Создание пустого DataFrame Pandas, а затем его заполнение?
Я начинаю с документации по фрейму данных здесь: http://pandas.pydata.org/pandas-docs/stable/dsintro.html
Я хотел бы итеративно заполнять фрейм данных значениями для расчета временных рядов. В общем, я хотел бы инициализировать фрейм данных со столбцами A,B и строками отметок времени, все 0 или все NaN.
Затем я добавил бы начальные значения и перебрал бы эти данные, вычисляя новую строку из предыдущей строки, скажем, row[A][t] = row[A][t-1]+1 или около того.
В настоящее время я использую код, как показано ниже, но я чувствую, что он немного уродлив, и должен быть способ сделать это напрямую с фреймом данных или просто лучше. Примечание: я использую Python 2.7.
import datetime as dt
import pandas as pd
import scipy as s
if __name__ == '__main__':
base = dt.datetime.today().date()
dates = [ base - dt.timedelta(days=x) for x in range(0,10) ]
dates.sort()
valdict = {}
symbols = ['A','B', 'C']
for symb in symbols:
valdict[symb] = pd.Series( s.zeros( len(dates)), dates )
for thedate in dates:
if thedate > dates[0]:
for symb in valdict:
valdict[symb][thedate] = 1+valdict[symb][thedate - dt.timedelta(days=1)]
print valdict
9 ответов
Вот пара предложений:
использование date_rangeдля индекса:
import datetime
import pandas as pd
import numpy as np
todays_date = datetime.datetime.now().date()
index = pd.date_range(todays_date-datetime.timedelta(10), periods=10, freq='D')
columns = ['A','B', 'C']
Примечание: мы могли бы создать пустой DataFrame (сNaNs) просто написав:
df_ = pd.DataFrame(index=index, columns=columns)
df_ = df_.fillna(0) # with 0s rather than NaNs
Чтобы выполнить такой тип вычислений для данных, используйте массив numpy:
data = np.array([np.arange(10)]*3).T
Следовательно, мы можем создать DataFrame:
In [10]: df = pd.DataFrame(data, index=index, columns=columns)
In [11]: df
Out[11]:
A B C
2012-11-29 0 0 0
2012-11-30 1 1 1
2012-12-01 2 2 2
2012-12-02 3 3 3
2012-12-03 4 4 4
2012-12-04 5 5 5
2012-12-05 6 6 6
2012-12-06 7 7 7
2012-12-07 8 8 8
2012-12-08 9 9 9
The Right Way™ для создания DataFrame
TL; DR; (просто прочтите жирный текст)
В большинстве ответов здесь рассказывается, как создать пустой DataFrame и заполнить его, но никто не скажет вам, что это плохо.
Вот мой совет: подождите, пока вы не будете уверены, что у вас есть все данные, с которыми вам нужно работать. Используйте список для сбора данных, а затем инициализируйте DataFrame, когда будете готовы.
data = []
for a, b, c in some_function_that_yields_data():
data.append([a, b, c])
df = pd.DataFrame(data, columns=['A', 'B', 'C'])
Это всегда дешевле, чтобы добавить в список и создать DataFrame на одном дыхании, чем это, чтобы создать пустой DataFrame (или один из NaNs) и дополнения к нему снова и снова. Списки также занимают меньше памяти и представляют собой гораздо более легкую структуру данных для работы, добавления и удаления (при необходимости).
Другое преимущество этого метода - dtypesавтоматически выводятся (вместо того, чтобы назначатьobject всем им).
Последнее преимущество состоит в том, чтоRangeIndexавтоматически создается для ваших данных, поэтому вам не о чем беспокоиться (взгляните на бедныеappend а также loc методы ниже, вы увидите элементы в обоих, которые требуют соответствующей обработки индекса).
