Как Hadoop обрабатывает записи через границы блоков?
Согласно Hadoop - The Definitive Guide
Логические записи, которые определяют FileInputFormats, обычно не вписываются в блоки HDFS. Например, логические записи TextInputFormat - это строки, которые чаще, чем нет, пересекают границы HDFS. Это не имеет никакого отношения к функционированию вашей программы - например, строки не пропущены и не разбиты - но об этом стоит знать, поскольку это означает, что карты локальных данных (то есть карты, которые работают на том же хосте, что и их входные данные) выполнит некоторые дистанционные чтения. Незначительные накладные расходы, которые это вызывает, обычно не значительны
Предположим, строка записи разделена на два блока (b1 и b2). Обработчик, обрабатывающий первый блок (b1), заметит, что последняя строка не имеет разделителя EOL, и извлечет оставшуюся часть строки из следующего блока данных (b2).
Как преобразователь, обрабатывающий второй блок (b2), определяет, что первая запись является неполной и должна обрабатываться, начиная со второй записи в блоке (b2)?
6 ответов
Интересный вопрос, я провел некоторое время, просматривая код для деталей, и вот мои мысли. Разделения обрабатываются клиентом InputFormat.getSplits Итак, взгляд на FileInputFormat дает следующую информацию:
- Для каждого входного файла получите длину файла, размер блока и рассчитайте размер разбиения как
max(minSize, min(maxSize, blockSize))гдеmaxSizeсоответствуетmapred.max.split.sizeа такжеminSizeявляетсяmapred.min.split.size, Разделите файл на разные
FileSplits на основе размера разделения, рассчитанного выше. Здесь важно то, что каждыйFileSplitинициализируется сstartпараметр, соответствующий смещению во входном файле. В этой точке все еще нет обработки строк. Соответствующая часть кода выглядит следующим образом:while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(new FileSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts())); bytesRemaining -= splitSize; }
После этого, если вы посмотрите на LineRecordReader который определяется TextInputFormat вот где обрабатываются строки:
- Когда вы инициализируете свой
LineRecordReaderон пытается создатьLineReaderкоторый является абстракцией, чтобы иметь возможность читать строки надFSDataInputStream, Есть 2 случая: - Если есть
CompressionCodecопределяется, то этот кодек отвечает за обработку границ. Вероятно, не имеет отношения к вашему вопросу. Однако, если кодека нет, вот что интересно: если
startвашейInputSplitотличается от 0, то вы возвращаете 1 символ, а затем пропускаете первую встреченную строку, обозначенную \n или \ r \n (Windows)! Возврат важен, потому что в случае, если ваши границы линий совпадают с границами разделения, это гарантирует, что вы не пропустите действительную строку. Вот соответствующий код:if (codec != null) { in = new LineReader(codec.createInputStream(fileIn), job); end = Long.MAX_VALUE; } else { if (start != 0) { skipFirstLine = true; --start; fileIn.seek(start); } in = new LineReader(fileIn, job); } if (skipFirstLine) { // skip first line and re-establish "start". start += in.readLine(new Text(), 0, (int)Math.min((long)Integer.MAX_VALUE, end - start)); } this.pos = start;
Таким образом, поскольку разбиения вычисляются в клиенте, преобразователи не должны запускаться последовательно, каждый преобразователь уже знает, нужно ли ему отбрасывать первую строку или нет.
Таким образом, в основном, если у вас есть 2 строки по 100 МБ в одном файле, и для упрощения, скажем, размер разделения составляет 64 МБ. Затем, когда расчеты входных данных будут рассчитаны, мы получим следующий сценарий:
- Разделить 1, содержащий путь и хосты к этому блоку. Инициализируется при запуске 200-200=0 МБ, длина 64 МБ.
- Разделение 2 инициализируется при запуске 200-200+64=64 МБ, длина 64 МБ.
- Split 3 инициализируется при запуске 200-200+128=128Mb, длина 64Mb.
- Разделение 4 инициализируется при запуске 200-200+192=192 МБ, длина 8 МБ.
- Mapper A будет обрабатывать split 1, start равен 0, поэтому не пропускайте первую строку и читайте полную строку, которая выходит за пределы 64 МБ, поэтому необходимо удаленное чтение.
- Mapper B будет обрабатывать разделение 2, начало равно!= 0, поэтому пропустите первую строку после 64 МБ-1 байта, что соответствует концу строки 1 на 100 МБ, которая все еще находится в разделении 2, у нас есть 28 МБ строки в разделении 2, поэтому удаленное чтение оставшихся 72Мб.
