
4 , Bob , 500
5 , Alice , 600 , 6 , Alice , 700
6 , Alice , 700
Это поможет нам отфильтровать наибольшую сумму по каждой покупке без необходимости группировать:
WHERE p.total IS NULL
purchases.id, purchases.name, purchases.total, p.id, p.name, p.total
2 , Tom , 300
4 , Bob , 500
6 , Alice , 700
И это ответ, который нам нужен.
Решение не очень эффективное, как указал Эрвин, из-за присутствия SubQ
select * from purchases p1 where total in
(select max(total) from purchases where p1.customer=customer) order by total desc;
Я использую этот способ (только postgresql): https://wiki.postgresql.org/wiki/First/last_%28aggregate%29
-- Create a function that always returns the first non-NULL item
CREATE OR REPLACE FUNCTION public.first_agg ( anyelement, anyelement )
RETURNS anyelement LANGUAGE sql IMMUTABLE STRICT AS $$
SELECT $1;
$$;
-- And then wrap an aggregate around it
CREATE AGGREGATE public.first (
sfunc = public.first_agg,
basetype = anyelement,
stype = anyelement
);
-- Create a function that always returns the last non-NULL item
CREATE OR REPLACE FUNCTION public.last_agg ( anyelement, anyelement )
RETURNS anyelement LANGUAGE sql IMMUTABLE STRICT AS $$
SELECT $2;
$$;
-- And then wrap an aggregate around it
CREATE AGGREGATE public.last (
sfunc = public.last_agg,
basetype = anyelement,
stype = anyelement
);
Тогда ваш пример должен работать почти так:
SELECT FIRST(id), customer, FIRST(total)
FROM purchases
GROUP BY customer
ORDER BY FIRST(total) DESC;
CAVEAT: игнорирует пустые строки
Редактировать 1 - использовать вместо этого расширение postgres
Теперь я использую этот способ: http://pgxn.org/dist/first_last_agg/
Для установки на Ubuntu 14.04:
apt-get install postgresql-server-dev-9.3 git build-essential -y
git clone git://github.com/wulczer/first_last_agg.git
cd first_last_app
make && sudo make install
psql -c 'create extension first_last_agg'
Это расширение postgres, которое дает вам первую и последнюю функции; по-видимому, быстрее, чем вышеописанным способом.
Редактировать 2 - Порядок и фильтрация
Если вы используете агрегатные функции (подобные этим), вы можете упорядочить результаты без необходимости упорядочивать данные:
http://www.postgresql.org/docs/current/static/sql-expressions.html#SYNTAX-AGGREGATES
Таким образом, эквивалентный пример с упорядочением будет выглядеть примерно так:
SELECT first(id order by id), customer, first(total order by id)
FROM purchases
GROUP BY customer
ORDER BY first(total);
Конечно, вы можете заказывать и фильтровать по своему усмотрению в совокупности; это очень мощный синтаксис.
Использование ARRAY_AGG функция для PostgreSQL, U-SQL, IBM DB2 и Google BigQuery SQL:
SELECT customer, (ARRAY_AGG(id ORDER BY total DESC))[1], MAX(total)
FROM purchases
GROUP BY customer
Очень быстрое решение
SELECT a.*
FROM
purchases a
JOIN (
SELECT customer, min( id ) as id
FROM purchases
GROUP BY customer
) b USING ( id );
и действительно очень быстро, если таблица индексируется по id:
create index purchases_id on purchases (id);
В SQL Server вы можете сделать это:
SELECT *
FROM (
SELECT ROW_NUMBER()
OVER(PARTITION BY customer
ORDER BY total DESC) AS StRank, *
FROM Purchases) n
WHERE StRank = 1
Объяснение: здесь Группировка по выполняется на основе клиента, а затем заказывается по сумме, затем каждой такой группе присваивается серийный номер как StRank, и мы выбираем первого 1 клиента, чей StRank равен 1
В PostgreSQL еще одна возможность - использовать first_value оконная функция в сочетании с SELECT DISTINCT:
select distinct customer_id,
first_value(row(id, total)) over(partition by customer_id order by total desc, id)
from purchases;
Я создал композит (id, total), поэтому оба значения возвращаются одним и тем же агрегатом. Вы, конечно, всегда можете подать заявкуfirst_value() дважды.
