Как объединить несколько страниц PDF на одной странице
У меня есть PDF с 4 страницами. Я хочу создать еще один PDF-файл, в котором страницы располагаются одна за другой (вертикальное положение) на одной странице. Какой инструмент командной строки можно использовать для этого?
5 ответов
Есть несколько способов выполнить эту задачу, один проще, другой сложнее
ЛЕГКО: МУЛЬТИВАЛЕНТ. ПУТЬ
Multivalent.jar - это потрясающее бесплатное программное обеспечение, способное выполнять множество полезных задач в формате PDF.
Вы можете скачать по одной из этих ссылок (сборка multivalent.jar 2009, доступная на sourceforge, больше не имеет инструментов pdf внутри)
- http://minhateca.com.br/cixey/Documentos/Multivalent,584888318.jar(executabl
вам нужно знать ширину и высоту вашего pdf (в Linux вы можете использовать pdfinfo)
предполагая, что ваш многостраничный PDF-файл имеет размер ISO A4 (21x29,7 см), введите:
java -cp path..to / Multivalent.jar tool.pdf.Impose -dim 4x1-paper 84x29.7cm input.pdf
это получающаяся страница, составленная из 4 последовательных страниц, сшитых рядом друг с другом:

- результирующий файл PDF http://ge.tt/98Kv4ce/v/0
экспликация:
-dim 4x1 означает количество столбцов для строк
-paper 84x29.7cm означает размер бумаги вашего окончательного наложенного документа, содержащего 4 страницы, соединенные рядом. очевидно, так как в вашем последнем файле PDF у вас будет 4 столбца и только одна строка, вам нужно умножить документ на 4 на 21 см
Мультивалентность может принимать в качестве единственного ввода также дюймы (-paper 33.4x11.68in) или постскриптумные точки (-paper 2380x841pt)
-----------------
Тяжелее:латексный путь:
4_pdf_pages_appended_side_by_side
Несколько лет назад Питер Флинн в comp.text.pdf предложил для аналогичной задачи способ добавления страниц PDFрядом друг с другом с помощью LateX. Если вы LaTeXian, вы можете действовать следующим образом:
так как вам нужно добавить бок о бок четыре страницы вашегомногостраничного pdf, вы напишете латексную преамбулу, создав новый документ, подобный этому:
при условии, что ваш PDF-документ имеет имя input.pdf и его размер - ISO A4, и у вас есть этот многостраничный pdf в вашей рабочей папке, у вас будет
\documentclass[a4paper]{article}
\usepackage[margin=0mm,nohead,nofoot]{geometry}
\usepackage{pdfpages}
\pagestyle{empty}
\parindent0pt
\begin{document}
\includepdfmerge[nup=1x4,landscape]{input.pdf,1,input.pdf,2,input.pdf,3,input.pdf,4}
\end{document}
Если вы используете Unix-подобную операционную систему, существует pdfjam, который объединяет латексный бэкэнд с простой командой:
pdfjam --nup 1x4,landscape input.pdf
Я только что сделал это с CoherentPDF
cpdf -impose-xy "0 4" in.pdf -o out.pdf
Если количество страниц неизвестно, установите что-то большее, например
cpdf -impose-xy "0 99" in.pdf -o out.pdf
Значение x для -impose-xy может быть установлено равным нулю, чтобы указать бесконечную ширину страницы; значение y для указания бесконечно длинного. В обоих случаях предполагается, что страницы во входном файле (*) имеют одинаковые размеры.
Дополнительные параметры можно изучить в отличном руководстве:
https://www.coherentpdf.com/cpdfmanual/cpdfmanualch9.html#x13-860009.2
(*) В моем случае сначала мне пришлось масштабировать последнюю страницу, чтобы она соответствовала размерам других страниц, а затем наложение.
cpdf \
-scale-to-fit "768pt 1024pt" -top 0 in.pdf end \
AND \
-impose-xy "99 0" in.pdf \
-o out.pdf
У меня недавно была аналогичная проблема. Мне нужно было разработать решение для предварительной обработки PDF-файла, чтобы лучше идентифицировать таблицы с помощьюупаковка. Вот пошаговое решение моей проблемы:
- Удалить верхний и нижний колонтитулы со всех страниц;
- Разделите PDF на файлы, содержащие по одной странице в каждом;
- Обрезать одну страницу из файлов в соответствии с ее ограничивающей рамкой;
- Объединить
nфайлы в 1 единый PDF, содержащий 1 страницу, сохраняя порядок; - Чтение и предварительная обработка таблиц из текстового PDF-файла с использованием файлов .
В моем случае шаг 3 процесса может генерировать файлы с разными размерами. При использовании
pdfjamУ меня были проблемы с выравниванием страниц на шаге 4 , даже при использовании команды--pagetemplateпараметр. Для меня вертикальное выравнивание было худшим.
