Как понять локальное хеширование?
Я заметил, что LSH, кажется, хороший способ найти похожие элементы с большими свойствами.
После прочтения статьи http://www.slaney.org/malcolm/yahoo/Slaney2008-LSHTutorial.pdf я все еще не понимаю эти формулы.
Кто-нибудь знает блог или статью, которая объясняет, что легкий путь?
5 ответов
Лучший учебник, который я видел для LSH, находится в книге: Mining of Massive Datasets. Проверьте главу 3 - Поиск похожих предметов http://infolab.stanford.edu/~ullman/mmds/ch3a.pdf
Также я рекомендую следующий слайд: http://www.cs.jhu.edu/~vandurme/papers/VanDurmeLallACL10-slides.pdf. Пример на слайде помогает мне понять хэширование сходства косинусов.
Я позаимствовал два слайда у Бенджамина Ван Дурма и Эшвина Лалла, ACL2010, и попытался немного объяснить интуицию LSH Families for Cosine Distance. 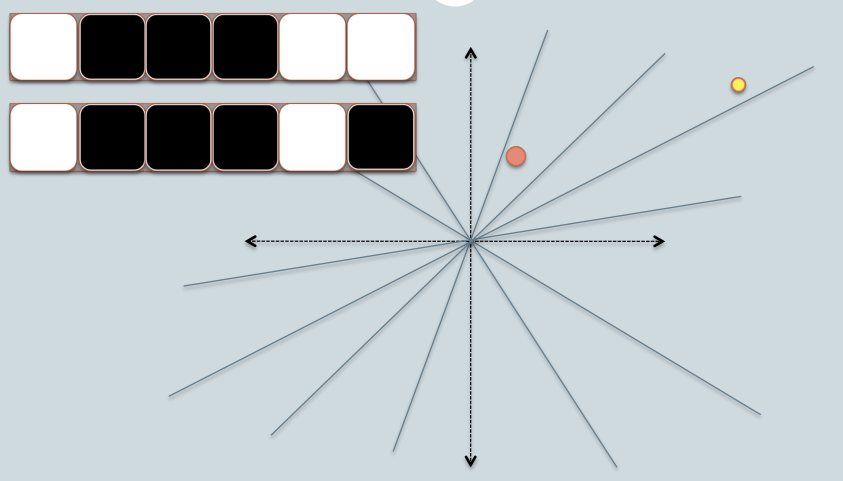
- На рисунке два круга с красным и желтым цветом, представляющие две двумерные точки данных. Мы пытаемся найти сходство их косинусов, используя LSH.
- Серые линии - это несколько случайно выбранных плоскостей.
- В зависимости от того, находится ли точка данных выше или ниже серой линии, мы помечаем это отношение как 0/1.
- В верхнем левом углу есть две строки белых / черных квадратов, представляющих подпись двух точек данных соответственно. Каждый квадрат соответствует биту 0(белый) или 1(черный).
- Поэтому, когда у вас есть пул плоскостей, вы можете кодировать точки данных с их расположением в соответствии с плоскостями. Представьте, что когда у нас в пуле больше плоскостей, угловая разница, закодированная в сигнатуре, ближе к реальной разнице. Потому что только плоскости, находящиеся между двумя точками, будут давать разным битам два значения данных.
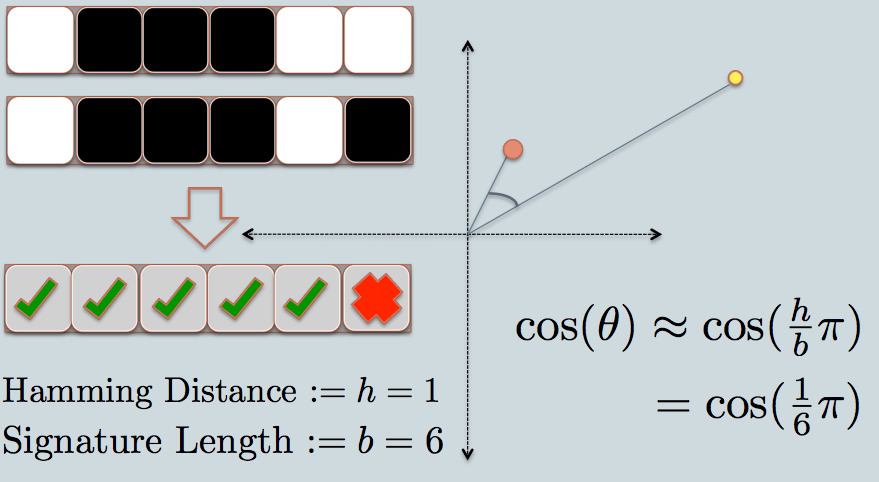
- Теперь мы смотрим на подпись двух точек данных. Как и в примере, мы используем только 6 битов (квадратов) для представления каждой информации. Это хэш LSH для исходных данных, которые мы имеем.