То, что вам НЕ следует делать
append или concat внутри петли
Вот самая большая ошибка, которую я видел от новичков:
df = pd.DataFrame(columns=['A', 'B', 'C'])
for a, b, c in some_function_that_yields_data():
df = df.append({'A': i, 'B': b, 'C': c}, ignore_index=True) # yuck
# or similarly,
# df = pd.concat([df, pd.Series({'A': i, 'B': b, 'C': c})], ignore_index=True)
Память перераспределяется для каждого append или concatоперация у вас есть. Соедините это с циклом, и вы получите операцию квадратичной сложности. Из df.appendстраница документа:
Итеративное добавление строк в DataFrame может быть более интенсивным с точки зрения вычислений, чем одиночное объединение. Лучшее решение - добавить эти строки в список, а затем сразу объединить список с исходным DataFrame.
Другая ошибка, связанная с df.appendзаключается в том, что пользователи часто забывают, что добавление не является функцией на месте, поэтому результат должен быть возвращен. Вам также нужно беспокоиться о типах dtypes:
df = pd.DataFrame(columns=['A', 'B', 'C'])
df = df.append({'A': 1, 'B': 12.3, 'C': 'xyz'}, ignore_index=True)
df.dtypes
A object # yuck!
B float64
C object
dtype: object
Работа со столбцами объектов никогда не бывает хорошей, потому что панды не могут векторизовать операции с этими столбцами. Вам нужно будет сделать это, чтобы исправить это:
df.infer_objects().dtypes
A int64
B float64
C object
dtype: object
loc внутри петли
Я также видел loc используется для добавления в DataFrame, который был создан пустым:
df = pd.DataFrame(columns=['A', 'B', 'C'])
for a, b, c in some_function_that_yields_data():
df.loc[len(df)] = [a, b, c]
Как и раньше, вы не выделяли заранее необходимый объем памяти каждый раз, поэтому объем памяти увеличивается каждый раз, когда вы создаете новую строку. Это так же плохо, какappend, и даже более некрасиво.
Пустой DataFrame из NaN
А затем создается DataFrame из NaN и все связанные с ним оговорки.
df = pd.DataFrame(columns=['A', 'B', 'C'], index=range(5))
df
A B C