К счастью, мне удалось решить эту проблему выравнивания страниц с помощью подхода, основанного на LaTeX. Вот базовый исходный код, который я использовал — поместите все файлы в один и тот же каталог.
Ответ на вопрос этого поста находится в разделе «Сценарий оболочки», начиная со строки «Объединение n страниц в одну с помощью LaTeX…».
Требования:
Я протестировал это решение, используя дистрибутив Debian Linux. Для работы в Windows вы можете установить Debian , например, через WSL. Предполагая, что вы используете Debian или Ubuntu, выполните следующие команды:
sudo apt update
sudo apt install texlive-extra-utils texlive-latex-extra poppler-utils ghostscript default-jdk -y
В результате предварительной обработки PDF итоговый файл может иметь уменьшенные размеры, особенно по ширине. Несмотря на то, что он векторизован, уменьшение размера PDF отрицательно сказывается на качестве извлечения таблиц с помощью
tabula-pyинструмент.
Чтобы увеличить размер конечного PDF-файла, сохранив соотношение сторон, мы можем использоватьcpdfинструмент. В случае использования дистрибутива Linux просто скопируйте двоичный файл в тот же каталог, что и сценарий оболочки. Затем дайте бинарному файлу разрешение на выполнение:
chmod +x cpdf
Латекс-шаблон:
Создайте файл с именем
pdf_merge_template.texсо следующим содержанием:
\documentclass[dvipdfmx]{article}
\usepackage[margin=0in]{geometry}
\usepackage{pdfpages}
\begin{document}
\centering<PDF-PAGES>
\end{document}
Сценарий оболочки:
Создайте файл с именем
pdf-preprocessing.shсо следующим содержанием:
#!/bin/bash
# References
# ----------
# [PDF preprocessing] https://stackoverflow.com/a/71802078/16109419
PDF_MERGE_TEMPLATE_FILENAME="pdf_merge_template.tex"
PDF_MERGE_TEMPLATE_PAGES_MACRO="<PDF-PAGES>"
CPDF_FILENAME="cpdf" # Binary file of "Coherent PDF" tool.
INPUT_FILEPATH=$1
OUTPUT_FILEPATH=$2
if [ "$#" -eq "2" ]; then
echo "Starting PDF preprocessing..."
else
echo "ERROR: Wrong arguments ('INPUT_FILEPATH', 'OUTPUT_FILEPATH')!"
exit
fi
TEMP_DIR_PATH=$(mktemp -d)
echo "Setting up working directory: ${TEMP_DIR_PATH}"
THIS_FILENAME=$(readlink -f "$0")
THIS_DIR=$(dirname "$THIS_FILENAME")
PDF_MERGE_TEMPLATE_PATH="${THIS_DIR}/${PDF_MERGE_TEMPLATE_FILENAME}"
CPDF_BIN_PATH="${THIS_DIR}/${CPDF_FILENAME}"
echo "Removing header and footer from all pages..."
# Removing header and footer from PDF pages based on margin settings (e.g., '5 -75 5 -25'):
pdfcrop --margins '5 -75 5 -25' "${INPUT_FILEPATH}" "${TEMP_DIR_PATH}/input-tmp.pdf"
# Deleting the textual content of the cut parts:
pdftocairo "${TEMP_DIR_PATH}/input-tmp.pdf" "${TEMP_DIR_PATH}/input.pdf" -pdf
# Counting the number of pages from PDF:
NUM_PAGES=$(pdfinfo "${TEMP_DIR_PATH}/input.pdf" | awk '/^Pages:/ {print $2}')
REL_PAGE_WIDTH=$(python -c "print(1 / ${NUM_PAGES})")
PAGES_LIST=""
echo "Cropping each page based on its specific bounding box..."
for i in $(seq 1 $NUM_PAGES)
do
# Splitting current page:
pdfjam "${TEMP_DIR_PATH}/input.pdf" $i --outfile "${TEMP_DIR_PATH}/page_${i}-tmp.pdf"
# Fetching bounding box of current page:
PAGE_WIDTH=$(pdfinfo "${TEMP_DIR_PATH}/page_${i}-tmp.pdf" | awk '/^Page size:/ {print $3}')
BBOX=$(gs -dBATCH -dNOPAUSE -q -sDEVICE=bbox "${TEMP_DIR_PATH}/page_${i}-tmp.pdf" 2>&1 | awk '/^%%HiResBoundingBox:/ {print 0 " " $3 " " '${PAGE_WIDTH}' " " $5}')
# Removing content out of current page's bounding box:
PAGE_FILENAME="page_${i}"
PDF_FILEPATH="${TEMP_DIR_PATH}/${PAGE_FILENAME}.pdf"
PS_FILEPATH="${TEMP_DIR_PATH}/${PAGE_FILENAME}.ps"
gs -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -dCompatibilityLevel=1.5 -sOutputFile=$PDF_FILEPATH -c "[/CropBox [${BBOX}] /PAGES pdfmark" -f "${TEMP_DIR_PATH}/page_${i}-tmp.pdf"
PAGES_LIST="${PAGES_LIST}\n \\\includegraphics[width=${REL_PAGE_WIDTH}\\\textwidth]{${PDF_FILEPATH}} \\\\\\\ \\\vspace{-0.03cm}"
done
echo "Merging the 'n' pages into a single one using LaTeX..."