- Расстояние Хемминга между двумя значениями хэширования равно 1, поскольку их сигнатуры отличаются только на 1 бит.
- Учитывая длину подписи, мы можем вычислить их угловое сходство, как показано на графике.
У меня есть пример кода (всего 50 строк) в Python, который использует косинусное сходство. https://gist.github.com/94a3d425009be0f94751
Твиты в векторном пространстве могут быть отличным примером многомерных данных.
Прочтите мой пост в блоге о применении Locality Sensitive Hashing к твитам, чтобы найти похожие.
http://micvog.com/2013/09/08/storm-first-story-detection/
А поскольку одна картинка - это тысяча слов, проверьте картинку ниже:
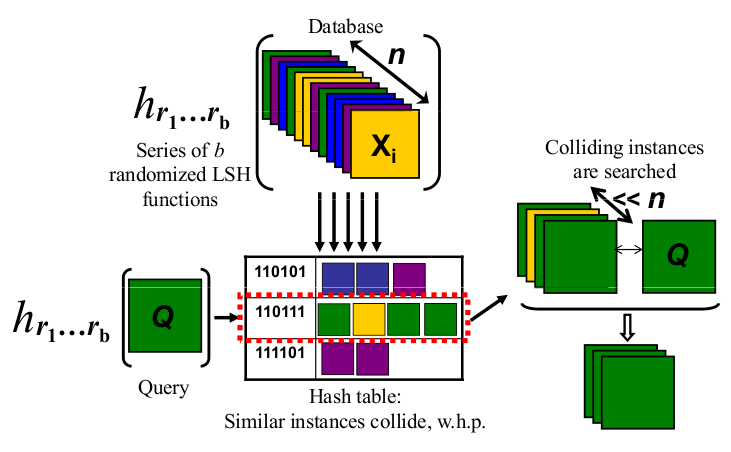 http://micvog.files.wordpress.com/2013/08/lsh1.png
http://micvog.files.wordpress.com/2013/08/lsh1.png
Надеюсь, поможет. @mvogiatzis
Вот презентация из Стэнфорда, которая объясняет это. Это имело большое значение для меня. Вторая часть больше о LSH, но первая часть также охватывает это.
Картинка обзора (на слайдах их гораздо больше):
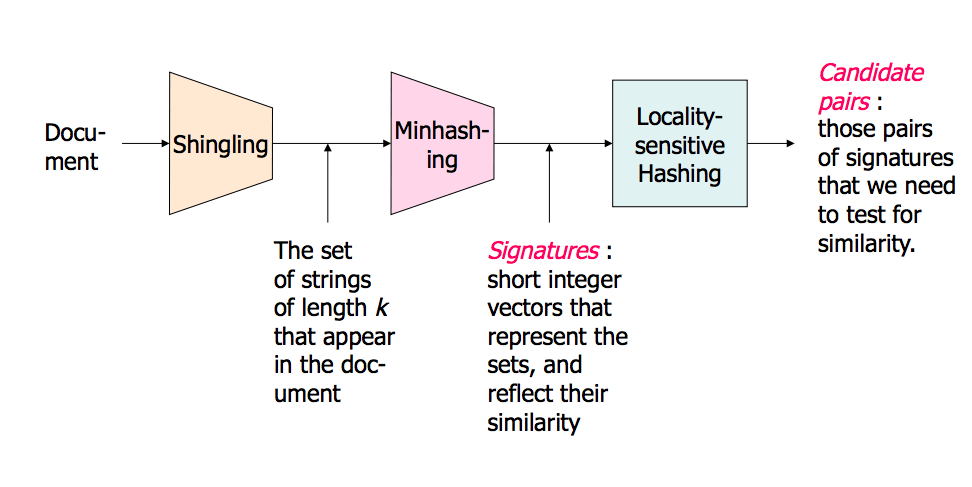
Поиск в окрестностях соседей в многомерных данных - часть 1: http://www.stanford.edu/class/cs345a/slides/04-highdim.pdf
Поиск в окрестностях соседей в многомерных данных - часть 2: http://www.stanford.edu/class/cs345a/slides/05-LSH.pdf
- LSH - это процедура, которая принимает в качестве входных данных набор документов / изображений / объектов и выводит вид хэш-таблицы.
