Агрегировать разные строки разными функциями в R
У меня есть следующий фрейм данных: 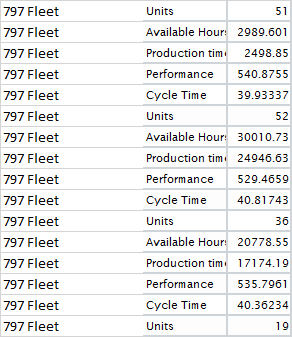
(dput() для тестирования ниже)
structure(list(V1 = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L), .Label = "797 Fleet", class = "factor"), V2 = structure(c(5L, 1L, 4L, 3L, 2L, 5L, 1L, 4L, 3L, 2L, 5L, 1L, 4L, 3L, 2L, 5L), .Label = c("Available Hours", "Cycle Time", "Performance", "Production time", "Units"), class = "factor"), V3 = c(51, 2989.601111, 2498.85, 540.8754973, 39.93337086, 52, 30010.73389, 24946.62833, 529.4659407, 40.81742793, 36, 20778.5525, 17174.18722, 535.7960907, 40.36234152, 19)), .Names = c("V1", "V2", "V3"), class = "data.frame", row.names = c(NA, -16L))
мне нужно агрегировать данные, но с разными функциями для разных функций; для флота 797 следует добавить единицы и время производства, но производительность за цикл следует усреднить.
Я только что попробовал объединить с двумя функциями, но я получаю два столбца, один со всеми добавленными, а другой со всеми усредненными, и мне нужен только один столбец.
Как я могу это сделать?
3 ответа
Вот идея использования data.table:
library(data.table)
fun_list <- list("Units" = sum, "Production time" = sum, "Performance" = mean, "Cycle Time" = mean)
setDT(df)[V2 %in% names(fun_list), .(res = fun_list[[as.character(.BY[[2]])]](V3)),by = .(V1, V2)]
# V1 V2 res
#1: 797 Fleet Units 158.00000
#2: 797 Fleet Production time 44619.66555
#3: 797 Fleet Performance 535.37918
#4: 797 Fleet Cycle Time 40.37105
Давайте немного распакуем это решение. Сначала мы храним карту функций, которые мы хотим применить к каждому из значений в V2, Этот список просто список функций. Например "Units" = sum означает, что мы хотим применить sum к "Units" группа. Чтобы увидеть, как это работает, попробуйте: fun_list[["Units"]](c(1,2,3)),
Затем мы используем это в нашей группе с помощью операции в data.table, Мы используем V2 значение хранится в .BY индексировать наш список функций. Это для каждого V2 Значение мы выбираем функцию из нашего списка, чтобы применить. Это достигается fun_list[[as.character(.BY[[2]])]] (Обратите внимание, что нам нужно as.character поскольку .BY это фактор). Наконец, мы применяем эту функцию к V3 который является то, что (V3) делает в последней части кода fun_list[[as.character(.BY[[2]])]](V3))!
Я не думаю, что есть прямой способ сделать это с помощью агрегирования... Сначала вам нужно будет создать отдельные наборы данных с интересующими вас функциями, а затем агрегировать, используя нужную функцию:
t1<-rbind(subset(test, test$V2=="Units"), subset(test, test$V2=="Production time"))
aggregate(.~V2, data=t1, sum)
Вот решение, использующее split() для разделения фрейма данных на список фреймов данных, один элемент списка (фрейм данных) на уровень V2, а затем отдельные функции lapply для создания сводок с требуемой функцией агрегирования. Наконец объедините все вместе, используя Reduce и rbind
df <- structure(list(V1 = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L), .Label = "797 Fleet", class = "factor"),
V2 = structure(c(5L, 1L, 4L, 3L, 2L, 5L, 1L, 4L, 3L, 2L,
5L, 1L, 4L, 3L, 2L, 5L), .Label = c("Available Hours", "Cycle Time",
"Performance", "Production time", "Units"), class = "factor"),
V3 = c(51, 2989.601111, 2498.85, 540.8754973, 39.93337086,
52, 30010.73389, 24946.62833, 529.4659407, 40.81742793, 36,
20778.5525, 17174.18722, 535.7960907, 40.36234152, 19)), .Names = c("V1",
"V2", "V3"), class = "data.frame", row.names = c(NA, -16L))
df_list <- split(df, df$V2)
summary <- c(
lapply(df_list[c("Units", "Production time")],
function(df) {aggregate(V3 ~ V1 + V2, data = df, sum)})
,
lapply(df_list[c("Performance", "Cycle Time")],
function(df) {aggregate(V3 ~ V1 + V2, data = df, mean)})
)
Reduce(rbind, summary)
#> V1 V2 V3
#> 1 797 Fleet Units 158.00000
#> 2 797 Fleet Production time 44619.66555
#> 3 797 Fleet Performance 535.37918
#> 4 797 Fleet Cycle Time 40.37105