0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 NaN NaN NaN
4 NaN NaN NaN
Он создает DataFrame из столбцов объекта, как и другие.
df.dtypes
A object # you DON'T want this
B object
C object
dtype: object
Добавление по-прежнему имеет все проблемы, как и методы выше.
for i, (a, b, c) in enumerate(some_function_that_yields_data()):
df.iloc[i] = [a, b, c]
Доказательство в пудинге
Выбор времени для этих методов - самый быстрый способ увидеть, насколько они различаются по объему памяти и полезности.
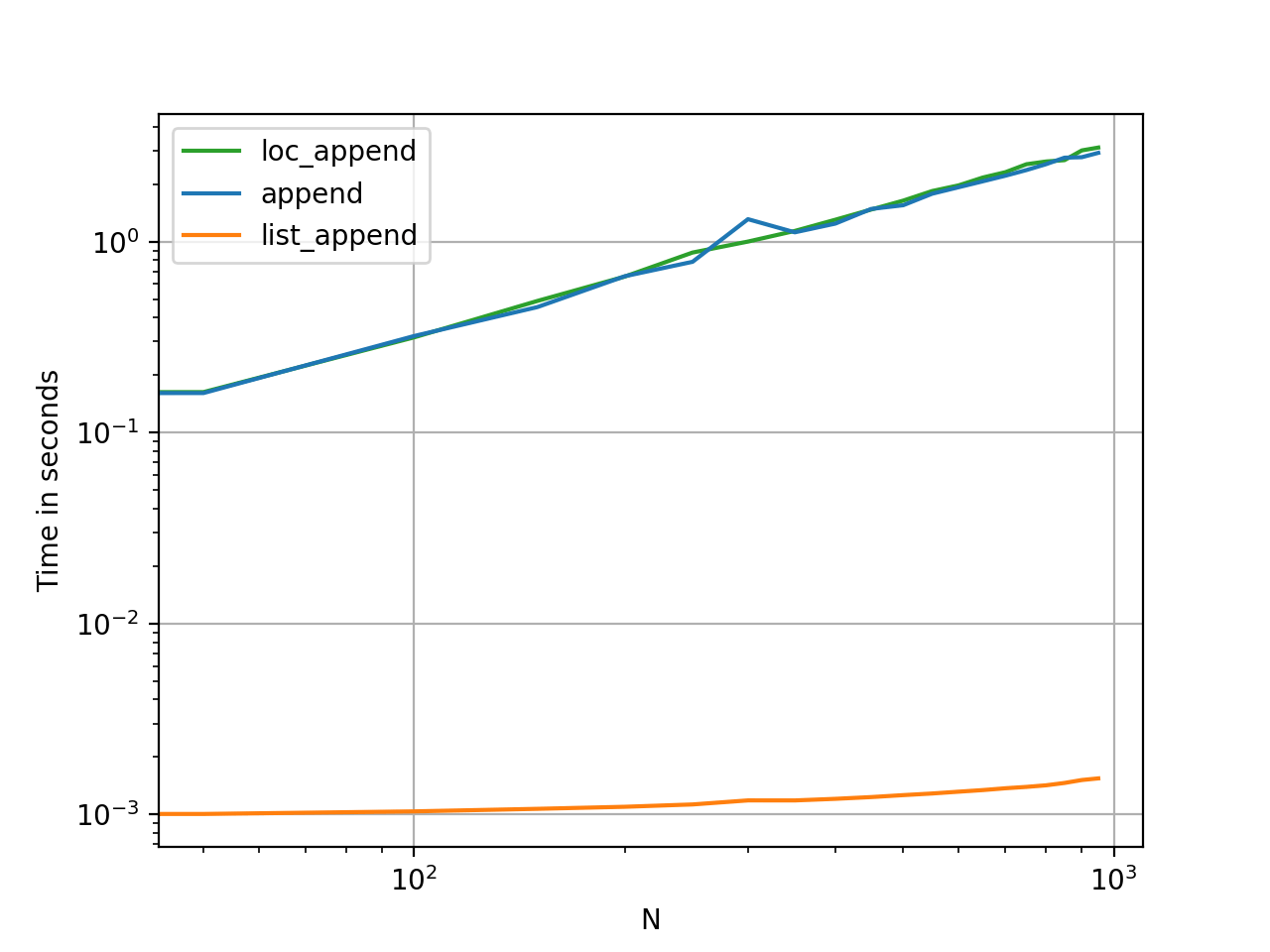
Если вы просто хотите создать пустой фрейм данных и заполнить его несколькими входящими фреймами позже, попробуйте это:
В этом примере я использую этот документ pandas для создания нового фрейма данных, а затем использую append для записи в newDF с данными из oldDF.
Посмотри на это
newDF = pd.DataFrame() #creates a new dataframe that's empty
newDF = newDF.append(oldDF, ignore_index = True) # ignoring index is optional
# try printing some data from newDF
print newDF.head() #again optional
- если мне нужно продолжать добавлять новые данные в этот newDF из более чем одного oldDF, я просто использую цикл for для перебора pandas.DataFrame.append()
Если вы хотите, чтобы имена ваших столбцов были на месте с самого начала, используйте этот подход:
import pandas as pd
col_names = ['A', 'B', 'C']
my_df = pd.DataFrame(columns = col_names)
my_df
Если вы хотите добавить запись в фрейм данных, лучше использовать:
my_df.loc[len(my_df)] = [2, 4, 5]
Вы также можете передать словарь:
my_dic = {'A':2, 'B':4, 'C':5}
my_df.loc[len(my_df)] = my_dic
Однако, если вы хотите добавить другой фрейм данных в my_df, сделайте следующее:
col_names = ['A', 'B', 'C']
my_df2 = pd.DataFrame(columns = col_names)
my_df = my_df.append(my_df2)
если вы добавляете строки в цикл, учитывайте проблемы с производительностью;
Примерно для первых 1000 записей производительность "my_df.loc" улучшается, и постепенно она замедляется из-за увеличения количества записей в цикле.
