ROW_NUMBER() в MySQL
Есть ли хороший способ в MySQL для репликации функции SQL Server ROW_NUMBER()?
Например:
SELECT
col1, col2,
ROW_NUMBER() OVER (PARTITION BY col1, col2 ORDER BY col3 DESC) AS intRow
FROM Table1
Тогда я мог бы, например, добавить условие для ограничения intRow до 1, чтобы получить один ряд с самым высоким col3 для каждого (col1, col2) пара.
29 ответов
Я хочу строку с одним самым высоким col3 для каждой пары (col1, col2).
Это групповой максимум, один из наиболее часто задаваемых вопросов SQL (поскольку кажется, что это должно быть легко, но на самом деле это не так).
Я часто пухленький для нулевого самостоятельного соединения:
SELECT t0.col3
FROM table AS t0
LEFT JOIN table AS t1 ON t0.col1=t1.col1 AND t0.col2=t1.col2 AND t1.col3>t0.col3
WHERE t1.col1 IS NULL;
"Получите строки в таблице, для которых ни одна другая строка с совпадающими столбцами col1, col2 не имеет более высокое значение col3". (Вы заметите это и большинство других решений с максимальным сгруппированным значением будет возвращать несколько строк, если несколько строк имеют одинаковые col1, col2, col3. Если это проблема, вам может потребоваться некоторая постобработка.)
В MySQL нет функции ранжирования. Самое близкое, что вы можете получить, это использовать переменную:
SELECT t.*,
@rownum := @rownum + 1 AS rank
FROM YOUR_TABLE t,
(SELECT @rownum := 0) r
так как это будет работать в моем случае? Мне нужно две переменные, по одной для каждого из col1 и col2? Col2 нужно будет как-то переустанавливать, когда col1 меняется..?
Да. Если бы это был Oracle, вы могли бы использовать функцию LEAD для достижения следующего значения. К счастью, Quassnoi охватывает логику того, что вам нужно реализовать в MySQL.
Я всегда заканчиваю тем, что следую за этим образцом. Учитывая эту таблицу:
+------+------+
| i | j |
+------+------+
| 1 | 11 |
| 1 | 12 |
| 1 | 13 |
| 2 | 21 |
| 2 | 22 |
| 2 | 23 |
| 3 | 31 |
| 3 | 32 |
| 3 | 33 |
| 4 | 14 |
+------+------+
Вы можете получить этот результат:
+------+------+------------+
| i | j | row_number |
+------+------+------------+
| 1 | 11 | 1 |
| 1 | 12 | 2 |
| 1 | 13 | 3 |
| 2 | 21 | 1 |
| 2 | 22 | 2 |
| 2 | 23 | 3 |
| 3 | 31 | 1 |
| 3 | 32 | 2 |
| 3 | 33 | 3 |
| 4 | 14 | 1 |
+------+------+------------+
Запустив этот запрос, для которого не нужно определять переменную:
SELECT a.i, a.j, count(*) as row_number FROM test a
JOIN test b ON a.i = b.i AND a.j >= b.j
GROUP BY a.i, a.j
Надеюсь, это поможет!
SELECT
@i:=@i+1 AS iterator,
t.*
FROM
tablename AS t,
(SELECT @i:=0) AS foo
От MySQL 8.0.0 и выше вы можете использовать оконные функции.
Оконные функции.
MySQL теперь поддерживает оконные функции, которые для каждой строки из запроса выполняют вычисления, используя строки, связанные с этой строкой. К ним относятся такие функции, как RANK(), LAG() и NTILE(). Кроме того, несколько существующих агрегатных функций теперь можно использовать в качестве оконных функций; например, SUM() и AVG ().
Возвращает номер текущей строки в ее разделе. Номера строк варьируются от 1 до количества строк раздела.
ORDER BY влияет на порядок, в котором строки пронумерованы. Без ORDER BY нумерация строк является неопределенной.
