Что делает инструкция по сборке x64 "nop dword ptr [rax+rax]"?
Я пытаюсь понять x64 оптимизация сборки, выполняемая компилятором.
Я скомпилировал небольшой проект C++ как Release строить с Visual Studio 2008 SP1 IDE на Windows 8.1.
И одна из строк содержала следующий код сборки:
B8 31 00 00 00 mov eax,31h
0F 1F 44 00 00 nop dword ptr [rax+rax]
И вот скриншот:
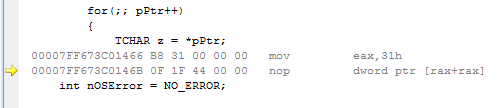
Насколько я знаю nop само по себе это do nothing, но я никогда не видел его с таким операндом.
Может кто-нибудь объяснить, что он делает?
2 ответа
В комментарии в другом месте этой страницы Michael Petch указывает на веб-страницу, которая описывает многобайтовые коды операций NOP Intel x86. На странице есть таблица полезной информации, но, к сожалению, HTML-код запутан, поэтому вы не можете его прочитать. Вот некоторая информация с этой страницы, плюс эта таблица представляет читабельную форму:
Многобайтовая NOP
http://www.felixcloutier.com/x86/NOP.html
Однобайтовая инструкция NOP является мнемоническим псевдонимом для команды XCHG (E)AX, (E)AX.Многобайтовая инструкция NOP не выполняет никаких операций на поддерживаемых процессорах и генерирует неопределенное исключение кода операции на процессорах, которые не поддерживают многобайтовую инструкцию NOP.
Форма операнда памяти инструкции позволяет программному обеспечению создавать последовательность байтов "без операции" как одну инструкцию.
Для ситуаций, когда требуются многобайтовые NOP, рекомендуемые операции (32-битный режим
и 64-битный режим): [ my edit: в 64-битном режиме, записьraxвместоeax, ]Последовательность байтов сборки длины ------- ------------------------------------------ -------------------------- 1 байт № 90 2 байта 66 nop 66 90 3 байта nop dword ptr [eax] 0F 1F 00 4 байта nop dword ptr [eax + 00h] 0F 1F 40 00 5 байтов nop dword ptr [eax + eax*1 + 00h] 0F 1F 44 00 00 6 байтов 66 нет слова ptr [eax + eax*1 + 00h] 66 0F 1F 44 00 00 7 байтов nop dword ptr [eax + 00000000h] 0F 1F 80 00 00 00 00 8 байтов nop dword ptr [eax + eax*1 + 00000000h] 0F 1F 84 00 00 00 00 00 9 байтов 66 нет слова ptr [eax + eax*1 + 00000000h] 66 0F 1F 84 00 00 00 00 00
Обратите внимание, что методика выбора правильной последовательности байтов - и, следовательно, желаемого общего размера - может отличаться в зависимости от того, какой ассемблер вы используете.
Например, следующие две строки сборки, взятые из таблицы, якобы похожи:
nop dword ptr [eax + 00h]
nop dword ptr [eax + 00000000h]
Они отличаются только количеством ведущих нулей, и некоторые ассемблеры могут затруднить отключение их полезной функции, заключающейся в кодировании максимально короткой последовательности байтов, что может сделать второе выражение недоступным.
В случае многобайтовой NOP вам не нужна эта "помощь", потому что вам нужно убедиться, что вы на самом деле получаете желаемое количество байтов. Таким образом, проблема заключается в том, как задать точную комбинацию битов mod и r/m, чтобы вы в конечном итоге получили желаемый размер disp - но только с помощью мнемоники инструкций. Эта тема сложна; подробности см. в Scaled Indexing, MOD + R / M и SIB.
Конечно, если вам трудно или невозможно заставить сотрудничество вашего ассемблера с помощью мнемоники инструкций, вы всегда можете прибегнуть к помощи db ("определить байты") как простая и безопасная альтернатива, которая гарантированно работает.
Как указано в комментариях, это многобайтовая NOP, обычно используемая для выравнивания последующей инструкции по 16-байтовой границе, когда эта инструкция является первой инструкцией в цикле.
Такое выравнивание может помочь с пропускной способностью выборки команд, потому что выборка команд часто происходит в единицах по 16 байтов, поэтому выравнивание вершины цикла дает наибольший шанс, что декодирование происходит без узких мест.
Важность такого выравнивания, возможно, менее важна, чем когда-то, с введением буфера цикла и кэша UOP, которые менее чувствительны к выравниванию. В некоторых случаях эта оптимизация может даже быть пессимизацией, особенно когда цикл выполняется очень мало раз.
Это выравнивание кода выполняется, когда используются инструкции перехода, которые выполняют переходы от больших адресов к более низким (0EBh XX - jmp short) и (0E9h XX XX XX XX - jmp near), где XX в обоих случаях является отрицательным числом со знаком. Итак, компилятор выравнивает этот фрагмент кода, в котором необходимо выполнить переход, до границы в 10 байтов. Это даст оптимизацию и ускорение выполнения кода.