- Mapper C будет обрабатывать split 3, start is!= 0, поэтому пропустите первую строку после 128Mb-1 байта, что соответствует концу строки 2 на 200Mb, который является концом файла, поэтому ничего не делайте.
- Mapper D такой же, как Mapper C, за исключением того, что он ищет новую строку после 192Mb-1 байта.
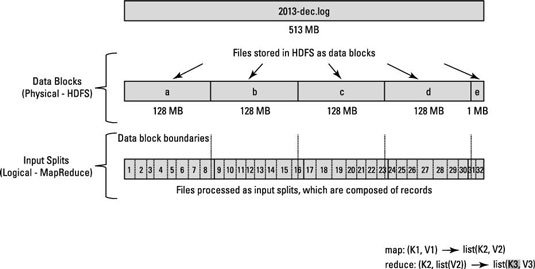
АлгоритмMap Reduce не работает с физическими блоками файла. Работает на логических разделениях ввода. Разделение ввода зависит от того, где была записана запись. Запись может охватывать двух картографов.
При настройке HDFS он разбивает очень большие файлы на большие блоки (например, размером 128 МБ) и сохраняет три копии этих блоков на разных узлах кластера.
HDFS не знает о содержании этих файлов. Запись может быть начата в блоке a, но конец этой записи может присутствовать в блоке b.
Чтобы решить эту проблему, Hadoop использует логическое представление данных, хранящихся в файловых блоках, известных как входные разбиения. Когда клиент задания MapReduce вычисляет входные разбиения, он выясняет, где начинается первая полная запись в блоке и где заканчивается последняя запись в блоке.
Ключевой момент:
В тех случаях, когда последняя запись в блоке является неполной, разделение на входе включает информацию о местоположении для следующего блока и смещение в байтах данных, необходимых для завершения записи.
Посмотрите на диаграмму ниже.
Взгляните на эту статью и связанный с ней вопрос SE: О разделении файлов Hadoop/HDFS.
Более подробную информацию можно прочитать из документации
Каркас Map-Reduce опирается на InputFormat задания, чтобы:
- Проверьте входную спецификацию задания.
- Разделите входные файлы на логические InputSplits, каждый из которых затем назначается отдельному Mapper.
- Каждый InputSplit затем назначается отдельному Mapper для обработки. Сплит может быть кортежем.
InputSplit[] getSplits(JobConf job,int numSplits) является API, чтобы заботиться об этих вещах.
FileInputFormat, который расширяет InputFormat реализованы getSplits() метод. Взгляните на внутренности этого метода на grepcode
Я вижу это следующим образом: InputFormat отвечает за разбиение данных на логические разбиения с учетом характера данных.
Ничто не мешает ему сделать это, хотя это может добавить значительную задержку к работе - вся логика и чтение вокруг желаемых границ разделенного размера будет происходить в трекере заданий.
Простейшим форматом ввода, учитывающим запись, является TextInputFormat. Он работает следующим образом (насколько я понял из кода) - формат ввода создает разбиения по размеру независимо от строк, но всегда LineRecordReader:
а) Пропустить первую строку в разбиении (или его части), если это не первое разбиение
б) Прочитайте одну строку после границы разделения в конце (если данные доступны, значит, это не последнее разделение).
Из того, что я понял, когда FileSplit инициализируется для первого блока, вызывается конструктор по умолчанию. Поэтому значения start и length изначально равны нулю. К концу обработки первого блока, если последняя строка является неполной, тогда значение длины будет больше, чем длина разбиения, и он также будет считывать первую строку следующего блока. Из-за этого значение запуска для первого блока будет больше нуля, и при этом условии LineRecordReader пропустит первую линию второго блока. (См. Источник)
Если последняя строка первого блока завершена, то значение длины будет равно длине первого блока, а значение начала для второго блока будет равно нулю. В этом случае LineRecordReader не будет пропускать первую строку и читать второй блок с начала.
Имеет смысл?
Из исходного кода hadoop LineRecordReader.java конструктор: Я нахожу несколько комментариев:
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
Исходя из этого, я полагаю, что hadoop будет читать одну дополнительную строку для каждого разделения (в конце текущего разделения читать следующую строку в следующем разделении), и если не первый раздел, первая строка будет выброшена. так что ни одна строчка не будет потеряна и неполна
Картографы не должны общаться. Файловые блоки находятся в HDFS и может текущий маппер (RecordReader) читать блок, который имеет оставшуюся часть строки. Это происходит за кулисами.