Демо-версия:
CREATE TABLE Table1(
id INT AUTO_INCREMENT PRIMARY KEY, col1 INT,col2 INT, col3 TEXT);
INSERT INTO Table1(col1, col2, col3)
VALUES (1,1,'a'),(1,1,'b'),(1,1,'c'),
(2,1,'x'),(2,1,'y'),(2,2,'z');
SELECT
col1, col2,col3,
ROW_NUMBER() OVER (PARTITION BY col1, col2 ORDER BY col3 DESC) AS intRow
FROM Table1;
Ознакомьтесь с этой статьей, в которой показано, как имитировать SQL ROW_NUMBER() с разделом в MySQL. Я столкнулся с тем же сценарием в реализации WordPress. Мне нужно было ROW_NUMBER (), и его там не было.
http://www.explodybits.com/2011/11/mysql-row-number/
Пример в статье использует один раздел по полю. Для разделения на дополнительные поля вы можете сделать что-то вроде этого:
SELECT @row_num := IF(@prev_value=concat_ws('',t.col1,t.col2),@row_num+1,1) AS RowNumber
,t.col1
,t.col2
,t.Col3
,t.col4
,@prev_value := concat_ws('',t.col1,t.col2)
FROM table1 t,
(SELECT @row_num := 1) x,
(SELECT @prev_value := '') y
ORDER BY t.col1,t.col2,t.col3,t.col4
Использование concat_ws обрабатывает нуль. Я проверил это на 3 полях, используя int, date и varchar. Надеюсь это поможет. Проверьте статью, поскольку она разбивает этот запрос и объясняет его.
Я также проголосовал бы за решение Мости Мостачо с незначительными изменениями в его коде запроса:
SELECT a.i, a.j, (
SELECT count(*) from test b where a.j >= b.j AND a.i = b.i
) AS row_number FROM test a
Который даст тот же результат:
+------+------+------------+
| i | j | row_number |
+------+------+------------+
| 1 | 11 | 1 |
| 1 | 12 | 2 |
| 1 | 13 | 3 |
| 2 | 21 | 1 |
| 2 | 22 | 2 |
| 2 | 23 | 3 |
| 3 | 31 | 1 |
| 3 | 32 | 2 |
| 3 | 33 | 3 |
| 4 | 14 | 1 |
+------+------+------------+
для стола:
+------+------+
| i | j |
+------+------+
| 1 | 11 |
| 1 | 12 |
| 1 | 13 |
| 2 | 21 |
| 2 | 22 |
| 2 | 23 |
| 3 | 31 |
| 3 | 32 |
| 3 | 33 |
| 4 | 14 |
+------+------+
С той лишь разницей, что запрос не использует JOIN и GROUP BY, полагаясь на вложенный выбор.
Я бы определил функцию:
delimiter $$
DROP FUNCTION IF EXISTS `getFakeId`$$
CREATE FUNCTION `getFakeId`() RETURNS int(11)
DETERMINISTIC
begin
return if(@fakeId, @fakeId:=@fakeId+1, @fakeId:=1);
end$$
тогда я мог бы сделать:
select getFakeId() as id, t.* from table t, (select @fakeId:=0) as t2;
Теперь у вас нет подзапроса, который вы не можете иметь в представлениях.
Запрос для row_number в MySQL
set @row_number=0;
select (@row_number := @row_number +1) as num,id,name from sbs
Там нет функции, как rownum, row_num() в MySQL, но обходной путь, как показано ниже:
select
@s:=@s+1 serial_no,
tbl.*
from my_table tbl, (select @s:=0) as s;
Ответы здесь, которые используют переменные в запросе, в основном / все, кажется, игнорируют тот факт, что документация говорит (перефразировать):
Не полагайтесь на элементы в списке SELECT, оцениваемые по порядку сверху вниз. Не назначайте переменные в одном элементе SELECT и не используйте их в другом
Таким образом, есть риск, что они будут выдавать неправильный ответ, потому что они обычно делают
select
(row number variable that uses partition variable),
(assign partition variable)
Если они когда-либо оценены снизу вверх, номер строки перестанет работать (без разделов)
Поэтому нам нужно использовать что-то с гарантированным порядком исполнения. Введите СЛУЧАЙ КОГДА:
SELECT
t.*,
@r := CASE
WHEN col = @prevcol THEN @r + 1
WHEN (@prevcol := col) = null THEN null
ELSE 1 END AS rn
FROM
t,
(SELECT @r := 0, @prevcol := null) x
ORDER BY col
Как и в общих чертах, порядок назначения prevcol важен - его нужно сравнить со значением текущей строки, прежде чем мы присвоим ему значение из текущей строки (в противном случае это будет значение столбца текущей строки, а не значение столбца предыдущей строки),
Вот как это сочетается:
Первый КОГДА оценивается. Если col этой строки совпадает с col предыдущей строки, то @r увеличивается и возвращается из CASE. Эти возвращаемые светодиодные значения хранятся в @r. Особенностью MySQL является то, что присваивание возвращает новое значение того, что назначено в @r, в строки результатов.
