Обучение моделей sklearn параллельно с joblib блокирует процесс
Как предлагается в этом ответе, я попытался использовать joblib для параллельного обучения нескольких моделей scikit-learn.
import joblib
import numpy
from sklearn import tree, linear_model
classifierParams = {
"Decision Tree": (tree.DecisionTreeClassifier, {}),''
"Logistic Regression" : (linear_model.LogisticRegression, {})
}
XTrain = numpy.array([[1,2,3],[4,5,6]])
yTrain = numpy.array([0, 1])
def trainModel(name, clazz, params, XTrain, yTrain):
print("training ", name)
model = clazz(**params)
model.fit(XTrain, yTrain)
return model
joblib.Parallel(n_jobs=4)(joblib.delayed(trainModel)(name, clazz, params, XTrain, yTrain) for (name, (clazz, params)) in classifierParams.items())
Однако вызов последней строки занимает много времени без использования процессора, фактически он просто блокируется и никогда ничего не возвращает. В чем моя ошибка?
Тест с очень небольшим количеством данных в XTrain предполагает, что копирование массива numpy между несколькими процессами не является причиной задержки.
1 ответ
В конвейерах машинного обучения промышленного уровня загрузка ЦП примерно такая же, почти 24 / 7 / 365:
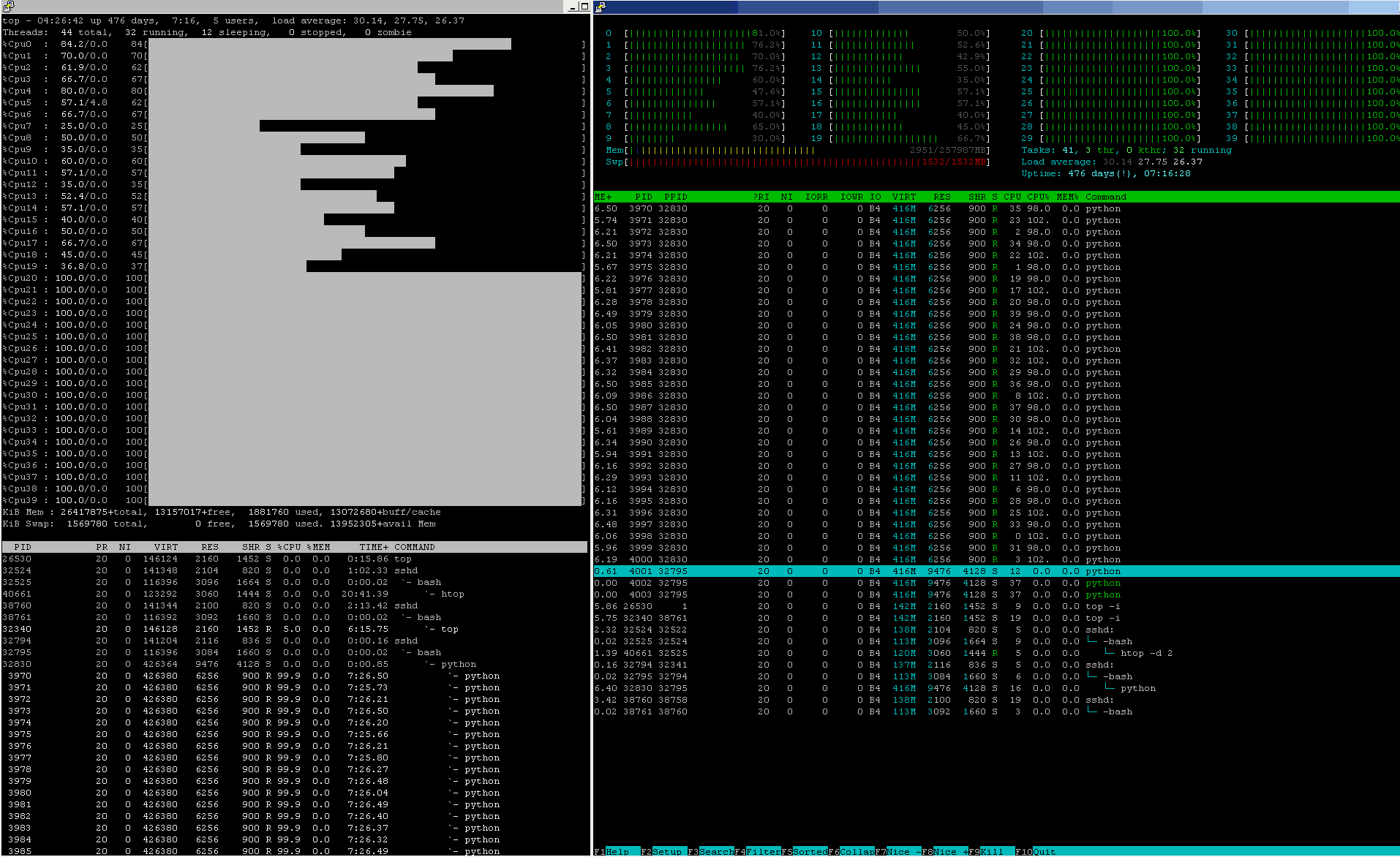
Проверьте оба CPU% а также цифры состояния других ресурсов через этот узел.
