Пример лабиринта Q-Learning от PyBrains. Государственные ценности и глобальная политика
Я пробую пример лабиринта PyBrains
мои настройки:
envmatrix = [[...]]
env = Maze(envmatrix, (1, 8))
task = MDPMazeTask(env)
table = ActionValueTable(states_nr, actions_nr)
table.initialize(0.)
learner = Q()
agent = LearningAgent(table, learner)
experiment = Experiment(task, agent)
for i in range(1000):
experiment.doInteractions(N)
agent.learn()
agent.reset()
Теперь я не уверен в результатах, которые я получаю 
Правый нижний угол (1, 8) - поглощающее состояние
Я поместил дополнительное состояние наказания (1, 7) в mdp.py:
def getReward(self):
""" compute and return the current reward (i.e. corresponding to the last action performed) """
if self.env.goal == self.env.perseus:
self.env.reset()
reward = 1
elif self.env.perseus == (1,7):
reward = -1000
else:
reward = 0
return reward
Теперь я не понимаю, как после 1000 прогонов и 200 взаимодействий во время каждого прогона агент считает, что мое состояние наказания - хорошее состояние (вы можете видеть, что квадрат белый)
Я хотел бы видеть значения для каждого государства и политики после финального запуска. Как я могу это сделать? Я обнаружил, что эта линия table.params.reshape(81,4).max(1).reshape(9,9) возвращает некоторые значения, но я не уверен, соответствуют ли они значениям функции значения
1 ответ
Теперь я добавил еще одно ограничение - заставил агента всегда начинать с одной и той же позиции: (1, 1), добавив self.initPos = [(1, 1)] в maze.py и теперь я получаю это поведение после 1000 прогонов с каждым прогоном, имеющим 200 взаимодействий:
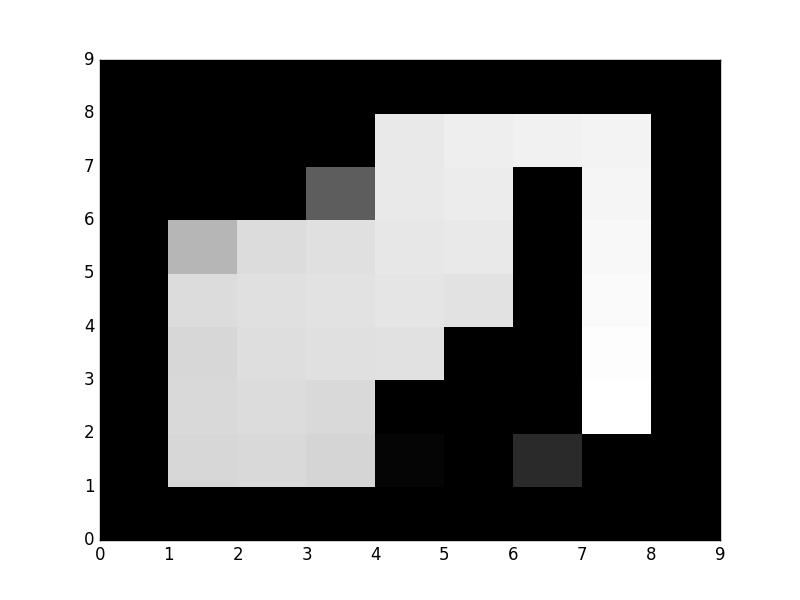
Какой вид имеет смысл сейчас - робот пытается обойти стену с другой стороны, избегая состояния (1, 7)
Итак, я получал странные результаты, потому что агент начинал со случайных позиций, что также включало состояние наказания.
РЕДАКТИРОВАТЬ:
Другое дело, что если желательно порождать агента случайным образом, то убедитесь, что он не порожден в наказуемом состоянии.
def _freePos(self):
""" produce a list of the free positions. """
res = []
for i, row in enumerate(self.mazeTable):
for j, p in enumerate(row):
if p == False:
if self.punishing_states != None:
if (i, j) not in self.punishing_states:
res.append((i, j))
else:
res.append((i, j))
return res
Кроме того, кажется, что table.params.reshape(81,4).max(1).reshape(9,9) возвращает значение для каждого состояния из функции значения