Для первой строки в наборе результатов @prevcol имеет значение null (в подзапросе оно инициализируется значением null), поэтому этот предикат имеет значение false. Этот первый предикат также возвращает false при каждом изменении col (текущая строка отличается от предыдущей строки). Это заставляет второй КОГДА быть оцененным.
Второй предикат WHEN всегда ложен и существует исключительно для назначения нового значения @prevcol. Поскольку col этой строки отличается от col предыдущей строки (мы знаем это потому, что если бы это было то же самое, использовался бы первый WHEN), мы должны присвоить новое значение, чтобы сохранить его для тестирования в следующий раз. Поскольку присваивание выполняется, а затем результат присваивания сравнивается с нулем, а все, что приравнивается к нулю, является ложным, этот предикат всегда ложен. Но, по крайней мере, оценив его, он сохранил значение col из этой строки, чтобы его можно было сравнить со значением col следующей строки.
Поскольку второе WHEN имеет значение false, это означает, что в ситуациях, когда столбец, который мы разделяем (col), изменился, это ELSE, который дает новое значение для @r, перезапуская нумерацию с 1
Мы это попадаем в ситуацию, когда это:
SELECT
t.*,
ROW_NUMBER() OVER(PARTITION BY pcol1, pcol2, ... pcolX ORDER BY ocol1, ocol2, ... ocolX) rn
FROM
t
Имеет общую форму:
SELECT
t.*,
@r := CASE
WHEN col1 = @pcol1 AND col2 = @pcol2 AND ... AND colX = @pcolX THEN @r + 1
WHEN (@pcol1 := pcol1) = null OR (@pcol2 := col2) = null OR ... OR (@pcolX := colX) = null THEN THEN null
ELSE 1
END AS rn
FROM
t,
(SELECT @r := 0, @pcol1 := null, @pcol2 := null, ..., @pcolX := null) x
ORDER BY pcol1, pcol2, ..., pcolX, ocol1, ocol2, ..., ocolX
Примечания:
P в pcol означает "раздел", o в ocol означает "порядок" - в общем виде я убрал "prev" из имени переменной, чтобы уменьшить визуальный беспорядок
Скобки вокруг
(@pcolX := colX) = nullважные. Без них вы назначите ноль для @pcolX, и все перестанет работатьЭто компромисс, что результирующий набор должен быть упорядочен также по столбцам разделов, чтобы сравнение предыдущего столбца сработало. Таким образом, вы не можете упорядочить свое числовое число в соответствии с одним столбцом, но ваш набор результатов должен быть упорядочен в другом. Возможно, вы сможете решить эту проблему с помощью подзапросов, но я считаю, что в документах также указано, что упорядочение подзапросов может игнорироваться, если не используется LIMIT, и это может повлиять спектакль
Я не вдавался в подробности после тестирования того, что метод работает, но если есть риск, что предикаты во втором случае WHEN будут оптимизированы (что-либо по сравнению с null равно null/false, так зачем беспокоиться о выполнении назначения) и не выполняется также останавливается. По моему опыту, этого не происходит, но я с удовольствием приму комментарии и предложу решение, если оно может произойти.