Snowflake/Teradata поддерживает QUALIFY пункт, который работает как HAVING для оконных функций:
SELECT id, customer, total
FROM PURCHASES
QUALIFY ROW_NUMBER() OVER(PARTITION BY p.customer ORDER BY p.total DESC) = 1
Вот как мы можем добиться этого с помощью функции Windows:
create table purchases (id int4, customer varchar(10), total integer);
insert into purchases values (1, 'Joe', 5);
insert into purchases values (2, 'Sally', 3);
insert into purchases values (3, 'Joe', 2);
insert into purchases values (4, 'Sally', 1);
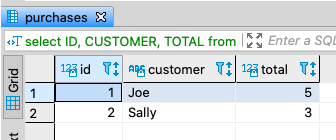
select ID, CUSTOMER, TOTAL from (
select ID, CUSTOMER, TOTAL,
row_number () over (partition by CUSTOMER order by TOTAL desc) RN
from purchases) A where RN = 1;
Так это работает для меня:
SELECT article, dealer, price
FROM shop s1
WHERE price=(SELECT MAX(s2.price)
FROM shop s2
WHERE s1.article = s2.article
GROUP BY s2.article)
ORDER BY article;
Выберите самую высокую цену для каждого товара
Принятое мной решение OMG Ponies "Поддерживается любой базой данных" имеет хорошую скорость из моего теста.
Здесь я предоставляю тот же подход, но более полное и чистое решение для любой базы данных. Рассматриваются связи (предположим, что требуется получить только одну строку для каждого клиента, даже несколько записей для максимальной общей суммы для каждого клиента), и другие поля покупки (например, purchase_payment_id) будут выбраны для реальных совпадающих строк в таблице покупок.
Поддерживается любой базой данных:
select * from purchase
join (
select min(id) as id from purchase
join (
select customer, max(total) as total from purchase
group by customer
) t1 using (customer, total)
group by customer
) t2 using (id)
order by customer
Этот запрос достаточно быстрый, особенно когда в таблице покупок есть составной индекс, такой как (клиент, итог).
Примечание:
t1, t2 - псевдоним подзапроса, который можно удалить в зависимости от базы данных.
Предостережение:
using (...)в настоящее время это предложение не поддерживается в MS-SQL и Oracle db по состоянию на январь 2017 года. Вы должны расширить его, например, доon t2.id = purchase.idи т.д. Синтаксис USING работает в SQLite, MySQL и PostgreSQL.
Если вы хотите выбрать любую (по вашему конкретному условию) строку из набора агрегированных строк.
Если вы хотите использовать другой (
sum/avg) функция агрегации в дополнение кmax/min, Таким образом, вы не можете использовать ключ сDISTINCT ON
Вы можете использовать следующий подзапрос:
SELECT
(
SELECT **id** FROM t2
WHERE id = ANY ( ARRAY_AGG( tf.id ) ) AND amount = MAX( tf.amount )
) id,
name,
MAX(amount) ma,
SUM( ratio )
FROM t2 tf
GROUP BY name
Вы можете заменить amount = MAX( tf.amount ) с любым желаемым условием с одним ограничением: этот подзапрос не должен возвращать более одной строки
Но если вы хотите делать такие вещи, вы, вероятно, ищете оконные функции
Для SQl Server наиболее эффективным способом является:
with
ids as ( --condition for split table into groups
select i from (values (9),(12),(17),(18),(19),(20),(22),(21),(23),(10)) as v(i)
)
,src as (
select * from yourTable where <condition> --use this as filter for other conditions
)
,joined as (
select tops.* from ids
cross apply --it`s like for each rows
(
select top(1) *
from src
where CommodityId = ids.i
) as tops
)
select * from joined
и не забудьте создать кластерный индекс для используемых столбцов
Это может быть легко достигнуто с помощью MAX FUNCTION по итогу и GROUP BY id и customer.
SELECT id, customer, MAX(total) FROM purchases GROUP BY id, customer
ORDER BY total DESC;
Мой подход через оконную функцию dbfiddle:
- Назначать
row_numberв каждой группе:row_number() over (partition by agreement_id, order_id ) as nrow - Взять только первую строку в группе:
filter (where nrow = 1)
with intermediate as (select
*,
row_number() over ( partition by agreement_id, order_id ) as nrow,
(sum( suma ) over ( partition by agreement_id, order_id ))::numeric( 10, 2) as order_suma,
from <your table>)
select
*,
sum( order_suma ) filter (where nrow = 1) over (partition by agreement_id)
from intermediate
вы можете получить первую строку в каждой группе, используя CTE (общее табличное выражение), ниже приведен пример примера.
с cte as (SELECT t1.* FROM table_one t1 INNER JOIN (SELECT id,MAX(date) AS max_dateFROM table1GROUP BY id) t2 ON t1.id = t2.id И t1.max_date= t2.date)
Спасибо