Если вы планируете делать тонкие вещи в большом цикле (скажем, 10M записей или около того)
вам лучше использовать смесь этих двух; заполняйте фрейм данных iloc до тех пор, пока размер не достигнет 1000, затем добавьте его к исходному фрейму данных и очистите временный фрейм данных. это повысит вашу производительность примерно в 10 раз
Просто:
import numpy as np
import pandas as pd
df=pd.DataFrame(np.zeros([rows,columns])
Затем залейте его.
Предположим, датафрейм с 19 строками
index=range(0,19)
index
columns=['A']
test = pd.DataFrame(index=index, columns=columns)
Сохранение столбца А в качестве константы
test['A']=10
Сохранение столбца b как переменной, заданной циклом
for x in range(0,19):
test.loc[[x], 'b'] = pd.Series([x], index = [x])
Вы можете заменить первый x в pd.Series([x], index = [x]) любым значением
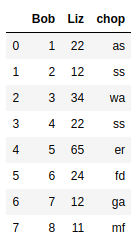
Это мой способ сделать динамический фрейм данных из нескольких списков с помощью цикла
x = [1,2,3,4,5,6,7,8]
y = [22,12,34,22,65,24,12,11]
z = ['as','ss','wa', 'ss','er','fd','ga','mf']
names = ['Bob', 'Liz', 'chop']
цикл
def dataF(x,y,z,names):
res = []
for t in zip(x,y,z):
res.append(t)
return pd.DataFrame(res,columns=names)
Результат
dataF(x,y,z,names)
Кадры данных Pandas можно рассматривать как словарь столбцов pandas (серия pandas). Точно так же, как словарь, в котором добавление новой пары ключ-значение обходится недорого, добавление нового столбца/столбцов очень эффективно (и кадры данных предназначены для такого горизонтального роста).
df = pd.DataFrame()
df['A'] = range(0, 2000_000, 2) # add one column
df[['B', 'C']] = ['a', 'b'] # add multiple columns
С другой стороны, точно так же, как обновление каждого значения словаря требует цикла по всему словарю, увеличение кадра данных по вертикали путем добавления новых строк очень неэффективно. Это особенно неэффективно, если новые строки добавляются одна за другой в цикле (см. этот пост для сравнения возможных вариантов).
Если значения новых строк зависят от значений предыдущих строк, как в OP, то в зависимости от количества столбцов может быть лучше выполнить цикл по предварительно инициализированному кадру данных с нулями или увеличить словарь Python в цикле и построить кадр данных после ( если столбцов более 500, вероятно, лучше выполнить цикл по кадру данных). Но смешивать эти два понятия никогда не бывает оптимально, иными словами, пополнение словаря серии pandas будет чрезвычайно медленным.1
dates = pd.date_range(end=pd.Timestamp('now'), periods=10000, freq='D').date
symbols = [f"col{i}" for i in range(10)]
# initialize a dataframe
df = pd.DataFrame(0, index=dates, columns=symbols)
# update it in a loop
for i, thedate in enumerate(df.index):
if thedate > df.index[0]:
df.loc[thedate] = df.loc[df.index[i-1]] + 1
# build a nested dictionary
data = {}
for i, thedate in enumerate(dates):
for symb in symbols:
if thedate > dates[0]:
data[symb][thedate] = 1 + data[symb][dates[i-1]]
else:
data[symb] = {thedate: 0}
# construct a dataframe after
df1 = pd.DataFrame(data)
1: Тем не менее, для этого конкретного примера:
cumsum()или даже
range()казалось бы, будет работать, даже не перебирая строки. Эта часть ответа больше касается случаев, когда зацикливание неизбежно, например, манипулирование финансовыми данными и т. д.
# import pandas library
import pandas as pd
# create a dataframe
my_df = pd.DataFrame({"A": ["shirt"], "B": [1200]})
# show the dataframe
print(my_df)