Может быть целесообразно привести нулевые значения, которые создают @pcolX, к фактическим типам ваших столбцов в подзапросе, который создает переменные @pcolX, а именно:
select @pcol1 := CAST(null as INT), @pcol2 := CAST(null as DATE)
Решение, которое я нашел, чтобы работать лучше всего, использовало подобный подзапрос:
SELECT
col1, col2,
(
SELECT COUNT(*)
FROM Table1
WHERE col1 = t1.col1
AND col2 = t1.col2
AND col3 > t1.col3
) AS intRow
FROM Table1 t1
Столбцы PARTITION BY просто сравниваются с '=' и разделяются символом AND. Столбцы ORDER BY будут сравниваться с '<' или '>' и разделяться OR.
Я нашел, что это очень гибко, даже если это немного дорого.
Функциональность номера не может быть воспроизведена. Вы можете получить ожидаемые результаты, но, скорее всего, на каком-то этапе вы будете разочарованы. Вот что говорит документация mysql:
Для других операторов, таких как SELECT, вы можете получить ожидаемые результаты, но это не гарантируется. В следующем утверждении вы можете подумать, что MySQL сначала оценит @a, а затем выполнит присваивание второе: SELECT @a, @a:=@a+1, ...; Однако порядок вычисления для выражений с участием пользовательских переменных не определен.
С уважением, Георгий.
MariaDB 10.2 реализует "оконные функции", включая RANK(), ROW_NUMBER() и ряд других вещей:
https://mariadb.com/kb/en/mariadb/window-functions/
Основываясь на выступлении в Percona Live в этом месяце, они достаточно хорошо оптимизированы.
Синтаксис идентичен коду в вопросе.
MySQL поддерживает ROW_NUMBER() начиная с версии 8.0+.
Если вы используете MySQL 8.0 или новее, проверьте это функцией ROW_NUMBER(). В противном случае вы должны эмулировать функцию ROW_NUMBER().
Row_number() - это функция ранжирования, которая возвращает порядковый номер строки, начиная с 1 для первой строки.
для старой версии,
SELECT t.*,
@rowid := @rowid + 1 AS ROWID
FROM TABLE t,
(SELECT @rowid := 0) dummy;
Я не вижу простого ответа, охватывающего часть "PARTITION BY", так что вот мой:
SELECT
*
FROM (
select
CASE WHEN @partitionBy_1 = l THEN @row_number:=@row_number+1 ELSE @row_number:=1 END AS i
, @partitionBy_1:=l AS p
, t.*
from (
select @row_number:=0,@partitionBy_1:=null
) as x
cross join (
select 1 as n, 'a' as l
union all
select 1 as n, 'b' as l
union all
select 2 as n, 'b' as l
union all
select 2 as n, 'a' as l
union all
select 3 as n, 'a' as l
union all
select 3 as n, 'b' as l
) as t
ORDER BY l, n
) AS X
where i > 1
- Предложение ORDER BY должно отражать ваши потребности в ROW_NUMBER. Таким образом, уже есть явное ограничение: вы не можете иметь несколько "эмуляций" ROW_NUMBER этой формы одновременно.
- Порядок "вычисляемого столбца" имеет значение. Если у вас есть MySQL вычислить эти столбцы в другом порядке, это может не сработать.
В этом простом примере я поставил только одну, но вы можете иметь несколько частей "PARTITION BY"
CASE WHEN @partitionBy_1 = part1 AND @partitionBy_2 = part2 [...] THEN @row_number:=@row_number+1 ELSE @row_number:=1 END AS i , @partitionBy_1:=part1 AS P1 , @partitionBy_2:=part2 AS P2 [...] FROM ( SELECT @row_number:=0,@partitionBy_1:=null,@partitionBy_2:=null[...] ) as x
Решения с перекрестным соединением и запятой не будут работать, если в вашем запросе есть
GROUP BYутверждение. Для таких случаев вы можете использовать подзапрос:
SELECT (@row_number := @row_number + 1) AS rowNumber, res.*
FROM
(
SELECT SUM(r.amount)
FROM Results r
WHERE username = 1
GROUP BY r.amount
) res
CROSS JOIN (SELECT @row_number := 0) AS dummy
Я думаю, вы можете использовать здесь функцию DENSE_RANK(). Пример:
select `score`, DENSE_RANK() OVER( ORDER BY score desc ) as `rank` from Scores;
https://www.mysqltutorial.org/mysql-window-functions/mysql-dense_rank-function/
Это также может быть решением:
SET @row_number = 0;
SELECT
(@row_number:=@row_number + 1) AS num, firstName, lastName
FROM
employees
Это позволяет реализовать те же функции, что и ROW_NUMBER() AND PARTITION BY в MySQL.
