Ускорение без серийной дроби
Я провел ряд экспериментов на параллельном пакете, скажем superlu-dist с разными номерами процессора, например: 4, 16, 32, 64
Я получил время настенных часов для каждого эксперимента, скажем: 53.17s, 32.65s, 24.30s, 16.03s
Формула ускорения:
serial time
Speedup = ----------------------
parallel time
Но нет информации о серийной фракции.
Могу ли я просто взять обратное время настенных часов?
2 ответа
Могу ли я просто взять обратное время настенных часов?
Нет,
истинные цифры ускорения требуют сравнения яблок с яблоками:
Это означает, что оригинальный, чистый [SERIAL] планирование процесса должно сравниваться с любым другим сценарием, где части могут быть изменены, чтобы использовать некоторый параллелизм (параллельная дробь может быть реорганизована, чтобы работать на N ЦП / вычислительные ресурсы, тогда как последовательная дробь оставлена как была).
Это очевидно означает, что оригинал [SERIAL] -код был расширен (как в коде (#pragma -декораторы, OpenCL-модификации, CUDA -{ host_to_dev | dev_to_host } - и т. д.) и вовремя (для выполнения этих дополнительных функций, которых не было в оригинале [SERIAL] -код для сравнения), чтобы добавить несколько новых разделов, где (возможно) [PARALLEL]) другая часть обработки будет иметь место.
Это происходит за счет дополнительных накладных расходов (для установки, завершения и передачи данных из [SERIAL] -часть там, к [PARALLEL] -часть и обратно) - что все добавляет дополнительно [SERIAL] -частичная нагрузка (и время выполнения + задержка).
Для более подробной информации, не стесняйтесь читать раздел Критика в статье о переформулированном законе Амдала.
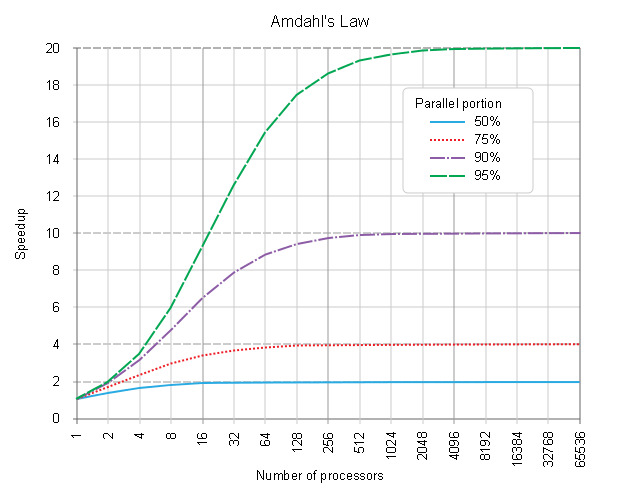
[PARALLEL] -порция кажется интересной, но основной потолок Speedup находится в [SERIAL] продолжительность ( s = 1 - p ) в оригинале,
но к каким длительностям надстроек и дополнительным затратам на задержку нужно прибавлять, поскольку они накапливаются вместе с "организацией" работы из оригинальной, чистой [SERIAL] желаемому иметь [PARALLEL] планирование процесса выполнения кода, если должна быть достигнута реалистичная оценка
запустить тест на одном процессоре и установить его как последовательное время,...,
как @VictorSong предложил звучит легко, но тестирует непоследовательную систему (не чисто [SERIAL] оригинал) и записывает искаженный критерий для сравнения.
Это причина, почему справедливые методы должны быть разработаны. Чистый [SERIAL] оригинальное выполнение кода может иметь временную отметку, чтобы показать реальную длительность неизмененных частей, но время надстройки должно быть включено в расширения надстройки последовательной части теперь распараллеленных тестов.
Пересмотренный Закон убывающей отдачи Амдала объясняет это, в совокупности с последствиями дополнительных накладных расходов, а также атомарности обработки, которые не позволят дальнейшее увеличение производительности при увеличении вычислительных ресурсов, но параллельно Фракция обработки не допускает дальнейшего разделения рабочих нагрузок задачи из-за некоторой формы его внутренней атомарности обработки, которую нельзя разделить дальше, несмотря на наличие свободных процессоров.
Упрощенное из двух, переформулированных выражений выглядит так:
1
S = __________________________; where s, ( 1 - s ), N were defined above
( 1 - s ) pSO:= [PAR]-Setup-Overhead add-on
s + pSO + _________ + pTO pTO:= [PAR]-Terminate-Overhead add-on
N
Некоторые интерактивные GUI-инструменты для дальнейшей визуализации дополнительных накладных расходов доступны здесь для интерактивного параметрического моделирования - просто переместите p ползунок к действительному значению ( 1 - s ) ~ имеющий ненулевую долю очень [SERIAL] часть оригинального кода:

Что вы имеете в виду, когда говорите "серийная дробь"? Согласно поиску в Google, по-видимому, superlu-dist - это C, так что я думаю, что вы можете просто использовать ctime или chrono и взять время обычным способом, он работает для меня как с ручным std::threads, так и с omp.
Я бы просто запустил тест на одном процессоре и установил его как последовательное время, а затем повторил бы тест с большим количеством процессоров (как вы сказали).