Попытка интерполировать 2D-данные, используя scipy- просто получая массивы NaN
Я пытаюсь написать очень простой кусок кода, который будет интерполировать из набора существующих данных, чтобы создать синтетическое распределение значений.
Код, который у меня есть, выглядит примерно так:
import pandas as pd
import numpy as np
import scipy
from scipy.interpolate import griddata
import matplotlib
CRN_data=pd.read_table('disequilibrium data.dat',sep=',')
kzz=CRN_data['Kzz']
temperature=CRN_data['Temperature']
degree=CRN_data['Mean Degree']
points=np.ndarray(shape=(len(kzz),2),dtype='float')
for i in range(len(kzz)):
points[i][0]=kzz[i]
points[i][1]=temperature[i]
gridx,gridy= np.mgrid[0:1:100j,0:1:200j]
grid=griddata(points,degree,(gridx,gridy),method='cubic')
print grid
И набор данных, из которого я интерполирую, выглядит так:
Kzz,Temperature,Mean Degree,
1.00E+06,400,7.41E+18
1.00E+06,500,4.48E+23
...
1.00E+08,400,4.67E+18
1.00E+08,500,6.88E+23
1.00E+08,750,1.88E+34
...
1.00E+10,750,2.73E+33
1.00E+10,900,2.82E+37
1.00E+10,1000,1.19E+39
...
Однако, пока код выполняется, основной вывод, который я получаю,
[[ nan nan nan ..., nan nan nan]
[ nan nan nan ..., nan nan nan]
[ nan nan nan ..., nan nan nan]
...,
[ nan nan nan ..., nan nan nan]
[ nan nan nan ..., nan nan nan]
[ nan nan nan ..., nan nan nan]]
что, очевидно, не очень полезно. Это ошибка в Scipy, или (более вероятно) я делаю что-то не так?
2 ответа
Вы получаете nan значения, потому что ваши запрошенные точки содержатся в gridx а также gridy находятся за пределами выпуклой оболочки входных точек в points, Вы можете указать fill_value использовать для экстраполированных очков, но вы можете подумать о переопределении выделенных лимитов для gridx а также gridy для получения значимых результатов, таких как:
import pandas as pd
import numpy as np
from scipy.interpolate import griddata
import matplotlib.pyplot as plt
CRN_data = pd.DataFrame([
[1.00E+06,400,7.41E+18],
[1.00E+06,500,4.48E+23],
[1.00E+08,400,4.67E+18],
[1.00E+08,500,6.88E+23],
[1.00E+08,750,1.88E+34],
[1.00E+10,750,2.73E+33],
[1.00E+10,900,2.82E+37],
[1.00E+10,1000,1.19E+39]],
columns=['Kzz','Temperature','Mean Degree'])
kzz = CRN_data['Kzz']
temperature = CRN_data['Temperature']
degree = CRN_data['Mean Degree']
points = np.matrix([[kzz[i], temperature[i]] for i in range(len(kzz))])
gridx, gridy = np.mgrid[kzz.min():kzz.max():100j,temperature.min():temperature.max():200j]
grid = griddata(points, degree, (gridx, gridy), method='cubic')
Урожайность:
[[7.41000000e+18 1.35147259e+22 2.70220418e+22 ... nan
nan nan]
[ nan 1.07878728e+33 1.26216288e+33 ... nan
nan nan]
[ nan nan 1.38255505e+35 ... nan
nan nan]
...
[ nan nan nan ... 1.16569048e+39
nan nan]
[ nan nan nan ... 1.16394396e+39
1.17798560e+39 nan]
[ nan nan nan ... 1.16129655e+39
1.17564827e+39 1.19000000e+39]]
И черчение:
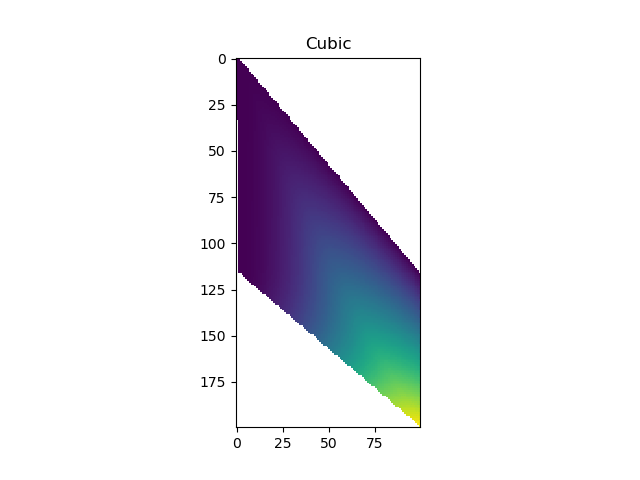
Сравните диапазоны исходных данных с вашей целевой сеткой. Из того, что я вижу, исходные диапазоны x=1e6:1e10 и y=400:1000, в то время как ваша сетка 0-1 (и x, и y). В этом случае "цель" находится за пределами исходных данных, а использование "линейного" или "кубического" даст вам NaN - попробуйте "ближайший", и Nan исчезнет.