В чем моя ошибка?
Прочитав ваш профиль был потрясающий момент, сэр:
Проблема глубоко определяется соблюдением элементарных правил Computer Science + алгоритма.
Проблема не требует сильной научной базы, но здравого смысла.
Проблема не в каких-то особо больших данных, а в том, чтобы понять, как все работает на самом деле.

факты
или же
Эмоции? ... это вопрос! (Трагедия Гамлета, принца Дании)
Могу ли я быть честным? Давайте предпочитаем ФАКТЫ, всегда:
Шаг № 1:
Никогда не нанимайте и не увольняйте ни одного консультанта, который не уважает факты (приведенный выше ответ ничего не предлагал, тем более не давал никаких обещаний). Игнорирование фактов может быть " успешным грехом " в бизнесе PR / MARCOM / Advertising / media (в случае, если Заказчик допускает такую нечестность и / или манипулятивную привычку), но не в научно обоснованных количественных областях. Это непростительно.
Шаг № 2:
Никогда не нанимайте и не увольняйте всех подрядчиков, которые утверждали, что имеют опыт работы в архитектуре программного обеспечения, особенно в области решений для... больших данных, но не обращают внимания на накопленную сумму всех дополнительных накладных расходов, которые будут введены каждый из соответствующих элементов архитектуры системы, после того как обработка начала распределяться по некоторому пулу аппаратных и программных ресурсов. Это непростительно.
Шаг № 3:
Никогда не нанимайте и не увольняйте всех и каждого консультанта, который становится пассивно агрессивным, когда факты не соответствуют ее / его желаниям, и начинает обвинять других знающих людей, которые уже оказали помощь, вместо того, чтобы "улучшать (свои) навыки общения" вместо обучения от ошибки (с). Конечно, умение может помочь выразить очевидные ошибки каким-то другим способом, однако гигантские ошибки останутся гигантскими ошибками, и каждый ученый, справедливый по отношению к своему научному названию, НИКОГДА не прибегает к нападению на помогающего коллегу, но Лучше начать искать причину ошибок, одну за другой. Это ---
sascha... Могу ли я предложить вам немного отдохнуть от sascha, чтобы охладиться, немного поработать над своими навыками межличностного общения
--- это было просто и интеллектуально неприемлемо противное нарушение правил sascha.
Далее игрушки
Факты архитектуры, ресурсов и планирования процессов, которые имеют значение:
Императивная форма синтаксического конструктора запускает огромное количество действий для запуска:
joblib.Parallel( n_jobs = <N> )( joblib.delayed( <aFunction> )
( <anOrderedSetOfFunParameters> )
for ( <anOrderedSetOfIteratorParams> )
in <anIterator>
)
Чтобы хотя бы угадать, что происходит, с научной точки зрения справедливым подходом было бы протестировать несколько репрезентативных случаев, сравнить их фактическое выполнение, собрать количественно подтвержденные факты и выдвинуть гипотезу о модели поведения и ее основных зависимостях от CPU_core-count, от объема RAM на <aFunction> - сложность и распределение ресурсов и т.д.
