TensorFlow: Как встраивать последовательности с плавающей точкой в векторы фиксированного размера?
Я ищу методы для встраивания последовательностей переменной длины со значениями с плавающей точкой в векторы фиксированного размера. Входные форматы следующие:
[f1,f2,f3,f4]->[f1,f2,f3,f4]->[f1,f2,f3,f4]-> ... -> [f1,f2,f3,f4]
[f1,f2,f3,f4]->[f1,f2,f3,f4]->[f1,f2,f3,f4]->[f1,f2,f3,f4]-> ... -> [f1,f2,f3,f4]
...
[f1,f2,f3,f4]-> ... -> ->[f1,f2,f3,f4]
Каждая строка является последовательностью переменной длины, с максимальной длиной 60. Каждая единица в одной последовательности представляет собой кортеж из 4 значений с плавающей запятой. Я уже поставил нули, чтобы заполнить все последовательности одинаковой длины.
Следующая архитектура, кажется, решает мою проблему, если я использую выходные данные так же, как входные данные, мне нужен вектор мысли в центре как вложение для последовательностей. 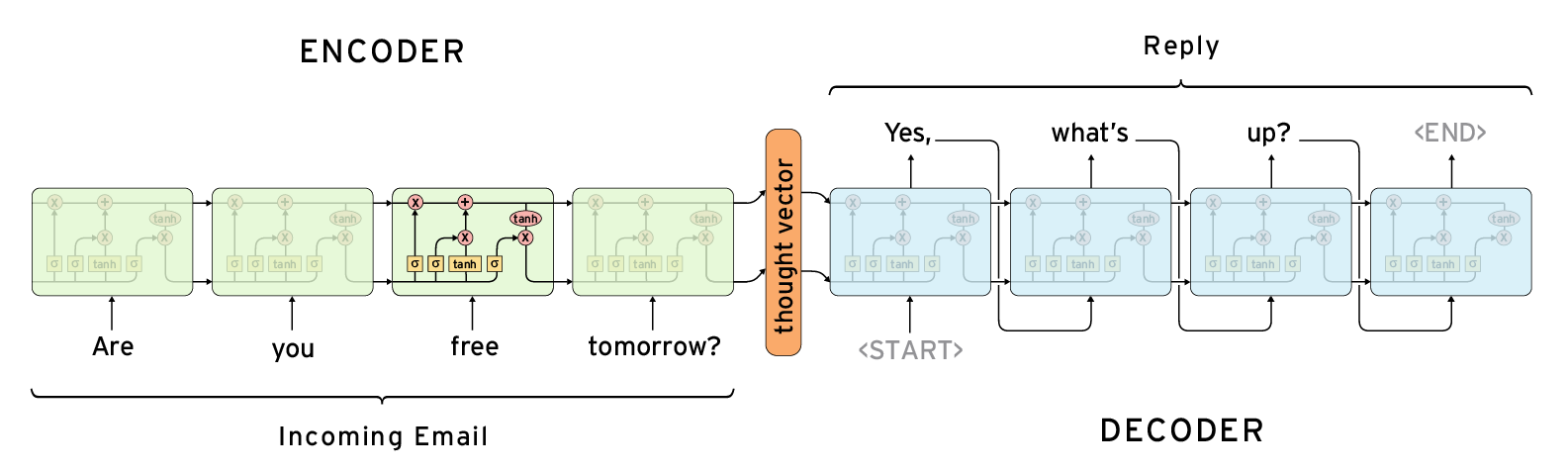
В тензорном потоке я нашел два метода-кандидата https://www.tensorflow.org/api_docs/python/tf/contrib/legacy_seq2seq/basic_rnn_seq2seq и https://www.tensorflow.org/api_docs/python/tf/contrib/legacy_seq2seq/embedding_rnn_seq2seq.
Тем не менее, эти методы буксировки, кажется, используются для решения проблемы НЛП, и ввод должен быть дискретным значением для слов.
Итак, есть ли другие функции для решения моих проблем?
3 ответа
Я нашел решение своей проблемы, используя следующую архитектуру,
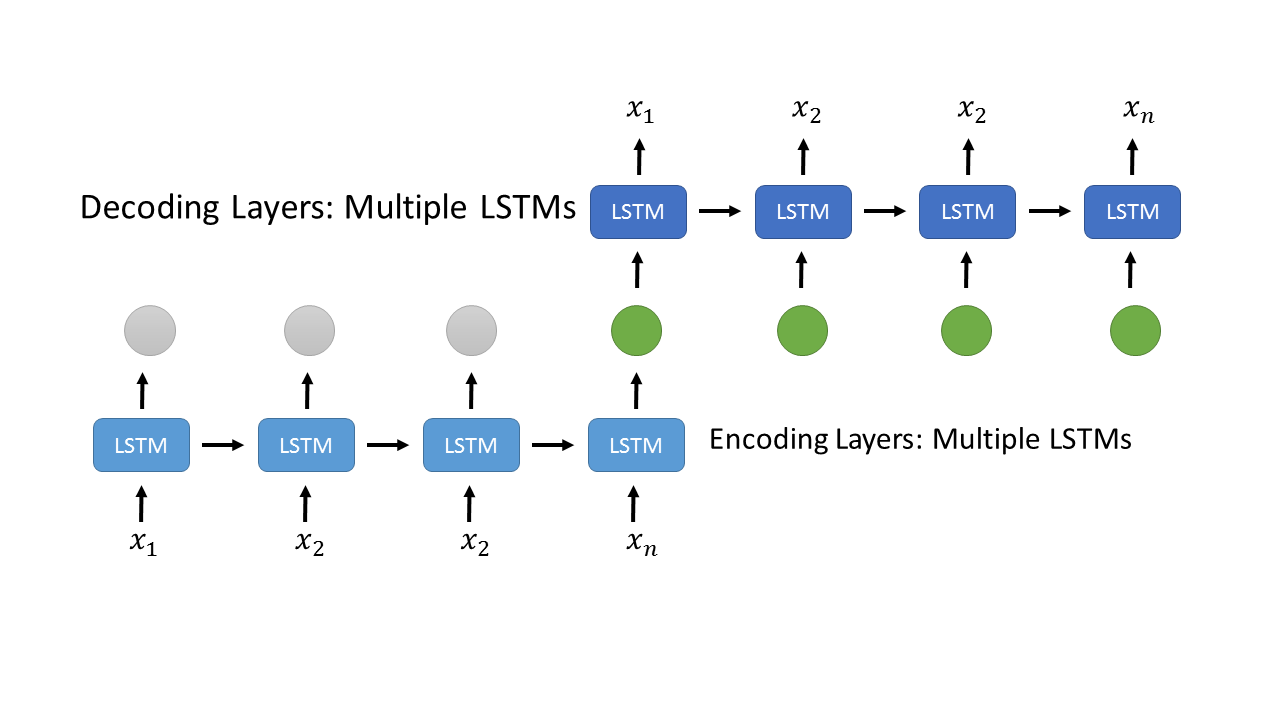 ,
,
Уровень LSTM ниже кодирует ряды x1,x2,...,xn. Последний вывод, зеленый, дублируется на то же количество, что и вход для декодирования слоев LSTM выше. Код тензорного потока выглядит следующим образом
series_input = tf.placeholder(tf.float32, [None, conf.max_series, conf.series_feature_num])
print("Encode input Shape", series_input.get_shape())
# encoding layer
encode_cell = tf.contrib.rnn.MultiRNNCell(
[tf.contrib.rnn.BasicLSTMCell(conf.rnn_hidden_num, reuse=False) for _ in range(conf.rnn_layer_num)]
)
encode_output, _ = tf.nn.dynamic_rnn(encode_cell, series_input, dtype=tf.float32, scope='encode')
print("Encode output Shape", encode_output.get_shape())
# last output
encode_output = tf.transpose(encode_output, [1, 0, 2])
last = tf.gather(encode_output, int(encode_output.get_shape()[0]) - 1)
# duplite the last output of the encoding layer
decoder_input = tf.stack([last for _ in range(conf.max_series)], axis=1)
print("Decoder input shape", decoder_input.get_shape())
# decoding layer
decode_cell = tf.contrib.rnn.MultiRNNCell(
[tf.contrib.rnn.BasicLSTMCell(conf.series_feature_num, reuse=False) for _ in range(conf.rnn_layer_num)]
)
decode_output, _ = tf.nn.dynamic_rnn(decode_cell, decoder_input, dtype=tf.float32, scope='decode')