SELECT @row_num := IF(@prev_value=GENDER,@row_num+1,1) AS RowNumber
FirstName,
Age,
Gender,
@prev_value := GENDER
FROM Person,
(SELECT @row_num := 1) x,
(SELECT @prev_value := '') y
ORDER BY Gender, Age DESC
Немного поздно, но также может помочь тому, кто ищет ответы...
Между row /row_number example - рекурсивный запрос, который можно использовать в любом SQL:
WITH data(row_num, some_val) AS
(
SELECT 1 row_num, 1 some_val FROM any_table --dual in Oracle
UNION ALL
SELECT row_num+1, some_val+row_num FROM data WHERE row_num < 20 -- any number
)
SELECT * FROM data
WHERE row_num BETWEEN 5 AND 10
/
ROW_NUM SOME_VAL
-------------------
5 11
6 16
7 22
8 29
9 37
10 46
Также немного поздно, но сегодня у меня возникла такая же потребность, поэтому я выполнил поиск в Google, и, наконец, простой общий подход был найден здесь в статье Пинала Дейва http://blog.sqlauthority.com/2014/03/09/mysql-reset-row -количество-для-каждого-группового раздела за строкой-числом /
Я хотел сосредоточиться на первоначальном вопросе Пола (это была и моя проблема), поэтому я суммирую свое решение в качестве рабочего примера.
Поскольку мы хотим разбить на два столбца, я бы создал переменную SET во время итерации, чтобы определить, была ли запущена новая группа.
SELECT col1, col2, col3 FROM (
SELECT col1, col2, col3,
@n := CASE WHEN @v = MAKE_SET(3, col1, col2)
THEN @n + 1 -- if we are in the same group
ELSE 1 -- next group starts so we reset the counter
END AS row_number,
@v := MAKE_SET(3, col1, col2) -- we store the current value for next iteration
FROM Table1, (SELECT @n := 0, @v := NULL) r -- helper table for iteration with startup values
ORDER BY col1, col2, col3 DESC -- because we want the row with maximum value
) x WHERE row_number = 1 -- and here we select exactly the wanted row from each group
3 означает в первом параметре MAKE_SET, что я хочу оба значения в SET (3=1|2). Конечно, если у нас нет двух или более столбцов, составляющих группы, мы можем исключить операцию MAKE_SET. Конструкция точно такая же. Это работает для меня как требуется. Большое спасибо Пиналу Дейву за его наглядную демонстрацию.
Все еще поддерживая MySQL 5.7.38 в 2023 году и нуждаясь в ROW_NUMBER(), я сделал что-то вроде этого:
drop temporary table t1
create temporary table t1 (
USER_ID VARCHAR(50),
PRIORITY INT
)
insert into t1 (USER_ID, PRIORITY )
values
('qqq',300),
('qqq',572),
('qqq',574),
('qqq',630),
('qqq',640),
('qqq',650),
('yyy',300),
('yyy',574),
('yyy',574),
('yyy',630),
('yyy',640),
('yyy',650)
SELECT *,
@row_number := IF(@prev_userid = USER_ID, @row_number + 1, 1) AS ROWNUM,
@prev_userid := USER_ID
FROM t1
CROSS JOIN (SELECT @row_number := 0, @prev_userid := '') AS vars
ORDER BY USER_ID, PRIORITY
Полученные результаты:
|USER_ID|PRIORITY|@row_number := 0|@prev_userid := ''|ROWNUM|@prev_userid := USER_ID|
|-------|--------|----------------|------------------|------|-----------------------|
|qqq |300 |0 | |1 |qqq |
|qqq |572 |0 | |2 |qqq |
|qqq |574 |0 | |3 |qqq |
|qqq |630 |0 | |4 |qqq |
|qqq |640 |0 | |5 |qqq |
|qqq |650 |0 | |6 |qqq |
|yyy |300 |0 | |1 |yyy |
|yyy |574 |0 | |2 |yyy |
|yyy |574 |0 | |3 |yyy |
|yyy |630 |0 | |4 |yyy |
|yyy |640 |0 | |5 |yyy |
|yyy |650 |0 | |6 |yyy |
Это не самое надежное решение, но если вы просто хотите создать разделенный ранг для поля с несколькими разными значениями, возможно, будет нетрудно использовать какой-то случай, когда логика с таким количеством переменных, сколько вам нужно.