Контрольный пример A:
def a_NOP_FUN( aNeverConsumedPAR ):
""" __doc__
The intent of this FUN() is indeed to do nothing at all,
so as to be able to benchmark
all the process-instantiation
add-on overhead costs.
"""
pass
##############################################################
### A NAIVE TEST BENCH
##############################################################
from zmq import Stopwatch; aClk = Stopwatch()
JOBS_TO_SPAWN = 4 # TUNE: 1, 2, 4, 5, 10, ..
RUNS_TO_RUN = 10 # TUNE: 10, 20, 50, 100, 200, 500, 1000, ..
try:
aClk.start()
joblib.Parallel( n_jobs = JOBS_TO_SPAWN
)( joblib.delayed( a_NOP_FUN )
( aSoFunPAR )
for ( aSoFunPAR )
in range( RUNS_TO_RUN )
)
except:
pass
finally:
try:
_ = aClk.stop()
except:
_ = -1
pass
print( "CLK:: {0:_>24d} [us] @{1: >3d} run{2: >5d} RUNS".format( _,
JOBS_TO_SPAWN,
RUNS_TO_RUN
)
)
Собрав достаточно репрезентативные данные по этому NOP-случаю в достаточно масштабном 2D-ландшафте [ RUNS_TO_RUN, JOBS_TO_SPAWN] -cartesian-space DataPoints, чтобы генерировать, по крайней мере, из первых рук фактические системные затраты на запуск служебных нагрузок фактически пустых процессов, связанных с обязательным инструктажем joblib.Parallel(...)( joblib.delayed(...) ) -синтаксический конструктор, порождающий в системный планировщик всего несколько joblib -удалось a_NOP_FUN() экземпляров.
Давайте также согласимся, что все реальные проблемы, включая модели машинного обучения, являются более сложными инструментами, чем только что протестированные. a_NOP_FUN() в то время как в обоих случаях вы должны оплатить уже измеренные накладные расходы (даже если они были заплачены за получение буквально нулевого продукта).
Таким образом, из этого простейшего случая последует справедливая и научно обоснованная работа, уже показывающая минимальные затраты на все связанные с этим накладные расходы на установку. joblib.Parallel() штраф за непременное условие продвигается в направлении, в котором живут алгоритмы реального мира - лучше всего с последующим добавлением большего и большего размера "полезной нагрузки" в цикл тестирования:
Тест-кейс B:
def a_NOP_FUN_WITH_JUST_A_MEM_ALLOCATOR( aNeverConsumedPAR ):
""" __doc__
The intent of this FUN() is to do nothing but
a MEM-allocation
so as to be able to benchmark
all the process-instantiation
add-on overhead costs.
"""
import numpy as np # yes, deferred import, libs do defer imports
SIZE1D = 1000 # here, feel free to be as keen as needed
aMemALLOC = np.zeros( ( SIZE1D, # so as to set
SIZE1D, # realistic ceilings
SIZE1D, # as how big the "Big Data"
SIZE1D # may indeed grow into
),
dtype = np.float64,
order = 'F'
) # .ALLOC + .SET
aMemALLOC[2,3,4,5] = 8.7654321 # .SET
aMemALLOC[3,3,4,5] = 1.2345678 # .SET
return aMemALLOC[2:3,3,4,5]
Снова,
собрать достаточно представительные количественные данные о затратах фактических MEM-распределений удаленного процесса, запустив a_NOP_FUN_WITH_JUST_A_MEM_ALLOCATOR() над каким-то разумным широким ландшафтом SIZE1D -scaling,
снова
над достаточно масштабным 2D-ландшафтом [ RUNS_TO_RUN, JOBS_TO_SPAWN] -cartesian-space DataPoints, чтобы коснуться нового измерения в масштабировании производительности, в рамках расширенного черного ящика PROCESS_under_TEST внутри эксперимента joblib.Parallel() инструмент, оставив свою магию еще не открытой.