print("Decode output", decode_output.get_shape())
# Loss Function
loss = tf.losses.mean_squared_error(labels=series_input, predictions=decode_output)
print("Loss", loss)
Все, что вам нужно, это только RNN, а не модель seq2seq, поскольку seq2seq поставляется с дополнительным декодером, который в вашем случае не нужен.
Пример кода:
import numpy as np
import tensorflow as tf
from tensorflow.contrib import rnn
input_size = 4
max_length = 60
hidden_size=64
output_size = 4
x = tf.placeholder(tf.float32, shape=[None, max_length, input_size], name='x')
seqlen = tf.placeholder(tf.int64, shape=[None], name='seqlen')
lstm_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0)
outputs, states = tf.nn.dynamic_rnn(cell=lstm_cell, inputs=x, sequence_length=seqlen, dtype=tf.float32)
encoded_states = states[-1]
W = tf.get_variable(
name='W',
shape=[hidden_size, output_size],
dtype=tf.float32,
initializer=tf.random_normal_initializer())
b = tf.get_variable(
name='b',
shape=[output_size],
dtype=tf.float32,
initializer=tf.random_normal_initializer())
z = tf.matmul(encoded_states, W) + b
results = tf.sigmoid(z)
###########################
## cost computing and training components goes here
# e.g.
# targets = tf.placeholder(tf.float32, shape=[None, input_size], name='targets')
# cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=targets, logits=z))
# optimizer = tf.train.AdamOptimizer(learning_rate=0.1).minimize(cost)
###############################
init = tf.global_variables_initializer()
batch_size = 4
data_in = np.zeros((batch_size, max_length, input_size), dtype='float32')
data_in[0, :4, :] = np.random.rand(4, input_size)
data_in[1, :6, :] = np.random.rand(6, input_size)
data_in[2, :20, :] = np.random.rand(20, input_size)
data_in[3, :, :] = np.random.rand(60, input_size)
data_len = np.asarray([4, 6, 20, 60], dtype='int64')
with tf.Session() as sess:
sess.run(init)
#########################
# training process goes here
#########################
res = sess.run(results,
feed_dict={
x: data_in,
seqlen: data_len})
print(res)
Для кодирования последовательности в вектор фиксированной длины вы обычно используете рекуррентные нейронные сети (RNN) или сверточные нейронные сети (CNN).
Если вы используете рекуррентную нейронную сеть, вы можете использовать вывод на последнем шаге по времени (последний элемент в вашей последовательности). Это соответствует вектору мысли в вашем вопросе. Посмотрите на tf.dynamic_rnn. dynamic_rnn требует от вас указать тип ячейки RNN, которую вы хотите использовать. tf.contrib.rnn.LSTMCell а также tf.contrib.rnn.GRUCell наиболее распространены.
Если вы хотите использовать CNN, вам нужно использовать одномерные свертки. Для построения CNN вам нужны tf.layers.conv1d и tf.layers.max_pooling1d