Невозможно понять координаты в извлеченном документе, используя тессеракт механизма OCR
Я извлек документ изображения из tesseract, и он был извлечен успешно. Но я не могу понять координаты извлеченного документа.
Описание проблемы: -
Это показывает координаты, но дайте мне знать, что эти координаты представляют пиксель или что-то еще. Они в четырех, как title = "bbox 10 13 43 46", так что это 10, 13 43 и 46. Какую позицию они представляют
полный код после распаковки
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>
</title>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<meta name='ocr-system' content='tesseract'/>
</head>
<body>
<div class='ocr_page' id='page_1' title='image "D:\ABC.tif"; bbox 0 0 464 101'>
<div class='ocr_carea' id='block_1_1' title="bbox 10 13 330 55">
<p 1class='ocr_par'>
<span class='ocr_line' id='line_1_1' title="bbox 10 13 330 55">
<span class='ocr_word' id='word_1_1' title="bbox 10 13 43 46">
<span class='ocrx_word' id='xword_1_1' title="x_wconf -1"><strong>hi</strong></span>
</span>
<span class='ocr_word' id='word_1_2' title="bbox 148 13 268 47">
<span class='ocrx_word' id='xword_1_2' title="x_wconf -1"><strong>whats</strong></span>
</span>
<span class='ocr_word' id='word_1_3' title="bbox 283 22 330 55">
<span class='ocrx_word' id='xword_1_3' title="x_wconf -1"><strong>up</strong></span>
</span>
</span>
</p>
</div>
</div>
</body>
</html>
3 ответа
Хорошо для всех, кто все еще задается вопросом, как работает система координат, я наконец нашел это, и это похоже на
10 13 43 46 startx, starty, endx, endy
если вы хотите найти ширину и высоту слова, которое было бы
ширина = endx - startx, высота = endy - starty
разделите строку с помощью ' ', а затем удалите bbox, и вот, пожалуйста.
Может быть, это поможет кому-то в будущем. Я думаю, что изображение говорит само за себя. Вы можете вычислить высоту или верхнее расстояние (для css) из этих значений (например, height = y1-y0) 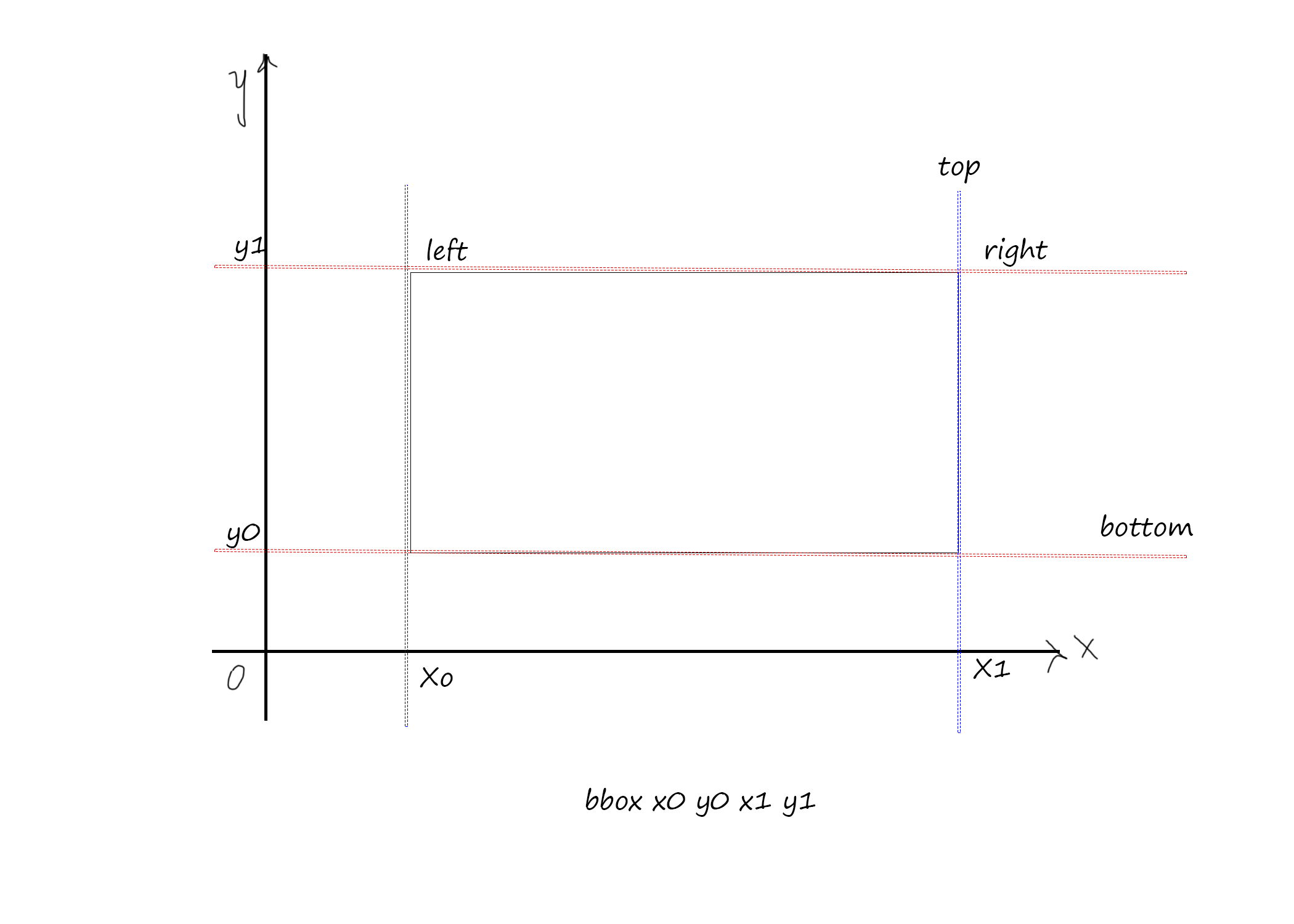
Эти цифры должны показывать положение угла прямоугольника (прямоугольника), в котором есть одно слово.
Это протокол HOCR.
согласно вашему документу, тессеракт признает предложение "привет, как дела?"