cp $PDF_MERGE_TEMPLATE_PATH "${TEMP_DIR_PATH}/merged.tex"
sed -i "s#${PDF_MERGE_TEMPLATE_PAGES_MACRO}#${PAGES_LIST}#g" "${TEMP_DIR_PATH}/merged.tex"
latex -halt-on-error -output-directory $TEMP_DIR_PATH "${TEMP_DIR_PATH}/merged.tex"
dvipdfm "${TEMP_DIR_PATH}/merged.dvi" -o "${TEMP_DIR_PATH}/merged.pdf"
echo "Finalizing the PDF and sending a copy to the destination directory..."
# Adding margins to the final PDF:
pdfcrop --margins 5 "${TEMP_DIR_PATH}/merged.pdf" "${TEMP_DIR_PATH}/output-tmp.pdf"
# Enlargement of the final PDF file to extract tables correctly using the "tabula-py" tool:
$CPDF_BIN_PATH -scale-page "10 10" "${TEMP_DIR_PATH}/output-tmp.pdf" -o "${TEMP_DIR_PATH}/output.pdf"
# Copying the pre-processed PDF file to the output path:
cp "${TEMP_DIR_PATH}/output.pdf" "${OUTPUT_FILEPATH}"
echo "Deleting temp files..."
rm -rf "${TEMP_DIR_PATH}"
Дайте разрешение на выполнение скрипта с помощью следующей команды:
chmod +x pdf-preprocessing.sh
Примеры использования:
Для предварительной обработки файла с именем
example.pdf, просто выполните следующую команду:
sh pdf-preprocessing.sh example.pdf preprocessed-example.pdf
Отредактируйте параметры скрипта в соответствии с вашим случаем. Координаты верхнего и нижнего колонтитула, например, будут зависеть от шаблона ваших файлов. Не стесняйтесь предлагать улучшения и упрощения.
Вариант — использоватьpdfxup.-o.. Выходной файл-x.. n столбцов на странице-y.. n строк на странице-fw 0..убрал бы рамку вокруг страниц
pdfxup -o out.pdf -x 4 -y 1 input.pdf

-l.. ландшафтный режим
pdfxup -o out.pdf -x 1 -y 4 -l 0 input.pdf
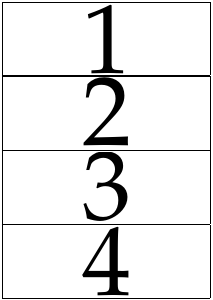
Создание строки страницы размером 2x2.
pdfxup -o out.pdf -x 2 -y 2 -l 0 input.pdf
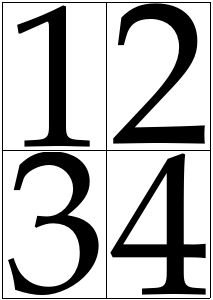
Разумное оформление страницы размером 2x2.
pdfxup -o out.pdf -x 2 -y 2 -l 0 -col input.pdf

Или используяpdfjam.
pdfjam --outfile out.pdf --nup 4x1 --landscape input.pdf
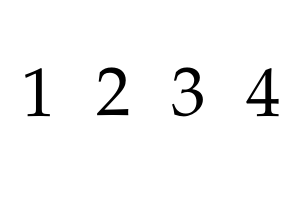
pdfjam --outfile out.pdf --nup 1x4 input.pdf

pdfjam --outfile out.pdf --nup 2x2 input.pdf
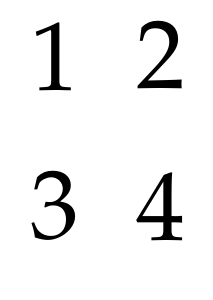
pdfjam --outfile out.pdf --nup 2x2 --column true input.pdf
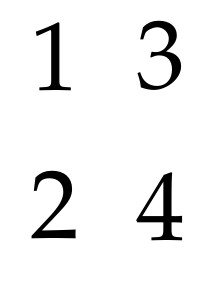
Латексный код для создания 4 страниц в формате PDF.
\documentclass{article}
\pagestyle{empty}
\begin{document}
\fontsize{\textheight}{\textheight}
\fontfamily{ppl}\selectfont
\centering
1\\2\\3\\4
\end{document}
Выходные данные PDF преобразуются в PNG с помощью
pdftoppm -singlefile -scale-to 300 out.pdf out -png