Тест-кейс C:
def a_NOP_FUN_WITH_SOME_MEM_DATAFLOW( aNeverConsumedPAR ):
""" __doc__
The intent of this FUN() is to do nothing but
a MEM-allocation plus some Data MOVs
so as to be able to benchmark
all the process-instantiation + MEM OPs
add-on overhead costs.
"""
import numpy as np # yes, deferred import, libs do defer imports
SIZE1D = 1000 # here, feel free to be as keen as needed
aMemALLOC = np.ones( ( SIZE1D, # so as to set
SIZE1D, # realistic ceilings
SIZE1D, # as how big the "Big Data"
SIZE1D # may indeed grow into
),
dtype = np.float64,
order = 'F'
) # .ALLOC + .SET
aMemALLOC[2,3,4,5] = 8.7654321 # .SET
aMemALLOC[3,3,4,5] = 1.2345678 # .SET
aMemALLOC[:,:,:,:]*= 0.1234567
aMemALLOC[:,3,4,:]+= aMemALLOC[4,5,:,:]
aMemALLOC[2,:,4,:]+= aMemALLOC[:,5,6,:]
aMemALLOC[3,3,:,:]+= aMemALLOC[:,:,6,7]
aMemALLOC[:,3,:,5]+= aMemALLOC[4,:,:,7]
return aMemALLOC[2:3,3,4,5]
Взрыв, Проблемы, связанные с архитектурой, начинают медленно появляться:
Вскоре можно заметить, что не только статические размеры, но и MAND-транспорт BANDWIDTH (аппаратно-аппаратный) начнут вызывать проблемы, так как перемещение данных из / в CPU в / из MEM стоит дорого ~ 100 .. 300 [ns] это намного больше, чем любое умное перетасовывание нескольких байтов "внутри" CPU_core, { CPU_core_private | CPU_core_shared | CPU_die_shared }- архитектура иерархии кэша в одиночку (и любая нелокальная передача NUMA демонстрирует такую же боль дополнительного порядка).
Все вышеперечисленные тест-кейсы пока не потребовали от CPU особых усилий
Итак, начнем сжигать масло!
Если все вышеперечисленное было хорошо для того, чтобы начать чувствовать запах того, как вещи под капотом на самом деле работают, это станет грязным и грязным.
Тест-кейс D:
def a_CPU_1_CORE_BURNER_FUN( aNeverConsumedPAR ):
""" __doc__
The intent of this FUN() is to do nothing but
add some CPU-load
to a MEM-allocation plus some Data MOVs
so as to be able to benchmark
all the process-instantiation + MEM OPs
add-on overhead costs.
"""
import numpy as np # yes, deferred import, libs do defer imports
SIZE1D = 1000 # here, feel free to be as keen as needed
aMemALLOC = np.ones( ( SIZE1D, # so as to set
SIZE1D, # realistic ceilings
SIZE1D, # as how big the "Big Data"
SIZE1D # may indeed grow into
),
dtype = np.float64,
order = 'F'
) # .ALLOC + .SET
aMemALLOC[2,3,4,5] = 8.7654321 # .SET
aMemALLOC[3,3,4,5] = 1.2345678 # .SET
aMemALLOC[:,:,:,:]*= 0.1234567
aMemALLOC[:,3,4,:]+= aMemALLOC[4,5,:,:]
aMemALLOC[2,:,4,:]+= aMemALLOC[:,5,6,:]
aMemALLOC[3,3,:,:]+= aMemALLOC[:,:,6,7]
aMemALLOC[:,3,:,5]+= aMemALLOC[4,:,:,7]
aMemALLOC[:,:,:,:]+= int( [ np.math.factorial( x + aMemALLOC[-1,-1,-1] )
for x in range( 1005 )
][-1]
/ [ np.math.factorial( y + aMemALLOC[ 1, 1, 1] )
for y in range( 1000 )
][-1]
)
return aMemALLOC[2:3,3,4,5]
Ничего необычного по сравнению с обычным классом полезных нагрузок в области многомерного пространства машинного обучения, где все размеры { aMlModelSPACE, aSetOfHyperParameterSPACE, aDataSET } -state-space влияет на объем требуемой обработки (некоторые имеют O( N ), несколько других O( N.logN ) сложность), где почти сразу, где хорошо спроектировано более чем один CPU_core, скоро будет задействовано даже на одном прогоне "задания".