Что-то вроде этого у меня работало раньше:
SELECT t.*,
CASE WHEN <partition_field> = @rownum1 := @rownum1 + 1
WHEN <partition_field> = @rownum2 := @rownum2 + 1
...
END AS rank
FROM YOUR_TABLE t,
(SELECT @rownum1 := 0) r1, (SELECT @rownum2 := 0) r2
ORDER BY <rank_order_by_field>
;
Надеюсь, что это имеет смысл / поможет!
MySQL начиная с версии 8 поддерживает ROW_NUMBER(), поэтому вы можете использовать приведенный ниже запрос так же, как в SQL Server.
SELECT
col1, col2,
ROW_NUMBER() OVER (PARTITION BY col1, col2 ORDER BY col3 DESC) AS intRow
FROM Table1
Я также тестировал его в Maria DB 10.4.21. Там тоже работает.
Эта работа идеально подходит для меня, чтобы создать RowNumber, когда у нас есть более одного столбца. В этом случае два столбца.
SELECT @row_num := IF(@prev_value= concat(`Fk_Business_Unit_Code`,`NetIQ_Job_Code`), @row_num+1, 1) AS RowNumber,
`Fk_Business_Unit_Code`,
`NetIQ_Job_Code`,
`Supervisor_Name`,
@prev_value := concat(`Fk_Business_Unit_Code`,`NetIQ_Job_Code`)
FROM (SELECT DISTINCT `Fk_Business_Unit_Code`,`NetIQ_Job_Code`,`Supervisor_Name`
FROM Employee
ORDER BY `Fk_Business_Unit_Code`, `NetIQ_Job_Code`, `Supervisor_Name` DESC) z,
(SELECT @row_num := 1) x,
(SELECT @prev_value := '') y
ORDER BY `Fk_Business_Unit_Code`, `NetIQ_Job_Code`,`Supervisor_Name` DESC
для разделения по другому столбцу один из способов описан @abcdn. Однако у него низкая производительность. Я предлагаю использовать этот код, который не требует соединения таблицы с самой собой: Учтите ту же таблицу.
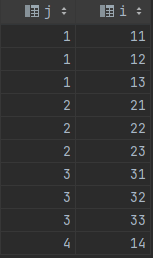
вы можете получить разбиение следующим образом:
set @row_num := 0;
set @j:= 0;
select IF(j= @j, @row_num := @row_num + 1, @row_num := 1) as row_num,
i, @j:= j as j
from tbl fh
order by j, i;
результат будет таким:
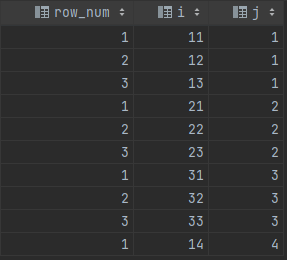
Преимущество в том, что нам не нужно соединять таблицу с самой собой
set @i = 1;
INSERT INTO ARG_VALUE_LOOKUP(ARG_VALUE_LOOKUP_ID,ARGUMENT_NAME,VALUE,DESCRIPTION,UPDATE_TIMESTAMP,UPDATE_USER,VER_NBR,OBJ_ID)
select @i:= @i+1 as ARG_VALUE_LOOKUP_ID,ARGUMENT_NAME,VALUE,DESCRIPTION,CURRENT_TIMESTAMP,'admin',1,UUID()
FROM TEMP_ARG_VALUE_LOOKUP
order by ARGUMENT_NAME;
SELECT
col1, col2,
count(*) as intRow
FROM Table1
GROUP BY col1,col2
ORDER BY col3 desc