- Индексы этой таблицы содержат документы, так что документы, находящиеся в одном и том же индексе, считаются похожими, а документы в разных индексах - "разными".
- Где сходство зависит от метрической системы, а также от порогового сходства s, которое действует как глобальный параметр LSH.
- Это зависит от вас, чтобы определить, какой порог адекватен вашей проблеме.

Важно подчеркнуть, что разные меры сходства имеют разные реализации LSH.
В своем блоге я попытался подробно объяснить LSH для случаев minHashing(мера сходства jaccard) и simHashing (мера косинусного расстояния). Я надеюсь, что вы найдете это полезным: https://aerodatablog.wordpress.com/2017/11/29/locality-sensitive-hashing-lsh/
Я визуальный человек. Вот что работает для меня как интуиция.
Скажите, что каждая вещь, которую вы хотите найти приблизительно, это физические объекты, такие как яблоко, куб, стул.
Моя интуиция в отношении LSH заключается в том, что он похож на отбрасывание теней этих объектов. Например, если вы возьмете тень 3D-куба, вы получите 2D-квадрат на листе бумаги, или 3D-сфера даст вам круговую тень на листе бумаги.
В конце концов, в задаче поиска есть намного больше трех измерений (где каждое слово в тексте может быть одним измерением), но аналогия с тенью все еще очень полезна для меня.
Теперь мы можем эффективно сравнивать строки битов в программном обеспечении. Битовая строка фиксированной длины более или менее похожа на строку в одном измерении.
Поэтому с помощью LSH я проецирую тени объектов в конечном итоге как точки (0 или 1) на одну строку / битовую строку фиксированной длины.
Весь трюк состоит в том, чтобы взять тени так, чтобы они все еще имели смысл в более низком измерении, например, они достаточно хорошо напоминают исходный объект, который можно распознать.
Двухмерный чертеж куба в перспективе говорит мне, что это куб. Но я не могу легко отличить 2D-квадрат от 3D-кубовой тени без перспективы: они оба выглядят для меня как квадрат.
То, как я представляю свой объект свету, будет определять, получу ли я хорошо узнаваемую тень или нет. Так что я думаю о "хорошем" LSH как о том, который повернет мои объекты перед светом так, чтобы их тень лучше всего узнавалась как представляющая мой объект.
Итак, подведем итоги: я думаю о вещах, которые нужно индексировать с помощью LSH, как о физических объектах, таких как куб, стол или стул, и я проецирую их тени в 2D и, в конечном счете, вдоль линии (битовая строка). И "хорошая" LSH "функция" - это то, как я представляю свои объекты перед источником света, чтобы получить приблизительно различимую форму в 2D равнине, а затем и в моей битовой струне.
Наконец, когда я хочу найти, похож ли мой объект на некоторые объекты, которые я проиндексировал, я беру тени этого объекта "запрос", используя тот же способ, чтобы представить мой объект перед источником света (в конце концов, немного Строка тоже). И теперь я могу сравнить, насколько похожа эта битовая строка со всеми моими другими индексированными битовыми строками, которая является прокси-сервером для поиска моих объектов целиком, если я нашел хороший и узнаваемый способ представить мои объекты моему свету.
В качестве очень короткого ответа tldr:
Примером хеширования с учетом местоположения может быть первое случайное задание плоскостей (с поворотом и смещением) в вашем пространстве входных данных в хэш, а затем сброс ваших точек в хеш в пространстве, и для каждой плоскости, которую вы измеряете, является ли точка над или под ним (например: 0 или 1), а ответ - хеш. Таким образом, точки, похожие в пространстве, будут иметь одинаковый хэш, если их измерить с помощью косинусного расстояния до или после.
Вы можете прочитать этот пример с помощью scikit-learn: https://github.com/guillaume-chevalier/SGNN-Self-Governing-Neural-Networks-Projection-Layer