По-настоящему неприятный запах начинается, когда наивные (несогласованные по чтению ресурсы используются) смеси нагрузок на ЦП выходят на дорогу, а когда смеси нагрузок на ЦП начинают смешиваться с наивными (считывают нескоординированные ресурсы)) Процессы O/S-планировщика оказываются в борьбе за общие (прибегают только к наивной политике совместного использования) ресурсы - то есть MEM (представляя SWAPs как АД), CPU (вводящие ошибки кэша и повторные выборки MEM (да, с помощью SWAP) добавлены штрафы), не говоря уже о выплате более ~ 15+ [ms] плата за задержку, если кто-то забывает и позволяет процессу коснуться fileIO - (5 (!)- на порядки медленнее + делится + будучи чистым [SERIAL] По натуре)-устройство. Здесь никакие молитвы не помогают (в том числе SSD, всего на несколько порядков меньше, но все равно это ад, который невероятно быстро делит и запускает устройство в его износ + могилу слез).
Что происходит, если все порожденные процессы не помещаются в физическую память?
Пейджинг виртуальной памяти и перестановки начинают буквально ухудшать остальную часть пока что "просто" по совпадению (читай: слабо скоординировано)- [CONCURRENTLY]- плановая обработка (читай: дальнейшее снижение индивидуальной производительности PROCESS-under-TEST).
Вещи могут так скоро разрушиться, если не будут находиться под должным контролем и контролем.
Опять же - факт имеет значение: легкий класс мониторинга ресурсов может помочь:
aResRECORDER.show_usage_since0() method returns:
ResCONSUMED[T0+ 166036.311 ( 0.000000)]
user= 2475.15
nice= 0.36
iowait= 0.29
irq= 0.00
softirq= 8.32
stolen_from_VM= 26.95
guest_VM_served= 0.00
Аналогично, более богато сконструированный монитор ресурсов может сообщать о более широком контексте O / S, чтобы увидеть, где дополнительные условия кражи ресурсов / состязаний / состязаний ухудшают фактически достигнутый поток процесса:
>>> psutil.Process( os.getpid()
).memory_full_info()
( rss = 9428992,
vms = 158584832,
shared = 3297280,
text = 2322432,
lib = 0,
data = 5877760,
dirty = 0
)
.virtual_memory()
( total = 25111490560,
available = 24661327872,
percent = 1.8,
used = 1569603584,
free = 23541886976,
active = 579739648,
inactive = 588615680,
buffers = 0,
cached = 1119440896
)
.swap_memory()
( total = 8455712768,
used = 967577600,
free = 7488135168,
percent = 11.4,
sin = 500625227776,
sout = 370585448448
)
Wed Oct 19 03:26:06 2017
166.445 ___VMS______________Virtual Memory Size MB
10.406 ___RES____Resident Set Size non-swapped MB
2.215 ___TRS________Code in Text Resident Set MB
14.738 ___DRS________________Data Resident Set MB
3.305 ___SHR_______________Potentially Shared MB
0.000 ___LIB_______________Shared Memory Size MB
__________________Number of dirty pages 0x
И последнее, но не менее важное: почему можно легко заплатить больше, чем заработать взамен?
Помимо постепенно накапливающихся данных, свидетельствующих о том, как реальные накладные расходы на развертывание системы накапливают затраты, недавно пересмотренный закон Амдала был расширен, чтобы покрыть как накладные накладные расходы, так и "процесс". "атомарность" определения размеров дальнейших неделимых частей определяет максимальный порог дополнительных затрат, который может быть разумно оплачен, если какая-то распределенная обработка должна обеспечить какой-либо из указанных выше >= 1.00 ускорение вычислительного процесса.
Несоблюдение явной логики переформулированного Закона Амдала приводит к тому, что процесс протекает хуже, чем если бы он был обработан в чистом виде. [SERIAL] планирование процесса (и иногда результаты плохой практики проектирования и / или эксплуатации могут выглядеть так, как если бы это был случай, когда joblib.Parallel()( joblib.delayed(...) ) метод "блокирует процесс").